En la evolución de los servicios de búsqueda se pueden distinguir tres generaciones: En el inicio las listas de salida eran armadas en función de la relevancia del texto, es decir que si una página contenía texto buscado por el usuario era mostrada como resultado y el orden de la salida casi no tenía importancia. Luego en la segunda generación, aparte de la relevancia se empieza a ponderar el orden de los elementos del conjunto respuesta a una consulta en función de cuan importante es la página (valor obtenido a través de análisis de enlaces), un ejemplo es el buscador Google con su algoritmo Pagerank Actualmente, las nuevas tecnologías de búsqueda apuntan hacía: motores especializados en temas o áreas del conocimiento (Rollyo, Yahoo Search Builder), búsqueda social donde los usuarios a partir del concepto de comunidad compartan sus habilidades para construir un motor de mayor perfomance (Eurekster, Google Co-op), modelos económicos alternativos y participativos donde los generadores de contenidos puedan recibir parte de las ganancias generadas por publicidad (Gravee).
Eurekster [http://www.eurekster.com/] y su producto Swicki, que a diferencia de los buscadores tradicionales, va aprendiendo de las preferencias de búsqueda de los usuarios a medida que estos utilizan el sistema. Se basa en el concepto que lo que le gusta a un usuario también le gusta a otros usuarios con intereses comunes. Eurekster opera de forma similar a Amazon en su estrategia de sugerencias, utilizando filtros colaborativos asesora a un usuario sobre una determinada temática o estilo en base a lo que otros clientes del mismo segmento han elegido previamente.
Gravee [http://www.graave.com] es un buscador tradicional con algunas características propias. A medida que el usuaurio examina los resultados puede evaluarlos como positivos o negativos, tal información será tomada como recomendación para otros usuarios. Los sitios hallados pueden ser almacenados en una sección de favoritos. Los usuarios duenos de blogs pueden añadir en sus sitios interfaces de consulta con Gravee y recibir una recompensa económica por ello. Los generadores de contenido indexado por Gravee pueden tener un dinero a cambio de ellos. En Gravee se pretende cambiar compartir los ingresos publicitarios con los propietarios contenidos y aquellos que fomenten el uso del servicio.
Según la empresa Google su producto orientado a las búsquedas sociales “Co-op” [http://www.google.com/coop] es una infraestructura que le permite a sus usuarios utilizar sus conocimientos o experticia a los efectos de ayudar a pares a hallar información.
Su funcionamiento consiste en que los usuarios del buscador se pueden suscribirnos a fuentes importantes de información en diversas áreas del conocimiento. Los contenidos son etiquetados de manera que al realizar una consulta en las que hay contenido recomendado por las fuentes, se asocian etiquetas a los resultados con la finalidad de aportar más información para mejorar la precisión. Los usuarios registrados también pueden ser fuentes de información y etiquetar páginas web, de esta forma se convierten en proveedores de información con valor agregado. En este modelo, Google pretende que los usuarios expertos en un área del conocimiento etiqueten recursos y compartan sus búsquedas.
domingo, diciembre 31, 2006
off topic: Quiénes son los bárbaros?
Por más que Saddam sea un HP, asesino de a miles, dictador de última, basura de la humanidad, ... no merece que el "mundo civilizado" -lease clase gobernante y no pueblo de USA- lo mate y menos de esta forma.

pd: Cuidado que es fácil convertirse en lo que se combate.
pd: Cuidado que es fácil convertirse en lo que se combate.

sábado, diciembre 30, 2006
La sociedad de la información como fuente de empleos
leyendo una gacetilla de prensa del sitio de infojobs.net de España encuentro un dato que me pareció interesante. "Un tercio de los profesionales en busca de empleo son del sector de las tecnologías de la información".
A partir de información recolectada por esta empresa de servicios, sobre
3,4 millones de postulantes y empresas que demandan recursos humanos, se plantea que "el sector de las tecnologías de la información ha adquirido como generador de empleo y como destino laboral más deseado". Tal dato se resume a patir de los números que indican que 1 de cada 3 postulantes desea obtener un empleo relacionado con la sociedad de la información. Por otro lado se concluye que el primer trabajo profesional más deseado es el relacionado con la administración de empresas.
A partir de información recolectada por esta empresa de servicios, sobre
3,4 millones de postulantes y empresas que demandan recursos humanos, se plantea que "el sector de las tecnologías de la información ha adquirido como generador de empleo y como destino laboral más deseado". Tal dato se resume a patir de los números que indican que 1 de cada 3 postulantes desea obtener un empleo relacionado con la sociedad de la información. Por otro lado se concluye que el primer trabajo profesional más deseado es el relacionado con la administración de empresas.
viernes, diciembre 29, 2006
martes, diciembre 26, 2006
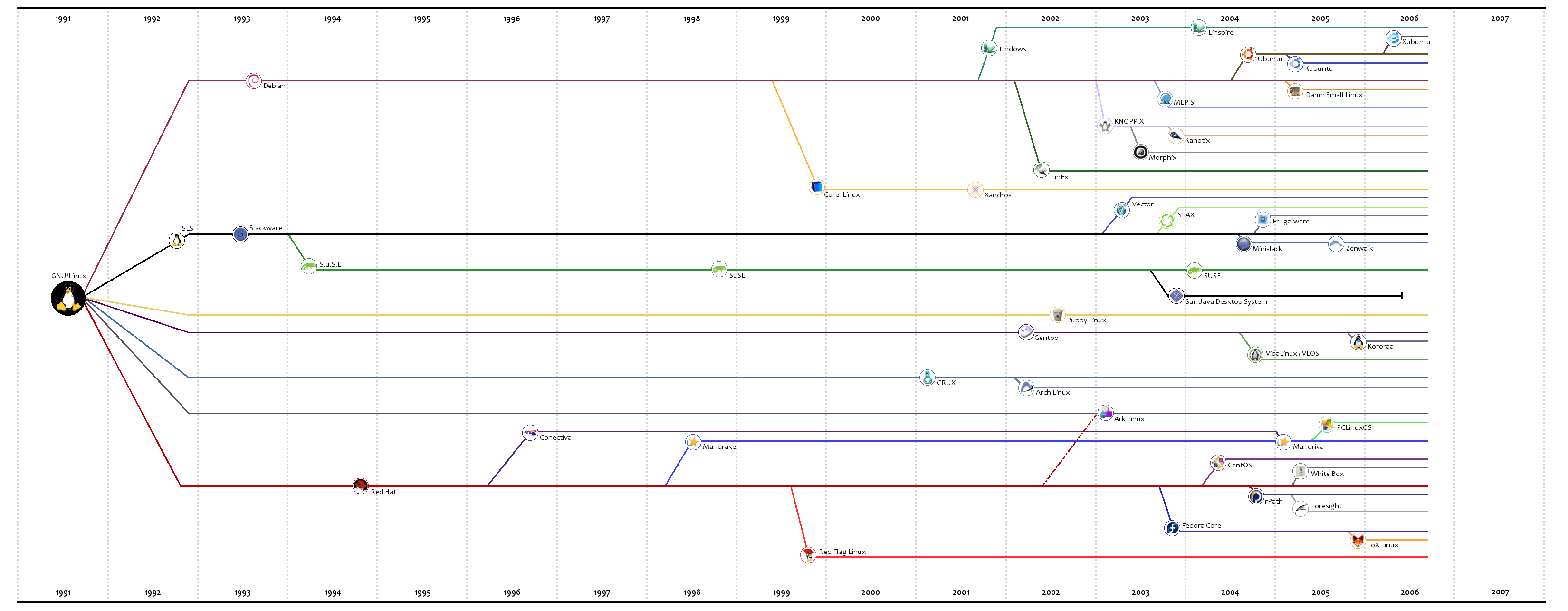
Listado de WebOS
En el blog franticindustries hay una página donde presentan de forma sintética 10 sistemas operativos para la web (webOS, según el artículo, es un sistema operativo virtual que se ejecuta sobre un explorador).
107 gigabits por segundo
leyendo el país.com hallo una noticia que comenta que la firma Siemens ha logrado transmitir soobre un canal de fibra óptica de 160 kms a una velocidad de 107 Gbps.
domingo, diciembre 24, 2006
Informe ITU "Digital Life 2006"
La ITU (Unión Internacional de Telecomunicaciones) ha presentado su informe "Digital Life 2006" anual sobre el estado de las comunicaciones. Como principal conclusión se pudo establecer que en la actualidad los medios digitales han desplazado en intensidad de uso que a los tradicionales (radio, TV, diarios, etc). Otro hallazgo se da con las comunicaciones móviles, dado que explican que en solo 21 años la telefonía móvil alcanzó la cantidad de líneas qu a la telefonía fija le llevaron 125 años de crecimiento. Como dato particular se tiene que en los últimos tres años se sumaron otros 1000 millones de números móviles (se está cerca de los 3000 millones de líneas en el mundo).
También se hace notar que ha habido un importante crecimiento en el ancho de banda que disponen los usuarios. S e plantea que en planeta existen 216 millones de usuarios debanda ancha por línea fija y 61 millones por líneas móviles de 3ra generación. Lo impresionante se da en China donde existen hoy 393 millones de celulares al cual le sigue el super país ejemplo de consumo USA con 201 millones.
También se hace notar que ha habido un importante crecimiento en el ancho de banda que disponen los usuarios. S e plantea que en planeta existen 216 millones de usuarios debanda ancha por línea fija y 61 millones por líneas móviles de 3ra generación. Lo impresionante se da en China donde existen hoy 393 millones de celulares al cual le sigue el super país ejemplo de consumo USA con 201 millones.
Voy a ver si en los próximos días preparo un post con sus tablas y gráficos a los efectos de expandir esta información. .
Versión completa del informe Digital Life
Vía: pais.com
viernes, diciembre 22, 2006

jueves, diciembre 21, 2006
Evaluación de los Sistemas de recuperación de información - 2da Parte
Partes del libro que he escrito con Gabriel Tolosa, titulado “Introducción a la Recuperación de Información”
Evaluación de los Sistemas de recuperación de información - 2da Parte
(Ir a la 1er parte)
Evaluación de los Sistemas de recuperación de información - 2da Parte
(Ir a la 1er parte)
Para analizar estas medidas planteamos el siguiente ejemplo: Existe una colección D la cual posee 100 documentos, digamos:
D = {d1, d2, d3, d4, d5,…,d98, d99, d100}
Ahora, supóngase que para una consulta q existen 10 documentos relevantes, R:
R = {d2, d45, d70, d77, d79, d81, d82, d88, d90, d91}
A pedido del usuario, el sistema entregó los primeros 12 documentos, A, rankeados de la siguiente forma:
A = {d79, d10, d90, d13, d20, d45, d60, d30, d77, d21, d88, d100}
(se han resaltado los documentos pertenecientes a R, es decir, los relevantes)
Los cálculos de performance de la recuperación para un tamaño de respuesta de 12 documentos resultan:
P = 5 / 12 = 0.42
E = 5 / 10 = 0.50
Sin embargo, se puede modificar el tamaño de la respuesta a los efectos de intentar recuperar más documentos relevantes, es decir, para aumentar la exhaustividad. En tal caso, supóngase una nueva respuesta – a la misma consulta – consistente de 16 documentos, A’:
A’ = {d79, d10, d90, d13, d20, d45, d60, d30, d77, d21, d88, d100, d1, d91, d29, d10}
Entonces, resulta:
P = 6 / 16 = 0.38
E = 6 / 10 = 0.60
Y luego, se solicita una nueva respuesta, pero ahora el tamaño de la lista consiste de 20 documentos, A’’:
A’’ = {d79, d10, d90, d13, d20, d45, d60, d30, d77, d21, d88, d100, d1, d91, d29, d11, d81, d2, d70, d82}
Los nuevos valores para P y E son:
P = 10 / 20 = 0.50
E = 10 / 10 = 1.00
Como se vio anteriormente, es posible evaluar la performance de un sistema bajo distintas situaciones. En nuestro caso particular hemos analizado la efectividad de un mismo sistema para una misma consulta sobre una misma colección para tres tamaños del conjunto de respuestas (12, 16 y 20).
miércoles, diciembre 20, 2006
La divulgación de la ciencia y su lugar en la era de las redes sociales
La revista Mi+d publicó un artículo de Antonio Lafuente titulado "Ciencia 2.0" . Es un buen inicio para un debate, dado que Antonio resume su posición bajo la ecuación "ciencia + transparencia = ciencia 2.0".
La discusión se da en torno a que hay que adaptar la formas de divulgación del conocimiento científico, afín de darle un dinamismo acorde a la generación actual del mismo.De alguna manera, éste artículo está en la línea crítica de los protocolos tradicionales de publicación.
Gracias por el dato Tiscar
La discusión se da en torno a que hay que adaptar la formas de divulgación del conocimiento científico, afín de darle un dinamismo acorde a la generación actual del mismo.De alguna manera, éste artículo está en la línea crítica de los protocolos tradicionales de publicación.
Gracias por el dato Tiscar
Firefox crece en uso
Vía BitperBit me entero que Firefox ya es usado un 25% de los usarios (datos de W3C de diciembre 2006). Internet Explorer x.0 por un 65 % y Opera (el que uso) por un 1%.
martes, diciembre 19, 2006
Me gustó lo de blogfesor
En una nota de Clarín "¿Quién le enseña a quién?", firmada por María Farber, encontré una visión particular sobre el uso de elementos de tecnología educativa.
Lo que me interesa compartir son pensamiento de Mario Nuñez Molina, el entrevistado, sobre lo que considera como el "blogfesor", aquí van:
"- El Blogfesor está orientado hacia la interacción, la participación y las redes sociales en el ciberespacio.
- Se beneficia de la inteligencia colectiva mediante servicios como Delicious, Furl, Flickr, Blinklist, entre otros.
- Considera que sus canales de RSS son herramientas de educación continua.
- Cree que toda persona es un experto sobre algún tema.
- Prefiere utilizar aplicaciones y programas libres.
- Es un "prosumidor". No sólo es un "consumidor"de la información sino que también la genera.
- Considera que lo más importante no es memorizar cómo se hacen las cosas, sino saber dónde puede conseguir la información que necesita en determinado momento.
- Sus aportaciones están bajo licencia de creative commons o copyleft.
- Pasa gran parte del tiempo clasificando lo que aprende o necesita aprender mediante etiquetas o tags.
- En vez de regirse por la ética de la competencia, se rige por la ética de la colaboración y la sinergia."
Lo que me interesa compartir son pensamiento de Mario Nuñez Molina, el entrevistado, sobre lo que considera como el "blogfesor", aquí van:
"- El Blogfesor está orientado hacia la interacción, la participación y las redes sociales en el ciberespacio.
- Se beneficia de la inteligencia colectiva mediante servicios como Delicious, Furl, Flickr, Blinklist, entre otros.
- Considera que sus canales de RSS son herramientas de educación continua.
- Cree que toda persona es un experto sobre algún tema.
- Prefiere utilizar aplicaciones y programas libres.
- Es un "prosumidor". No sólo es un "consumidor"de la información sino que también la genera.
- Considera que lo más importante no es memorizar cómo se hacen las cosas, sino saber dónde puede conseguir la información que necesita en determinado momento.
- Sus aportaciones están bajo licencia de creative commons o copyleft.
- Pasa gran parte del tiempo clasificando lo que aprende o necesita aprender mediante etiquetas o tags.
- En vez de regirse por la ética de la competencia, se rige por la ética de la colaboración y la sinergia."
Librería para el análisis de redes sociales
libSNA (Social Network Analysis) es una librería de soft destinada al análisis de las redes sociales. Esta apasionante temática, hoy considerada por The Times como el fenómeno del año 2006, utiliza elementos matemáticos (algebra y teoría de grafos basicamente) para tratar de modelar y entender relaciones entre individuos u organizaciones.
Para aquellos que le interese el tema, recomiendo empezar a leer una introducción por Juán Merelo Guervós
Para aquellos que le interese el tema, recomiendo empezar a leer una introducción por Juán Merelo Guervós
lunes, diciembre 18, 2006
Serie de artículos sobre evolución de la web
En el blog Robin Good se halla la traducción de tres artículos sobre evolución de los servicios web. Los autores Josef Kolbitsch y Hermann Maurer y el material fue originalmente publicado en inglés en el Journal of Unkiversal Computer Science.
Blogs, Wikis, Podcasting, Redes Sociales, Compartir Archivos: Como La Web Se Está Transformando A Si Misma - Parte I
Introducción A Blogs - Como La Web Se Está Transformando A Si Misma - Parte II
Introducción A Wikis: Como La Web Se Está Transformando A Si Misma - Parte III
Blogs, Wikis, Podcasting, Redes Sociales, Compartir Archivos: Como La Web Se Está Transformando A Si Misma - Parte I
Introducción A Blogs - Como La Web Se Está Transformando A Si Misma - Parte II
Introducción A Wikis: Como La Web Se Está Transformando A Si Misma - Parte III

domingo, diciembre 17, 2006
Esquemas y queries para manejar etiquetas.
Estos días estuve mirando las distintas ofertas que existen en agregadores, dado que tengo en mente un proyecto relacionado con integrar distintas fuentes de información sobre educación en español. En la exploración me topé con un artículo de Philipp Keller que expone distintas estrategias de esquemas de base de datos para trabajar con etiquetas. Como me pareció bueno lo comparto.
sábado, diciembre 16, 2006
Off Topic: Investigación sobre que piensa nuestra juventud
Reenvío una sugerencia de Pablo Mancini que apunta a un artículo de la BBC "Generación Futuro: Dos mil millones de personas en el mundo tienen menos de 18 años. ¿Qué piensan?". Es sorprendente algunos pensamientos generales que se revelan en el informe, me gusto el optimismo, ojalá no estén equivocados y el tonto sea uno. Les paso algunas partes:
Se entrevistaron a 3.050 jóvenes de Londres, Nueva York, Rio de Janeiro, Lagos, Nairobi, Moscú, El Cairo, Bagdad, Delhi y Yakarta.
"Sólo 14% cree que la "guerra contra el terror" está haciendo del mundo un lugar más seguro
Los jóvenes se muestran decididamente a favor de la inmigración: 4 de cada 5 creen que la gente debería poder elegir el país donde vivir, y dos tercios de aquellos encuestados creen que emigrarían para asegurarse un futuro mejor.
Tres cuartos de los jóvenes creen que su educación los ha preparado para el futuro, pero casi el mismo número está preocupado por conseguir un trabajo decente."
El dato que viene me impactó
"En términos de honestidad, son los jóvenes de Bagdad quienes se llevan las mejores calificaciones, comparados con sus coetáneos de ciudades como Londres.
Sólo un 2% de los iraquíes dijeron estar dispuestos a cometer un crimen para trasnformarse en millonarios de manera instantánea, mientras que un 3% admitió que robarían algo que deseen mucho y que no pueden costear.
En Londres, 31% cometería un crimen para ser millonario, y 15% robaría un objeto de su deseo."
Por último
"Al mismo tiempo, casi todos (96%) los jóvenes brasileros encuestados dijeron que creen en un Dios, y la mayoría (84%) dijeron que la religión es una fuente de bien."
Qué paso con el comunismo y la liberación espiritual del hombre?
Se entrevistaron a 3.050 jóvenes de Londres, Nueva York, Rio de Janeiro, Lagos, Nairobi, Moscú, El Cairo, Bagdad, Delhi y Yakarta.
"Sólo 14% cree que la "guerra contra el terror" está haciendo del mundo un lugar más seguro
Los jóvenes se muestran decididamente a favor de la inmigración: 4 de cada 5 creen que la gente debería poder elegir el país donde vivir, y dos tercios de aquellos encuestados creen que emigrarían para asegurarse un futuro mejor.
Tres cuartos de los jóvenes creen que su educación los ha preparado para el futuro, pero casi el mismo número está preocupado por conseguir un trabajo decente."
El dato que viene me impactó
"En términos de honestidad, son los jóvenes de Bagdad quienes se llevan las mejores calificaciones, comparados con sus coetáneos de ciudades como Londres.
Sólo un 2% de los iraquíes dijeron estar dispuestos a cometer un crimen para trasnformarse en millonarios de manera instantánea, mientras que un 3% admitió que robarían algo que deseen mucho y que no pueden costear.
En Londres, 31% cometería un crimen para ser millonario, y 15% robaría un objeto de su deseo."
Por último
"Al mismo tiempo, casi todos (96%) los jóvenes brasileros encuestados dijeron que creen en un Dios, y la mayoría (84%) dijeron que la religión es una fuente de bien."
Qué paso con el comunismo y la liberación espiritual del hombre?
Usuarios registrados en sistemas sociales
Los núneros cantan
Sourceforge: 130,155 proyectos registrados y 1,398,099 usuarios registrados(26/9)
Technorati: 55 millones de weblogs
FeedBurner: 23,188,852 suscripciones y 248,103 de fuentes ( 9/18/06).
Flickr: 3.500.000 usuarios registrados que subieron más de 230 millones de fotos. ( 09/06)
del.icio.us: 1,000,000 de usuarios registrados (09/2006)
Sourceforge: 130,155 proyectos registrados y 1,398,099 usuarios registrados(26/9)
Technorati: 55 millones de weblogs
FeedBurner: 23,188,852 suscripciones y 248,103 de fuentes ( 9/18/06).
Flickr: 3.500.000 usuarios registrados que subieron más de 230 millones de fotos. ( 09/06)
del.icio.us: 1,000,000 de usuarios registrados (09/2006)
ALTO: lectura obligatoria para informáticos
Vía Sentido Web me llega la noticia que hay un ebook, disponible para descarga, de tres "admirables monstruos de la programación". La obra Algorithms de Dasgupta, Papadimitriou y Vazirani está disponible para su consulta en este enlace.
jueves, diciembre 14, 2006
Internet 2 en Argentina: Otra mancha más al tigre
Como era de esperar quedamos afuera, no estoy hablando del mundial, ni de boca, ni de un caso de supuesto estímulo por drogas, ni que no nos dieron el premio Oscar. Sino de algo un poco menos "popular", hablo acerca de que alguien en el gobierno argentino "se olvido" de pagar, garpar, abonar la contraparte para seguir teniendo servicio de Internet 2 en el país. Por esta razón en una asamblea de la Cooperación Latinoamericana en Redes Avanzadas (CLARA) se decidió que el país fuera desconectado de las Redes Académicas y Científicas de Prestaciones Avanzadas.
Fuente; Prensa UNL
Pd: perdón por la noticia, pero tanta improvisación continua cansa.
Fuente; Prensa UNL
Pd: perdón por la noticia, pero tanta improvisación continua cansa.
miércoles, diciembre 13, 2006
Estado de conectividad en América
El Dr. Gilberto Paez, reconocido investigador del CATIE, me ha enviado un estudio propio donde se muestra el estado de conectividad de los países de américa, medido en cantidad de usuarios conectados a Internet por cada mil habitantes.


martes, diciembre 12, 2006
Formación en matemáticas, un problema que se repite
Gracias a Digizen me topé con un artículo "Miedo a las Matemáticas" de consumer.es que aborda el problema de la enseñanza de las matemáticas en la educación inicial y secundaria en España. La autora, Azucena García, entre las principales causas de este grave problema indica que es "la metodología de enseñanza, la falta de motivación, el currículo y la actitud del alumnado". Me parece que la contribución más importante del artículo, mas halla de crear conciencia, es la parte que indica que los padres no deben ser observadores anónimos de este problema.
Estudio sobre uso diario de servicios de Internet en USA
La organización Pew Internet & American Life Project, dedicada a realizar estudios de opinión pública, presentó una tabla que indica el uso diario (en porcentaje sobre el total de usuarios del país) de distintos servicios de Internet. La primer columna representa la actividad, la segunda el % de usuarios que el día de ayer a la encuesta respondieron afirmativamente y la tercer columna la fecha de captura de datos.

En otra página de Pew Internet pueden acceder al mismo tipo de datos, pero donde la pregunta es “si alguna vez el usuario realizó tal actividad”.

En otra página de Pew Internet pueden acceder al mismo tipo de datos, pero donde la pregunta es “si alguna vez el usuario realizó tal actividad”.
lunes, diciembre 11, 2006
Off Topic: Diagrama de flujo para aprobar un examen
A alguien en algún examen le sobro el tiempo y plasmó su experiencia en el siguiente diagrama de flujo.

Argentina, qué nos está pasando?
Revisando el ranking mundial de universidadesen la Web encuentro, para mi espantosa sorpresa, que la primer entrada de argentina, que corresponde a la UBA, ocupa el puesto 376. Qué nos está pasando?
El ranking es un proyecto del Laboratorio de Internet (CINDOC-CSIC) que mediante técnicas cuantitativas intenta ponderar la importancia de las instituciones en base a enlaces hacía ellas. Para una mayor explicación acerca de este modelo de evaluación acudan a este enlace.
El ranking es un proyecto del Laboratorio de Internet (CINDOC-CSIC) que mediante técnicas cuantitativas intenta ponderar la importancia de las instituciones en base a enlaces hacía ellas. Para una mayor explicación acerca de este modelo de evaluación acudan a este enlace.
domingo, diciembre 10, 2006
Hitwise muestra como disputan el mercado Yahoo y Google
La consultora Hitwise ha armado un gráfico en el cual muestra como las empresas Yahoo y Google se han comportado en el tiempo, esto visto a partir del análisis de visitas a los 20 principales servicios de cada una. Acutalmente se observa una tendencia de crecimiento en Yahoo e inversa en Google, algunos ya hasta andan prediciendo una intercepción en algún mes del 2007.

Por otro lado, Hitwise presenta una tabla comparativa de como internamente, en cada empresa, se reparten sus servicios basada en cantidad de visitas a cada uno.

Por otro lado, Hitwise presenta una tabla comparativa de como internamente, en cada empresa, se reparten sus servicios basada en cantidad de visitas a cada uno.
Los10 términos más utilizados en consultas
La consultora Hitwise presentó el ranking de los 10 términos más utilizados en consultas por parte de instituciones educativas en octubre del 2006:
Posición - Término - Volumen
1. dictionary 0.67%
2. wikipedia 0.54%
3. dictionary.com 0.17%
4. thesaurus 0.10%
5. quotes 0.09%
6. online dictionary 0.09%
7. spanish dictionary 0.07%
8. fafsa 0.06%
9. christopher columbus 0.05%
10. encyclopedia 0.05%
Posición - Término - Volumen
1. dictionary 0.67%
2. wikipedia 0.54%
3. dictionary.com 0.17%
4. thesaurus 0.10%
5. quotes 0.09%
6. online dictionary 0.09%
7. spanish dictionary 0.07%
8. fafsa 0.06%
9. christopher columbus 0.05%
10. encyclopedia 0.05%
sábado, diciembre 09, 2006
Evaluación de los sistemas de recuperación de información
Continuo con la idea de presentar algunas partes del libro que he escrito con Gabriel Tolosa, titulado “Introducción a la Recuperación de Información”
Evaluación de los sistemas de recuperación de información - 1ra Parte
Como hemos mencionado en el capítulo anterior, existen diferentes aproximaciones para resolver el problema central del área de RI. De aquí que contamos con sistemas basados en diferentes modelos y algoritmos, los cuales – como todo sistema – deben poder ser evaluados bajo ciertos criterios. Esta tarea permite medir los parámetros de funcionamiento que valoran al sistema y – además – posibilitan la comparación entre distintos SRI.
En sistemas tradicionales – como los de recuperación de datos – los parámetros típicos de evaluación son tiempo y espacio. La medición del tiempo de respuesta y de la cantidad de espacio de almacenamiento que el sistema utiliza brindan parámetros concretos y relativamente fáciles de medir. Mientras un sistema responda más velozmente y requiera menos almacenamiento, mejor será. El balance entre estos dos parámetros depende de los objetivos de diseño del sistema. Por ejemplo, si el requerimiento mayor corresponde a la velocidad del sistema para entregar respuestas porque con éstas se toman decisiones en tiempo real, no importará demasiado la cantidad de estructuras de datos que se van a implementar y que permitirán acelerar las búsquedas. Por el contrario, si el sistema va a correr sobre una PDA, el espacio de almacenamiento es muy importante y – tal vez – se pueda “esperar” un poco más por la respuesta.
Sin embargo, la evaluación de un sistema de RI no es una tarea sencilla. Debido a que el conjunto de respuesta no es exacto se requiere ponderar cómo éste se ajusta a la consulta y – peor aún – ésta a la necesidad de información del usuario. Aquí aparecen las cuestiones subjetivas que se plantean al especificar un query, al adoptar una representación lógica de los documentos de la colección y al utilizar una función de ranking determinada.
Por lo tanto, la evaluación más común se orienta a determinar cuán preciso es el conjunto respuesta a partir del concepto de relevancia. Para Baeza-Yates [2] este tipo de evaluación corresponde a la evaluación de la performance de la recuperación. En el mismo sentido, van Risbergen [61] plantea medir la efectividad del sistema de recuperación, la cual cuantifica su capacidad para recuperar documentos relevantes mientras no recupera documentos no relevantes. Un sistema más efectivo permite satisfacer en mayor medida la necesidad de un usuario.
2.1 – Medidas de Evaluación
Desde los primeros esfuerzos relacionados con la evaluación de los SRI hasta la actualidad, la aproximación clásica para describir la performance de la recuperación consiste en determinar cuántos documentos relevantes se recuperaron y cómo se rankearon para entregarlos al usuario.
Cuando un usuario plantea un query a un SRI, obtiene como respuesta una lista de documentos de acuerdo a un ranking determinado por el sistema. Como ya hemos mencionado, dicha respuesta está formada por documentos relevantes y otros que no lo son y la lista – generalmente – no contiene todos los documentos de la colección (en colecciones grandes, sería imposible de revisar toda la respuesta). En el gráfico 1 se muestra esta situación. Dada una consulta cualquiera, un SRI recuperará el grupo identificado como C, de los cuales solo una parte son relevantes (D).

A partir de esta situación, se puede establecer la tabla de contingencia anterior para la evaluación.Existen dos medidas ampliamente aceptadas en la comunidad de RI denominadas Precisión (en inglés, Precision) y Exhaustividad (Recall) planteadas por Cleverdon [13] hace varios años. La Exhaustividad se define como la proporción de los documentos relevantes que han sido recuperados y permite evaluar la habilidad del sistema para encontrar todos los documentos relevantes de la colección. Tal concepto podría resumirse a partir de la siguiente cuestión “¿Son todos los que están o nos faltan algunos?”.
La Precisión se define como la proporción de los documentos recuperados que son relevantes y permite evaluar la habilidad del sistema para rankear primero la mayoría de los documentos relevantes. Expresado en forma de pregunta: ¿Son todos relevantes o se “filtraron” algunos que no lo son?
Estas dos medidas se encuentran altamente relacionadas. Empíricamente se ha comprobado que una alta exhaustividad se acompaña de una muy baja precisión y viceversa (Gráfico 2), es decir, existe una relación inversa entre las [14].

Existe un compromiso entre Exhaustividad y Precisión, es decir, al aumentar la Exhaustividad recuperando mayor cantidad de documentos, veremos disminuir la Precisión. Esto se explica en el hecho – ya mencionado – que la salida de un SRI es un conjunto aproximado (no exacto) y – por lo tanto – entre ésta se encontrarán documentos no relevantes. Por el contrario, si recuperamos unos pocos documentos y todos son relevantes se tendrá una precisión máxima, pero seguramente se están perdiendo documentos útiles por no ser recuperados. El sistema ideal es aquel que siempre recupera todos los documentos relevantes y solo esos, situación que – hasta el momento – no existe.
Referencias
[2] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[13] Cleverdon, C.W., Mills, J. Y Keen, M. “Factors Determining the Performance of Indexing Systems”. ASLIB Cranfield Project. Vol. 1, Design, Vol2, Test Results. 1966.
[14] Cleverdon, C.W. “On the inverse relationship of recall and precision”. Journal of Documentation, vol. 28, págs. 195-201. 1972.
[61] van Rijsbergen, C.J. “Information Retrieval”. Department of Computing Science. University of Glasgow. 1979.
Evaluación de los sistemas de recuperación de información - 1ra Parte
Como hemos mencionado en el capítulo anterior, existen diferentes aproximaciones para resolver el problema central del área de RI. De aquí que contamos con sistemas basados en diferentes modelos y algoritmos, los cuales – como todo sistema – deben poder ser evaluados bajo ciertos criterios. Esta tarea permite medir los parámetros de funcionamiento que valoran al sistema y – además – posibilitan la comparación entre distintos SRI.
En sistemas tradicionales – como los de recuperación de datos – los parámetros típicos de evaluación son tiempo y espacio. La medición del tiempo de respuesta y de la cantidad de espacio de almacenamiento que el sistema utiliza brindan parámetros concretos y relativamente fáciles de medir. Mientras un sistema responda más velozmente y requiera menos almacenamiento, mejor será. El balance entre estos dos parámetros depende de los objetivos de diseño del sistema. Por ejemplo, si el requerimiento mayor corresponde a la velocidad del sistema para entregar respuestas porque con éstas se toman decisiones en tiempo real, no importará demasiado la cantidad de estructuras de datos que se van a implementar y que permitirán acelerar las búsquedas. Por el contrario, si el sistema va a correr sobre una PDA, el espacio de almacenamiento es muy importante y – tal vez – se pueda “esperar” un poco más por la respuesta.
Sin embargo, la evaluación de un sistema de RI no es una tarea sencilla. Debido a que el conjunto de respuesta no es exacto se requiere ponderar cómo éste se ajusta a la consulta y – peor aún – ésta a la necesidad de información del usuario. Aquí aparecen las cuestiones subjetivas que se plantean al especificar un query, al adoptar una representación lógica de los documentos de la colección y al utilizar una función de ranking determinada.
Por lo tanto, la evaluación más común se orienta a determinar cuán preciso es el conjunto respuesta a partir del concepto de relevancia. Para Baeza-Yates [2] este tipo de evaluación corresponde a la evaluación de la performance de la recuperación. En el mismo sentido, van Risbergen [61] plantea medir la efectividad del sistema de recuperación, la cual cuantifica su capacidad para recuperar documentos relevantes mientras no recupera documentos no relevantes. Un sistema más efectivo permite satisfacer en mayor medida la necesidad de un usuario.
2.1 – Medidas de Evaluación
Desde los primeros esfuerzos relacionados con la evaluación de los SRI hasta la actualidad, la aproximación clásica para describir la performance de la recuperación consiste en determinar cuántos documentos relevantes se recuperaron y cómo se rankearon para entregarlos al usuario.
Cuando un usuario plantea un query a un SRI, obtiene como respuesta una lista de documentos de acuerdo a un ranking determinado por el sistema. Como ya hemos mencionado, dicha respuesta está formada por documentos relevantes y otros que no lo son y la lista – generalmente – no contiene todos los documentos de la colección (en colecciones grandes, sería imposible de revisar toda la respuesta). En el gráfico 1 se muestra esta situación. Dada una consulta cualquiera, un SRI recuperará el grupo identificado como C, de los cuales solo una parte son relevantes (D).

A partir de esta situación, se puede establecer la tabla de contingencia anterior para la evaluación.Existen dos medidas ampliamente aceptadas en la comunidad de RI denominadas Precisión (en inglés, Precision) y Exhaustividad (Recall) planteadas por Cleverdon [13] hace varios años. La Exhaustividad se define como la proporción de los documentos relevantes que han sido recuperados y permite evaluar la habilidad del sistema para encontrar todos los documentos relevantes de la colección. Tal concepto podría resumirse a partir de la siguiente cuestión “¿Son todos los que están o nos faltan algunos?”.
La Precisión se define como la proporción de los documentos recuperados que son relevantes y permite evaluar la habilidad del sistema para rankear primero la mayoría de los documentos relevantes. Expresado en forma de pregunta: ¿Son todos relevantes o se “filtraron” algunos que no lo son?
Estas dos medidas se encuentran altamente relacionadas. Empíricamente se ha comprobado que una alta exhaustividad se acompaña de una muy baja precisión y viceversa (Gráfico 2), es decir, existe una relación inversa entre las [14].

Existe un compromiso entre Exhaustividad y Precisión, es decir, al aumentar la Exhaustividad recuperando mayor cantidad de documentos, veremos disminuir la Precisión. Esto se explica en el hecho – ya mencionado – que la salida de un SRI es un conjunto aproximado (no exacto) y – por lo tanto – entre ésta se encontrarán documentos no relevantes. Por el contrario, si recuperamos unos pocos documentos y todos son relevantes se tendrá una precisión máxima, pero seguramente se están perdiendo documentos útiles por no ser recuperados. El sistema ideal es aquel que siempre recupera todos los documentos relevantes y solo esos, situación que – hasta el momento – no existe.
Referencias
[2] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[13] Cleverdon, C.W., Mills, J. Y Keen, M. “Factors Determining the Performance of Indexing Systems”. ASLIB Cranfield Project. Vol. 1, Design, Vol2, Test Results. 1966.
[14] Cleverdon, C.W. “On the inverse relationship of recall and precision”. Journal of Documentation, vol. 28, págs. 195-201. 1972.
[61] van Rijsbergen, C.J. “Information Retrieval”. Department of Computing Science. University of Glasgow. 1979.
jueves, diciembre 07, 2006
Blogs sobre “blogs, semántica y geolocalización”
Geospatial Semantic Web Blog es el nombre de un blog que trata exclusivamente el como incorporar referencias geográficas a aplicaciones. En particular recomiendo leer el artículo titulado “Geotagged blogs are rare in the blogosphere” en él se describe la problemática de georeferenciar entradas en blogs.
martes, diciembre 05, 2006
Caracterización del acceso a Internet en escuelas públicas de USA
"Internet Access in U.S. Public Schools and Classrooms: 1994-2005" es el nombre de un trabajo de investigación que trata de caracterizar como es el acceso a Internet en las mencionadas escuelas públicas de USA. Se presentan tecnologías, tasas de uso, tipos de conexiones, normas y soft utilizado para evitar el acceso a sitios no autorizados. Más allá de los aspectos tecnológicos enunciados el informe también contiene datos acerca de la integración de servicios de red a la curricula educativa.
Las distintas inteligencias
Leyendo Wikipedia encontré una entrada que hace referencia a una teoría que indica que el ser humano posee inteligencias múltiples. Esto lo formalizó un investigador americano llamado Gardner, donde su hipótesis de trabajo es que la inteligencia no es una, sino que son varias e independientes entre si, pero que interactúan. Para el investigador, la definición de inteligencia se da como "la capacidad de resolver problemas o elaborar productos que sean valiosos en una o más culturas".
De la página mencionada extraigo las nueve inteligencias definidas por Howard Gardner :
Inteligencia lingüística, la que tienen los escritores, los poetas, los buenos redactores. Utiliza ambos hemisferios.
Inteligencia lógica-matemática, la que utilizamos para resolver problemas de lógica y matemáticas. Es la inteligencia que tienen los científicos. Se corresponde con el modo de pensamiento del hemisferio lógico y con lo que nuestra cultura ha considerado siempre como la única inteligencia.
Inteligencia espacial, consiste en formar un modelo mental del mundo en tres dimensiones, es la inteligencia que tienen los marineros, los ingenieros, los cirujanos, los escultores, los arquitectos, o los decoradores.
Inteligencia musical, es naturalmente la de los cantantes, compositores, músicos, bailarines.
Inteligencia corporal-cinestésica, o la capacidad de utilizar el propio cuerpo para realizar actividades o resolver problemas. Es la inteligencia de los deportistas, los artesanos, los cirujanos y los bailarines.
Inteligencia Intrapersonal, es la que nos permite entendernos a nosotros mismos. No está asociada a ninguna actividad concreta.
Inteligencia interpersonal, la que nos permite entender a los demás, y la solemos encontrar en los buenos vendedores, políticos, profesores o terapeutas.
Inteligencia emocional es formada por la inteligencia intrapersonal y la interpersonal y juntas determinan nuestra capacidad de dirigir nuestra propia vida de manera satisfactoria.
Inteligencia Naturalista, la que utilizamos cuando observamos y estudiamos la naturaleza. Es la que demuestran los biólogos o los herbolarios.
Me gusta esta teoría, es flexible y hasta me parece natural (no forzada).
De la página mencionada extraigo las nueve inteligencias definidas por Howard Gardner :
Inteligencia lingüística, la que tienen los escritores, los poetas, los buenos redactores. Utiliza ambos hemisferios.
Inteligencia lógica-matemática, la que utilizamos para resolver problemas de lógica y matemáticas. Es la inteligencia que tienen los científicos. Se corresponde con el modo de pensamiento del hemisferio lógico y con lo que nuestra cultura ha considerado siempre como la única inteligencia.
Inteligencia espacial, consiste en formar un modelo mental del mundo en tres dimensiones, es la inteligencia que tienen los marineros, los ingenieros, los cirujanos, los escultores, los arquitectos, o los decoradores.
Inteligencia musical, es naturalmente la de los cantantes, compositores, músicos, bailarines.
Inteligencia corporal-cinestésica, o la capacidad de utilizar el propio cuerpo para realizar actividades o resolver problemas. Es la inteligencia de los deportistas, los artesanos, los cirujanos y los bailarines.
Inteligencia Intrapersonal, es la que nos permite entendernos a nosotros mismos. No está asociada a ninguna actividad concreta.
Inteligencia interpersonal, la que nos permite entender a los demás, y la solemos encontrar en los buenos vendedores, políticos, profesores o terapeutas.
Inteligencia emocional es formada por la inteligencia intrapersonal y la interpersonal y juntas determinan nuestra capacidad de dirigir nuestra propia vida de manera satisfactoria.
Inteligencia Naturalista, la que utilizamos cuando observamos y estudiamos la naturaleza. Es la que demuestran los biólogos o los herbolarios.
Me gusta esta teoría, es flexible y hasta me parece natural (no forzada).
lunes, diciembre 04, 2006
Enciclopedia de Matemáticas PlanetMath
PlanetMath es un proyecto mantenido por una comunidad de gente que desea que el conocimiento matemático sea fácilmente accesible. En noviembre del año 2006 se contabilizaron más de 5.600 entradas y 9.400 conceptos. EL material, el cual está compuesto de artículos y libros, documentos de investigación se encuentra regulado por la licencia GNU/FDL (Free Documentation License. LaTeX es la herramienta seleccionada para escribir en lenguaje matemático. Una carácterística particular es que siempre hay una imagen de la enciclopedia lista para descargarse y utilizarse fuera de línea.
domingo, diciembre 03, 2006

Con Uds. FeedRaider
El servicio web FeedRaider es un agregador de canales RSS, donde un usuario puede crear rápidamente una interface pública que contenga los canales preferidos por él. Los invito a visitar el mio, lo hice exportando en formato OPML los canales de mi FeedReader. Esta aplicación es complementaria a los lectores de escritorio, dado que permite que desde cualquier parte y en cualquier momento, un usuario pueda acceder a sus fuentes de información. Sería interesante que la gente hiciera públicos sus canales en el agregador FeedRaider, donde esto trabajaría como un sistema social de recomendación. De sea forma podríamos ver que le gusta a cada uno y tomar aquellas recomendaciones de canales que nos interesan a los efectos de mejorar -socialmente- nuestras fuentes.
viernes, diciembre 01, 2006
Debate sobre materiales papel versus digital en las bibliotecas
He hallado un artículo para compartir, el cual ha sido escrito por Scott Carlson y titulado "Library Renovation Leads to Soul Searching at Cal Poly" plantea como las instituciones deben adaptarse a este mundo con sobrecarga de información. Se presenta un caso real donde se discute como se debería tratar al material papel cuando los presupuestos no alcanzan.
La Facultad de Informática de la UNLP ejemplo de calidad e integración con la realidad
Hace un momento recibí el Boletín del Consejo Profesional de Ciencias Informáticas, me dió una alegría bárbara ver que una de sus noticias hablaba acerca del éxito de la Facultad de informática de la Universidad Nacional de La Plata, en lo referente a la formación de profesionales. Conozco muy poco de su organización, pero si puedo decir que este reconocimiento responde a un trabajo continuo de alumnos y profesores que han logrado armar una carrera donde además de impartir los cursos regulares, existen otras actividades que toda universidad debería tener: vinculación con el medio, práctica real en empresas, pasantías para graduados, investigación académica e investigación aplicada junto a la sociedad, extensión a través del armado y apoyo a jornadas técnicas, apoyo (pragmático no de palabra) a otros niveles educativos.
Les copio la noticia en cuestión
La Plata, futura ciudad digital
Las grandes empresas del sector están en una constante búsqueda de "genios". Muchas veces se nutren de egresados y estudiantes de la UNLP o la UTN regional. Actualmente los jóvenes son en su mayoría obligados a emigrar. Pero ya hay compañías que observan a la capital bonaerense como un buen lugar donde radicarse para realizar sus desarrollos
La calidad de los profesionales argentinos dedicados al desarrollo de software y de técnicos especializados en las nuevas tecnologías se refleja en la alta demanda de las industrias del sector con base en el extranjero.
Las gigantes como IBM, Microsoft u Oracle se nutren de jóvenes argentinos, a tal punto que muchas de estas compañías realizan acuerdos estratégicos con universidades para procurarse de los mejores recursos humanos.Pero entre todas las ciudades del país que se han convertido en grandes formadoras de expertos, La Plata ocupa un lugar destacado.
Así quedó plasmado con las declaraciones de "Pete" Martínez, un alto ejecutivo de IBM con base en Boca Ratón, EE.UU y ex integrante del equipo que ideó la primera PC, cuando visitó el Diario Hoy hace pocos meses y dijo: "Los egresados de la Universidad Nacional de La Plata y los de la Universidad Tecnológica Nacional son envidiables por la excelencia en su formación".
Pero, la gran mayoría de los jóvenes profesionales terminan por trabajar en el exterior. Por el contrario, una empresa de capitales argentinos que lidera el desarrollo de soluciones para compañías de seguros ve que La Plata puede convertirse en un polo de desarrollo tecnológico para el resto del mundo y decidieron hacer punta.
Fue así que la firma Sistran -con fuerte presencia de platenses entre sus socios y ejecutivos- creó su Área de Desarrollo de aplicaciones, bajo el concepto de Software Factory, con oficinas en la capital del primer estado argentino.
El área dependerá de las Unidades de Negocio de México y Puerto Rico y su objetivo será en proyectos que surjan sobre tecnología .Net y arquitectura SOA (orientada a servicios) en dichos mercados.
Puntualmente tendrá 4 secciones: Interfaz de usuario, Componentes, Base de datos y Diseño. Su característica distintiva será apuntar a la especialización en cada una de ellas. Para dicho emprendimiento se han seleccionado 7 profesionales radicados en La Plata ciudad, integrando mayor cantidad de personal en un corto plazo.
"El área de desarrollo de aplicaciones, trabaja conceptualmente como software factory: una línea de producción de Software que concentra procesos de desarrollo, herramientas, frameworks, guías y templates para construir una aplicación específica. En otras palabras: es un modelo de servicios apoyado en una estrategia metodológica que ha madurado en el desarrollo de Software. El CORE de los sistemas seguirá siendo responsabilidad de Fábrica Corporativa por lo cual este área operará en forma coordinada bajo las metodologías de fábrica para atender los proyectos", explicó Bernardo Suburu, director Corporativo de Sistran.
En tanto, Mario Rosales, Director de Operaciones de Sistran México subrayó: "Detectamos la posibilidad de desarrollar el Polo informático de esta ciudad -que aún no ha sido explotado- con muchos recursos capacitados gracias al excelente nivel que proveen las Universidades tecnológicas. Es por ello que Sistran suma oportunidades de trabajo a los jóvenes estudiantes de La Plata para que continúen sus estudios y al recibirse cuenten con la experiencia necesaria para desenvolverse profesionalmente".
La empresa cuenta entre sus clientes regionales en Latinoamérica más importantes a AIG, CNP, Bradesco, Chubb, Generali, Horizonte, La República, La Veloz, La Mercantil Andina, Liderar, Sofrecom; Telecom Argentina, Swiss Medical Group, SMG Compañía de Seguros, Victoria Cía Argentina de Seguros, Winterthur Internacional XL Insurance Argentina y Royal Sun Alliance, entre otros. Y posee filiales en Brasil, Ecuador, Colombia, México, Guatemala, Puerto Rico y oficinas en Panamá.
Ojalá el ejemplo llegue a otros lugares!!!
Les copio la noticia en cuestión
La Plata, futura ciudad digital
Las grandes empresas del sector están en una constante búsqueda de "genios". Muchas veces se nutren de egresados y estudiantes de la UNLP o la UTN regional. Actualmente los jóvenes son en su mayoría obligados a emigrar. Pero ya hay compañías que observan a la capital bonaerense como un buen lugar donde radicarse para realizar sus desarrollos
La calidad de los profesionales argentinos dedicados al desarrollo de software y de técnicos especializados en las nuevas tecnologías se refleja en la alta demanda de las industrias del sector con base en el extranjero.
Las gigantes como IBM, Microsoft u Oracle se nutren de jóvenes argentinos, a tal punto que muchas de estas compañías realizan acuerdos estratégicos con universidades para procurarse de los mejores recursos humanos.Pero entre todas las ciudades del país que se han convertido en grandes formadoras de expertos, La Plata ocupa un lugar destacado.
Así quedó plasmado con las declaraciones de "Pete" Martínez, un alto ejecutivo de IBM con base en Boca Ratón, EE.UU y ex integrante del equipo que ideó la primera PC, cuando visitó el Diario Hoy hace pocos meses y dijo: "Los egresados de la Universidad Nacional de La Plata y los de la Universidad Tecnológica Nacional son envidiables por la excelencia en su formación".
Pero, la gran mayoría de los jóvenes profesionales terminan por trabajar en el exterior. Por el contrario, una empresa de capitales argentinos que lidera el desarrollo de soluciones para compañías de seguros ve que La Plata puede convertirse en un polo de desarrollo tecnológico para el resto del mundo y decidieron hacer punta.
Fue así que la firma Sistran -con fuerte presencia de platenses entre sus socios y ejecutivos- creó su Área de Desarrollo de aplicaciones, bajo el concepto de Software Factory, con oficinas en la capital del primer estado argentino.
El área dependerá de las Unidades de Negocio de México y Puerto Rico y su objetivo será en proyectos que surjan sobre tecnología .Net y arquitectura SOA (orientada a servicios) en dichos mercados.
Puntualmente tendrá 4 secciones: Interfaz de usuario, Componentes, Base de datos y Diseño. Su característica distintiva será apuntar a la especialización en cada una de ellas. Para dicho emprendimiento se han seleccionado 7 profesionales radicados en La Plata ciudad, integrando mayor cantidad de personal en un corto plazo.
"El área de desarrollo de aplicaciones, trabaja conceptualmente como software factory: una línea de producción de Software que concentra procesos de desarrollo, herramientas, frameworks, guías y templates para construir una aplicación específica. En otras palabras: es un modelo de servicios apoyado en una estrategia metodológica que ha madurado en el desarrollo de Software. El CORE de los sistemas seguirá siendo responsabilidad de Fábrica Corporativa por lo cual este área operará en forma coordinada bajo las metodologías de fábrica para atender los proyectos", explicó Bernardo Suburu, director Corporativo de Sistran.
En tanto, Mario Rosales, Director de Operaciones de Sistran México subrayó: "Detectamos la posibilidad de desarrollar el Polo informático de esta ciudad -que aún no ha sido explotado- con muchos recursos capacitados gracias al excelente nivel que proveen las Universidades tecnológicas. Es por ello que Sistran suma oportunidades de trabajo a los jóvenes estudiantes de La Plata para que continúen sus estudios y al recibirse cuenten con la experiencia necesaria para desenvolverse profesionalmente".
La empresa cuenta entre sus clientes regionales en Latinoamérica más importantes a AIG, CNP, Bradesco, Chubb, Generali, Horizonte, La República, La Veloz, La Mercantil Andina, Liderar, Sofrecom; Telecom Argentina, Swiss Medical Group, SMG Compañía de Seguros, Victoria Cía Argentina de Seguros, Winterthur Internacional XL Insurance Argentina y Royal Sun Alliance, entre otros. Y posee filiales en Brasil, Ecuador, Colombia, México, Guatemala, Puerto Rico y oficinas en Panamá.
Ojalá el ejemplo llegue a otros lugares!!!
jueves, noviembre 30, 2006
Nuevo estudio de Pew Internet sobre como se informa la población en USA cuando busca información científica
Hace nos días atrás, la organización Pew Internet & American Life Project, dedicada a realizar estudios de opinión pública en USA, presentó un nuevo informe titulado “The Internet as a Resource for News and Information about Science” . Los resultados más significativos son:
La televisión está en primer lugar y luego Internet cuando los usuarios desean obtener Información científica. El 41% obtiene la mayoría de la información de la TV, el 20% de Internet, el 14% de los periódicos y un 4% de las radios. En cambio, los usuarios con conexiones de banda ancha indican que el 34% obtiene información científica de la red y el 33% de la TV.
Del estudio se desprende que ,aparentemente, Internet es la primer fuente sobre la cual acude la gente cuando necesita información sobre un tema científico específico.
Para el 87% de los usuarios americanos (128 millones de adultos) Internet es una herramienta de investigación. Donde, por ejemplo, el 70% de los usuarios ha usado la red, alguna vez, para buscar el significado de un término científico. El 65% uso Internet para aprender cosas sobre historia de la ciencia. El 55 % uso la red para verificar hechos científicos o estadísticas. El 43% ha descargado datos científicos o gráficos.
Los buscadores representan la fuente más popular para comenzar una investigación sobre temas científicos entre aquellos usuarios que usan Internet como primer lugar para obtener tal tipo de información.
La mitad de todos usuarios de internet han visitado un sitio especializado en contenidos científicos.. Por ejemplo, un 23% ha visitado National Geographic, un 19% nasa.gov, un 14% Smithsonian site, 10% sience.com y 9% nture.com.
Cerca del 80% de los usuarios que buscan información en línea intenta comprobar su exactitud en otro sitio.
La televisión está en primer lugar y luego Internet cuando los usuarios desean obtener Información científica. El 41% obtiene la mayoría de la información de la TV, el 20% de Internet, el 14% de los periódicos y un 4% de las radios. En cambio, los usuarios con conexiones de banda ancha indican que el 34% obtiene información científica de la red y el 33% de la TV.
Del estudio se desprende que ,aparentemente, Internet es la primer fuente sobre la cual acude la gente cuando necesita información sobre un tema científico específico.
Para el 87% de los usuarios americanos (128 millones de adultos) Internet es una herramienta de investigación. Donde, por ejemplo, el 70% de los usuarios ha usado la red, alguna vez, para buscar el significado de un término científico. El 65% uso Internet para aprender cosas sobre historia de la ciencia. El 55 % uso la red para verificar hechos científicos o estadísticas. El 43% ha descargado datos científicos o gráficos.
Los buscadores representan la fuente más popular para comenzar una investigación sobre temas científicos entre aquellos usuarios que usan Internet como primer lugar para obtener tal tipo de información.
La mitad de todos usuarios de internet han visitado un sitio especializado en contenidos científicos.. Por ejemplo, un 23% ha visitado National Geographic, un 19% nasa.gov, un 14% Smithsonian site, 10% sience.com y 9% nture.com.
Cerca del 80% de los usuarios que buscan información en línea intenta comprobar su exactitud en otro sitio.
Técnica para facilitar búsquedas tolerantes a errores en la consulta o en el índice
Esto días estuve revisando algoritmos de apoyo a la ortografía y encontré una página donde se presenta una técnica basada en el uso de ngramas. Cada término del diccionario se divide en trigramas -segmentos de tres caracteres (casa = 6 trigramas {--c, -ca, cas, asa, sa-, a--})- y se almacenan en una tabla índice (trigrama(“a—“)=doc1, doc5,...,doc_n). Luego, cuando un usuario necesita consultar por un término al mismo se lo descompone en sus trigramas y se recuperan las entradas del índice relacionadas con cada uno de ellos. A continuación se aplica una fórmula de semejanza ortográfica (yo la conozco como distancia de Tanimoto) entre el término consultado y los distintos términos candidatos aportados por el índice. Si la semejanza supera un umbral U entonces se muestra el término como posible candidato en la respuesta. La salida de términos puede ordenarse por distancia con respecto al término de la consulta.
Hace unos años atrás un ex alumno Diego Barrientos puso a punto y valido una técnica semejante, la cual usamos para corrección ortográfica o sugerencias del tipo Google "Ud. quizo decir". Aquí pueden hallar un documento que habla acerca del algoritmo y aquí encuentran unas librerías C desarrolladas por Diego.El trabajo aún no está totalmente finalizado, se puede mejorar la calidad de las sugerencias utilizando técnicas que permitan manejar los casos de empate de términos candidatos en las listas de sugerencias, una posible herramienta sería modelos de lenguaje. SI hay alguien que le interese el tema y el C podemos discutirlo.
Hace unos años atrás un ex alumno Diego Barrientos puso a punto y valido una técnica semejante, la cual usamos para corrección ortográfica o sugerencias del tipo Google "Ud. quizo decir". Aquí pueden hallar un documento que habla acerca del algoritmo y aquí encuentran unas librerías C desarrolladas por Diego.El trabajo aún no está totalmente finalizado, se puede mejorar la calidad de las sugerencias utilizando técnicas que permitan manejar los casos de empate de términos candidatos en las listas de sugerencias, una posible herramienta sería modelos de lenguaje. SI hay alguien que le interese el tema y el C podemos discutirlo.
miércoles, noviembre 29, 2006
Off topic: Blogs amigos
Quería presentar en sociedad a un par de blogs de dos colegas, en estos caminos de la informática. Son fanáticos linuxeros y de la programación, bichos raros de los cuales hay pocos. Cuando tengan tiempo paseen por el "El Blog de Marcelo!" y "El Bit Negro". A ver si somos más y así podemos armar una comunidad y hasta tener un planet propio.
Telenoche, uso o abuso de la Wikipedia?
Recién mientras escribía, estaba escuchando en background el noticiero de canal 13 Telenoche. Alrededor de las 20:34 un señor periodista presenta una nota donde recuerda a George Harrison a 5 años de su muerte. Entre los datos que presentó, uno en particular me llamó la atención -el cual dice que fué pionero de la música electrónica- y decidí ir las páginas (ingles, español) de la Wikipedia a los efectos obtener mayor información. Ohhh, para mi agradable sorpresa el periodista estaba leyendo párrafos de las páginas. Pienso que bien !!! una institución tan noble como Telenoche utiliza tal fuente, lo cual le da importancia y la realza. Pero para mi corta alegría noto que al final no hay crédito a la misma, la Wipidedia fué ignorada totalmente.
Muchachos, por respeto a las decenas de miles de personas que construyen y preservan el conocimiento de la humanidad, la próxima vez den crédito.
Muchachos, por respeto a las decenas de miles de personas que construyen y preservan el conocimiento de la humanidad, la próxima vez den crédito.
Relevamiento sobre razones para escribir un blog
Estuve leyendo en Microsiervos una entrada sobre un trabajo realizado por Lorena Loretahur que consistió en entrevistar a una serie de bloggers a los efectos de determinar que los motiva a escribir. Tales respuestas han sido compiladas en un documento titulado "¿Por qué escribes en tu blog?". Todavía no lo he leido pero podría ser una buena fuente de datos para investigaciones sobre motivaciones en redes sociales.
martes, noviembre 28, 2006

Tutorial sobre blogs
"El abecé del universo blog" de Antonio Fumero, publicado en Telos: Cuadernos de Comunicación Tecnología y Sociedad es un tutorial distinto. Más allá de la historia y de qué son y cómo se usan y etc, etc,etc. Fumero presenta el concepto de socialware (esta palabra se la escuche por primera vez al profesor Saroka a principios de la decada de los 80 en una conferencia auspiciada por la Cooperativa Eléctrica de la Ciudad de Luján) y desarrolla bien este componente que tiene que ver con la comunidad que sustenta tales aplicaciones.
Paper que presenta un modelo de un sistema de etiquetado
El artículo de Marlow y otros "HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, ToRead" trata sobre la técnica de etiquetado o tags y presenta una revisión de trabajos académicos relacionados. Como aporte adicional presenta un modelo de un sistema de etiquetado y una taxonomía. Por otro lado trata el tema de cuales son los incentivos para que los usuarios contribuyan adosando etiquetas a distintos recursos.
Cita: "HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, ToRead." Cameron Marlow, Mor Naaman, danah boyd, Marc Davis. Proceedings of Hypertext 2006, New York: ACM Press, 2006.
Disponible en: http://www.danah.org/papers/Hypertext2006.pdf
Cita: "HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, ToRead." Cameron Marlow, Mor Naaman, danah boyd, Marc Davis. Proceedings of Hypertext 2006, New York: ACM Press, 2006.
Disponible en: http://www.danah.org/papers/Hypertext2006.pdf
Conocen a Tagsonomy?
Tagsonomy es un blog dedicado exclusivamente a presentar noticias y discutir aspectos relacionados con los tags o etiquetas. Estuve revisando las últimas entradas, el sitio parece útil y tiene información interesante para ayudar a estudiar el tema de las comunidades digitales. El problema es la frecuencia de los posts, es muy baja.
lunes, noviembre 27, 2006
Libros para descargar
La semana pasada Leo envío un correo a la lista Grulic donde nos regalaba tres entradas a libros libres para descargar. Me pareció útil y afín la temática, por eso quiero compartirlos.
Jordi Mas i Hernàndez, “Software libre: técnicamente viable, económicamente sostenible y socialmente justo” primera edición, 2005. Disponible en http://www.softcatala.org/~jmas/swl/llibrejmas.pdf
Beatriz Busaniche et al. “Prohibido pensar, propiedad privada : los monopolios sobre la vida, el conocimiento y la cultura - 1a ed., Córdoba : Fundación Vía Libre, 2006.
Disponible en http://www.vialibre.org.ar/wp-content/uploads/2006/11/prohibidopensarpropiedadprivada.pdf
David Bueno. “Copia este libro”, Ed. Dmem S.L., 2005. Disponible en http://www.rebelion.org/docs/23824.pdf
Jordi Mas i Hernàndez, “Software libre: técnicamente viable, económicamente sostenible y socialmente justo” primera edición, 2005. Disponible en http://www.softcatala.org/~jmas/swl/llibrejmas.pdf
Beatriz Busaniche et al. “Prohibido pensar, propiedad privada : los monopolios sobre la vida, el conocimiento y la cultura - 1a ed., Córdoba : Fundación Vía Libre, 2006.
Disponible en http://www.vialibre.org.ar/wp-content/uploads/2006/11/prohibidopensarpropiedadprivada.pdf
David Bueno. “Copia este libro”, Ed. Dmem S.L., 2005. Disponible en http://www.rebelion.org/docs/23824.pdf
Entrevista a Enrique Dans
Enrique es profesor en el área de tecnologías de la información en España, pero además es un analista que tiene una visión crítica y acertada de los fenómenos de usuario de Internet. He leido un reportaje publicado en Baquia y extraje algunas partes que me gustaría compartir con Uds.
Cuando se le pregunta acerca del spam responde “...el spam, en realidad, vive de una asimetría de conocimiento: el crecimiento de la Red es tan grande que el spam se nutre de las personas con poca experiencia que contestan a sus mensajes... Con el tiempo se popularizará el conocimiento acerca del spam, la cantidad de gente que contesta a ese tipo de mensajes será cada vez menor y el correo basura desaparecerá...”
Acerca del movimiento web 2.0 indica que brinda “...la posibilidad de desempeñar un papel activo. No se trata de que tengas que tener un blog, ni que estés obligado a comentar en ningún sitio, sino que, si te apetece hacerlo, tendrás sitio para ello, vivirás una actitud abierta y participativa. En breve, los sitios unidireccionales nos parecerán cosa del pasado, y cuando un medio no nos ofrezca ese tipo de prestaciones, nos encontraremos raros, incómodos...”
“...La brecha digital se reduce con servicios y contenidos de calidad, creando propuestas de valor adecuadas. ...Los poderes públicos deben limitarse a poner infraestructuras al alcance del usuario, cediendo por ejemplo el uso de sus infraestructuras a operadores en libre competencia que ofrezcan conectividad en unas condiciones interesantes para sus posibles clientes, compitiendo entre sí en mercados no distorsionados...”
Cuando se le pregunta acerca del spam responde “...el spam, en realidad, vive de una asimetría de conocimiento: el crecimiento de la Red es tan grande que el spam se nutre de las personas con poca experiencia que contestan a sus mensajes... Con el tiempo se popularizará el conocimiento acerca del spam, la cantidad de gente que contesta a ese tipo de mensajes será cada vez menor y el correo basura desaparecerá...”
Acerca del movimiento web 2.0 indica que brinda “...la posibilidad de desempeñar un papel activo. No se trata de que tengas que tener un blog, ni que estés obligado a comentar en ningún sitio, sino que, si te apetece hacerlo, tendrás sitio para ello, vivirás una actitud abierta y participativa. En breve, los sitios unidireccionales nos parecerán cosa del pasado, y cuando un medio no nos ofrezca ese tipo de prestaciones, nos encontraremos raros, incómodos...”
“...La brecha digital se reduce con servicios y contenidos de calidad, creando propuestas de valor adecuadas. ...Los poderes públicos deben limitarse a poner infraestructuras al alcance del usuario, cediendo por ejemplo el uso de sus infraestructuras a operadores en libre competencia que ofrezcan conectividad en unas condiciones interesantes para sus posibles clientes, compitiendo entre sí en mercados no distorsionados...”
domingo, noviembre 26, 2006
OLPC Argentina: Ruego a Dios que nuestros representantes sean eficaces y eficientes
La semana pasada en la casa de gobierno argentino se reunió el presidente Kirchner y Nicholas Negroponte a los efectos de empezar a cerrar el acuerdo de la “posible” adquisición de computadoras portátiles económicas. Del millón inicial solo empezaremos con unas 500, para probar y luego vemos (las cuales se entregarán antes de fin de año). Esta información es oficial y está publicada en el sitio de la casa rosada. Gracias por el dato Pablo Mancini.
Lo raro, y que todavía no me convence del proyecto, es que el grupo argentino oficial no ha abierto el juego a universidades, organizaciones profesionales y a organizaciones de usuarios, dado que esta gente está en todo el país y es la que puede 1) desarrollar soft, 2) seleccionar soft, 3) ver usos alternativos de la plataforma, 4) ayudar a construir servicios, 5) establecer redes sociales destinadas al desarrollo del alumno y su contexto familiar, 6) dar soporte técnico al alumno, la escuela, 7) ayudar a capacitar a los docentes, etc, etc, etc. Es decir a apropiarse de la tecnología en tiempo y forma, acordémonos que cuando en estos lares adquirimos un aparato electrónico ya es viejo y lo debemos amortizar en la menor cantidad de tiempo.
En este proyecto como pueblo argentino debemos ser eficaces (que llegue a todo destinatario) y eficientes ( que se use con propiedad) dado que es nuestro dinero el que se usó para comprar, por eso los que algo de tecnología manejamos debemos pedir a nuestros representantes una inversión racional. No tengan miedo en invertir en educación (solo la educación es la que hace a un soberano, el no tenerla la convierte en esclavo) pero háganlo de frente y con la sociedad y no de espaldas y para la foto (es una p. costumbre de los políticos en todos los niveles, decanos, rectores, ministros concejales, etc, etc.).
En el sitio Educ.ar pueden acceder al audio de una conferencia de hace unos meses atrás donde se explica en que consiste el proyecto OLPC y que beneficios brindaría.
Con mi deseo de éxito, saludos a todos
Lo raro, y que todavía no me convence del proyecto, es que el grupo argentino oficial no ha abierto el juego a universidades, organizaciones profesionales y a organizaciones de usuarios, dado que esta gente está en todo el país y es la que puede 1) desarrollar soft, 2) seleccionar soft, 3) ver usos alternativos de la plataforma, 4) ayudar a construir servicios, 5) establecer redes sociales destinadas al desarrollo del alumno y su contexto familiar, 6) dar soporte técnico al alumno, la escuela, 7) ayudar a capacitar a los docentes, etc, etc, etc. Es decir a apropiarse de la tecnología en tiempo y forma, acordémonos que cuando en estos lares adquirimos un aparato electrónico ya es viejo y lo debemos amortizar en la menor cantidad de tiempo.
En este proyecto como pueblo argentino debemos ser eficaces (que llegue a todo destinatario) y eficientes ( que se use con propiedad) dado que es nuestro dinero el que se usó para comprar, por eso los que algo de tecnología manejamos debemos pedir a nuestros representantes una inversión racional. No tengan miedo en invertir en educación (solo la educación es la que hace a un soberano, el no tenerla la convierte en esclavo) pero háganlo de frente y con la sociedad y no de espaldas y para la foto (es una p. costumbre de los políticos en todos los niveles, decanos, rectores, ministros concejales, etc, etc.).
En el sitio Educ.ar pueden acceder al audio de una conferencia de hace unos meses atrás donde se explica en que consiste el proyecto OLPC y que beneficios brindaría.
Con mi deseo de éxito, saludos a todos
sábado, noviembre 25, 2006
Software social como recurso para mejorar comunidades de inteligencia
Estuve leyendo un trabajo del Dr Andrus, miembro de la Central de Agencia Americana, en el cual evalúa el uso de wikis y blogs en comunidades de inteligencia mundial con la finalidad de mejorar el intercambio de información. Me pareció muy buena la parte descriptiva deherramientas de auto organización.
El trabajo se llama "The Wiki and the Blog: Toward a Complex Adaptive Intelligence Community" y fué publicado en la revista "Studies in Intelligence", Vol 49, No 3, September 2005.
El trabajo se llama "The Wiki and the Blog: Toward a Complex Adaptive Intelligence Community" y fué publicado en la revista "Studies in Intelligence", Vol 49, No 3, September 2005.
jueves, noviembre 23, 2006
Recuperación de información en el espacio web
Por Gabriel Tolosa y Fernando Bordignon
Con la aparición de la web surgieron nuevos desafíos para resolver en el área de recuperación de información debido – principalmente – a sus características y su tamaño. La web puede ser vista como un gran repositorio de información, completamente distribuido sobre Internet y accesible por gran cantidad de usuarios. Por sus orígenes como un espacio público existen millones de organizaciones y usuarios particulares que incorporan, quitan ó modifican contenido continuamente, por lo que su estructura no es estática.
Su contenido no respeta estándares de calidad, ni estilos ni organización. Como medio de publicación de información de naturaleza diversa se ha convertido en un servicio de permanente crecimiento. Una de las características de la información publicada en la web es su dinamismo, dado que pueden variar en el tiempo tanto los contenidos como su ubicación [6] [33].
El tamaño de la web es imposible de medir exactamente y muy difícil de estimar. Sin embargo, se calcula que son decenas de terabytes de información, y crece permanentemente. Está formada por documentos de diferente naturaleza y formato, desde páginas HTML hasta archivos de imágenes pasando por gran cantidad de formatos estándar y propietarios, no solamente con contenido textual, sino también con contenido multimedial.
La búsqueda de información en la web es una práctica común para los usuarios de Internet y los sistemas de recuperación de información web (conocidos como motores de búsqueda) se han convertido en herramientas indispensables para los usuarios. Su arquitectura y modo de operación se basan en poder recolectar mediante un mecanismo adecuado los documentos existentes en los sitios web. Una vez obtenidos, se llevan a cabo tareas de procesamiento que permiten extraer términos significativos contenidos dentro de los mismos, junto con otra información, a los efectos de construir estructuras de datos (índices) que permitan realizar búsquedas de manera eficiente. Luego, a partir de una consulta realizada por un usuario, un motor de búsqueda extraerá de los índices las referencias que satisfagan la consulta y se retornará una respuesta rankeada por diversos criterios al usuario. El modo de funcionamiento de los diferentes motores de búsqueda puede diferir en diversas implementaciones de los mecanismos de recolección de datos, los métodos de indexación y los algoritmos de búsqueda y rankeo.
Sin embargo, esta tarea no es sencilla y se ha convertido en un desafío para los SRI debido las características propias de la web. Baeza-Yates [2] plantea que hay desafíos de dos tipos:
a) Respecto de los datos
– Distribuidos: La web es un sistema distribuido, donde cada proveedor de información publica su información en computadoras pertenecientes a redes conectadas a Internet, sin una estructura ó topología predefinida.
– Volátiles: El dinamismo del sistema hace que exista información nueva a cada momento ó bien que cambie su contenido ó inclusive desaparezca otra que se encontraba disponible.
– No estructurados y redundantes: Básicamente, la web está formada de páginas HTML, las cuales no cuentan con una estructura única ni fija. Además, mucho del contenido se encuentra duplicado (por ejemplo, espejado).
– Calidad: En general, la calidad de la información publicada en la web es altamente variable, tanto en escritura como en actualización (existe información que puede considerarse obsoleta), e inclusive existe información con errores sintácticos, ortográficos y demás.
– Heterogeneidad: La información se puede encontrar publicada en diferentes tipos de medios (texto, audio, gráficos) con diferentes formatos para cada uno de éstos. Además, hay que contemplar los diferentes idiomas y diferentes alfabetos (por ejemplo, árabe ó chino).
b) Respecto de los usuarios.
– Especificación de la consulta: Los usuarios encuentran dificultades para precisar – en el lenguaje de consulta – su necesidad de información.
– Manejo de las respuestas: Cuando un usuario realiza una consulta se ve sobrecargado de respuestas, siendo una parte irrelevante.
Estas características – sumadas al tamaño de la web – imponen restricciones a las herramientas de búsqueda en cuanto a la cobertura y acceso a los documentos, exigiendo cada vez mayores recursos computacionales (espacio de almacenamiento, ancho de banda de las redes, ciclos de CPU) y diferentes estrategias para mejorar la calidad de las respuestas.
Referencias
[2] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[6] Brewington, B. E. y Cybenko Thayer, G. “How Dynamic is the Web?” En: Proceedings of the Ninth International World Wide Web Conference. 2000.
[33] Lawrence, S. y Giles, L. “Accessibility and Distribution of Information on the Web”. Nature, vol.400, n.6740, pags.107-109. 1999.
Con la aparición de la web surgieron nuevos desafíos para resolver en el área de recuperación de información debido – principalmente – a sus características y su tamaño. La web puede ser vista como un gran repositorio de información, completamente distribuido sobre Internet y accesible por gran cantidad de usuarios. Por sus orígenes como un espacio público existen millones de organizaciones y usuarios particulares que incorporan, quitan ó modifican contenido continuamente, por lo que su estructura no es estática.
Su contenido no respeta estándares de calidad, ni estilos ni organización. Como medio de publicación de información de naturaleza diversa se ha convertido en un servicio de permanente crecimiento. Una de las características de la información publicada en la web es su dinamismo, dado que pueden variar en el tiempo tanto los contenidos como su ubicación [6] [33].
El tamaño de la web es imposible de medir exactamente y muy difícil de estimar. Sin embargo, se calcula que son decenas de terabytes de información, y crece permanentemente. Está formada por documentos de diferente naturaleza y formato, desde páginas HTML hasta archivos de imágenes pasando por gran cantidad de formatos estándar y propietarios, no solamente con contenido textual, sino también con contenido multimedial.
La búsqueda de información en la web es una práctica común para los usuarios de Internet y los sistemas de recuperación de información web (conocidos como motores de búsqueda) se han convertido en herramientas indispensables para los usuarios. Su arquitectura y modo de operación se basan en poder recolectar mediante un mecanismo adecuado los documentos existentes en los sitios web. Una vez obtenidos, se llevan a cabo tareas de procesamiento que permiten extraer términos significativos contenidos dentro de los mismos, junto con otra información, a los efectos de construir estructuras de datos (índices) que permitan realizar búsquedas de manera eficiente. Luego, a partir de una consulta realizada por un usuario, un motor de búsqueda extraerá de los índices las referencias que satisfagan la consulta y se retornará una respuesta rankeada por diversos criterios al usuario. El modo de funcionamiento de los diferentes motores de búsqueda puede diferir en diversas implementaciones de los mecanismos de recolección de datos, los métodos de indexación y los algoritmos de búsqueda y rankeo.
Sin embargo, esta tarea no es sencilla y se ha convertido en un desafío para los SRI debido las características propias de la web. Baeza-Yates [2] plantea que hay desafíos de dos tipos:
a) Respecto de los datos
– Distribuidos: La web es un sistema distribuido, donde cada proveedor de información publica su información en computadoras pertenecientes a redes conectadas a Internet, sin una estructura ó topología predefinida.
– Volátiles: El dinamismo del sistema hace que exista información nueva a cada momento ó bien que cambie su contenido ó inclusive desaparezca otra que se encontraba disponible.
– No estructurados y redundantes: Básicamente, la web está formada de páginas HTML, las cuales no cuentan con una estructura única ni fija. Además, mucho del contenido se encuentra duplicado (por ejemplo, espejado).
– Calidad: En general, la calidad de la información publicada en la web es altamente variable, tanto en escritura como en actualización (existe información que puede considerarse obsoleta), e inclusive existe información con errores sintácticos, ortográficos y demás.
– Heterogeneidad: La información se puede encontrar publicada en diferentes tipos de medios (texto, audio, gráficos) con diferentes formatos para cada uno de éstos. Además, hay que contemplar los diferentes idiomas y diferentes alfabetos (por ejemplo, árabe ó chino).
b) Respecto de los usuarios.
– Especificación de la consulta: Los usuarios encuentran dificultades para precisar – en el lenguaje de consulta – su necesidad de información.
– Manejo de las respuestas: Cuando un usuario realiza una consulta se ve sobrecargado de respuestas, siendo una parte irrelevante.
Estas características – sumadas al tamaño de la web – imponen restricciones a las herramientas de búsqueda en cuanto a la cobertura y acceso a los documentos, exigiendo cada vez mayores recursos computacionales (espacio de almacenamiento, ancho de banda de las redes, ciclos de CPU) y diferentes estrategias para mejorar la calidad de las respuestas.
Referencias
[2] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[6] Brewington, B. E. y Cybenko Thayer, G. “How Dynamic is the Web?” En: Proceedings of the Ninth International World Wide Web Conference. 2000.
[33] Lawrence, S. y Giles, L. “Accessibility and Distribution of Information on the Web”. Nature, vol.400, n.6740, pags.107-109. 1999.
Anécdotas por Adrián Paenza
El amigo Paenza, en una columna de hace unos meses atrás en Página 12, nos trae una serie de anécdotas que relacionan a Google y a un par de matemáticos argentinos. Gracias por el dato compañero Victorio.:-)
Comparativa sobre repositorios de documentos
En Nueva Zelandia existe un proyecto denominado "Open Access
Repositories in New Zealand".El grupo de trabajo ha presentado una nueva versión de un documento donde comparan tres alternativas basadas software open source: Dspace, Eprints y Fedora.
Hay buena información técnica acerca de las capacidades de cada plataforma.
Repositories in New Zealand".El grupo de trabajo ha presentado una nueva versión de un documento donde comparan tres alternativas basadas software open source: Dspace, Eprints y Fedora.
Hay buena información técnica acerca de las capacidades de cada plataforma.
miércoles, noviembre 22, 2006
Mapa conceptual de tecnología web
En el blog Modern Life is Rubbish presentan un grafo que trata de ilustrar las distintas tecnologías web y sus relaciones.

Paquetes de soft en azul, lenguajes en beige, tecnologías centrales o de core en verde e infraestructura en gris. Para mi gusto le faltan tecnologías y algunas relaciones más, pero es un buen comienzo.
Paquetes de soft en azul, lenguajes en beige, tecnologías centrales o de core en verde e infraestructura en gris. Para mi gusto le faltan tecnologías y algunas relaciones más, pero es un buen comienzo.
lunes, noviembre 20, 2006
Modelos de Recuperación de Información
Por Gabriel Tolosa y Fernando Bordignon.
Los SRI (sistemas de recuperación de información)toman un conjunto de documentos (colección) para procesar y luego poder responder consultas. De forma básica, podemos clasificar los documentos en estructurados y no estructurados. Los primeros son aquellos en los que se pueden reconocer elementos estructurales con una semántica bien definida, mientras que los segundos corresponden a texto libre, sin formato. La diferencia fundamental de un SRI que procese documentos estructurados se encuentra en que puede extraer información adicional al contenido textual, la cual utiliza en la etapa de recuperación para facilitar la tarea y aumentar las prestaciones.
A partir de lo expresado anteriormente se presenta una posible clasificación de modelos de RI – la cual no es exhaustiva – de acuerdo a características estructurales de los documentos.

A continuación se describen – de forma somera – los modelos clásicos y el álgebra de regiones. Más adelante, en el capítulo 4, se profundizará en los modelos booleano y vectorial.
1. Modelo booleano
En el modelo booleano la representación de la colección de documentos se realiza sobre una matriz binaria documento–término, donde los términos han sido extraídos manualmente o automáticamente de los documentos y representan el contenido de los mismos.

Las consultas se arman con términos vinculados por operadores lógicos (AND, OR, NOT) y los resultados son referencias a documentos donde cuya representación satisface las restricciones lógicas de la expresión de búsqueda. En el modelo original no hay ranking de relevancia sobre el conjunto de respuestas a una consulta, todos los documentos poseen la misma relevancia. A continuación se muestra un ejemplo mediante conjuntos de operaciones utilizando el modelo booleano.
A = {Documentos que contienen el término T1}
B = {Documentos que contienen el término T2}

Si bien es el primer modelo desarrollado y aún se lo utiliza, no es el preferido por los ingenieros de software para sus desarrollos. Existen diversos puntos en contra que hacen que cada día se lo utilice menos y – además – se han desarrollado algunas extensiones, bajo el nombre modelo booleano extendido [64] [51], que tratan de mejorar algunos puntos débiles.
2. Modelo Vectorial
Este modelo fue planteado y desarrollado por Gerard Salton [49] y – originalmente – se implementó en un SRI llamado SMART. Aunque el modelo posee más de treinta años, actualmente se sigue utilizando debido a su buena performance en la recuperación de documentos.
Conceptualmente, este modelo utiliza una matriz documento–término que contiene el vocabulario de la colección de referencia y los documentos existentes. En la intersección de un término t y un documento d se almacena un valor numérico de importancia del término t en el documento d; tal valor representa su poder de discriminación. Así, cada documento puede ser visto como un vector que pertenece a un espacio n-dimensional, donde n es la cantidad de términos que componen el vocabulario de la colección. En teoría, los documentos que contengan términos similares estarán a muy poca distancia entre sí sobre tal espacio. De igual forma se trata a la consulta, es un documento más y se la mapea sobre el espacio de documentos. Luego, a partir de una consulta dada es posible devolver una lista de documentos ordenados por distancia (los más relevantes primero). Para calcular la semejanza entre el vector consulta y los vectores que representan los documentos se utilizan diferentes fórmulas de distancia, siendo la más común la del coseno.
Obsérvese el siguiente ejemplo donde se representa a un documento d y a una consulta c:
Documento: “La República Argentina ha sido nominada para la realización del X Congreso Americano de Epidemiología en Zonas de Desastre. El evento se realizará ...”
Consulta: “argentina congreso epidemiología”
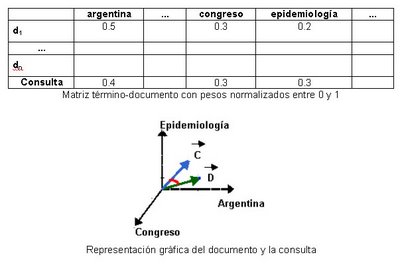
3. Modelo probabilístico
Fue propuesto por Robertson y Spark-Jones [47] con el objetivo de representar el proceso de recuperación de información desde el punto de vista de las probabilidades. A partir de una expresión de consulta se puede dividir una colección de N documentos en cuatro subconjuntos distintos: REL conjunto de documentos relevantes, REC conjunto de documentos recuperados, RR conjunto de documentos relevantes recuperados y NN el conjunto de documentos no relevantes no recuperados.
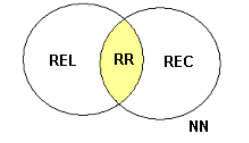
El resultado ideal de a una consulta se da cuando el conjunto REL es igual REC. Como resulta difícil lograrlo en primera intención, el usuario genera una descripción probabilística del conjunto REL y a través de sucesivas interacciones con el SRI se trata de mejorar la perfomance de recuperación. Dado que una recuperación no es inmediata dado que involucra varias interacciones con el usuario y que estudios han demostrado que su perfomance es inferior al modelo vectorial, su uso es bastante limitado.
4. Modelos para documentos estructurados
Los modelos clásicos responden a consultas, buscando sobre una estructura de datos que representa el contenido de los documentos de una colección, únicamente como listas de términos significativos. Un modelo de recuperación de documentos estructurados utiliza la estructura de los mismos a los efectos de mejorar la performance y brindar servicios alternativos al usuario (por ejemplo, uso de memoria visual, recuperación de elementos multimedia, mayor precisión sobre el ámbito de la consulta y demás).
La estructura de los documentos a indexar está dada por marcas o etiquetas, siendo los estándares más utilizados el SGML (Standard General Markup Language), el HTML (HyperText Markup Language), el XML (eXtensible Markup Language) y LATEX.
Al poseer la descripción de parte de la estructura de un documento es posible generar un grafo sobre el que se navegue y se respondan consultas de distinto tipo, por ejemplo:
–Por estructura: ¿Cuáles son las secciones del segundo capítulo?
–Por metadatos o campos: Documentos de “Editorial UNLu” editados en 1998
–Por contenido: Término “agua” en títulos de secciones
–Por elementos multimedia: Imágenes cercanas a párrafos que contengan Bush
Para Baeza-Yates existen dos modelos en esta categoría “nodos proximales” [37] y “listas no superpuestas” [8]. Ambos modelos se basan en almacenar las ocurrencias de los términos a indexar en estructuras de datos diferentes, según aparezcan en algún elemento de estructura (región) o en otro como capítulos, secciones, subsecciones y demás. En general, las regiones de una misma estructura de datos no poseen superposición, pero regiones en diferentes estructuras sí se pueden superponer.

Nótese que en el ejemplo anterior existen cuatro niveles de listas para almacenar información relativa a contenido textual y estructura de un documento tipo libro. En general, los tipos de consultas soportados son simples:
· Seleccione una región que contenga una palabra dada
· Seleccione una región X que no que no contenga una región Y
· Seleccione una región contenida en otra región
Sobre el ejemplo de estructura planteado un ejemplo de consulta sería:
[subsección[+] CONTIENE “‘tambo” ]
Como respuesta el SRI buscaría subsecciones y sub-subsecciones que contengan el término “tambo“.
Cabe mencionar que algunos motores de búsqueda de Internet ya utilizan ciertos elementos de la estructura de un documento – por ejemplo, los títulos – a los efectos de realizar tareas de rankeo, resumen automático, clasificación y otras.
La expansión de estos lenguajes de demarcación, especialmente en servicios sobre Internet, hacen que se generen y publiquen cada vez más documentos semiestructurados. Es necesario – entonces – desarrollar técnicas que aprovechen el valor agregado de los nuevos documentos. Si bien – en la actualidad – éstas no se encuentran tan desarrolladas como los modelos tradicionales, consideramos su evolución como una cuestión importante en el área de RI, especialmente a partir de investigaciones con enfoques diferentes que abordan la problemática [18] [38] [45].
Referencias
[8] Burkowski, F. “Retrieval activities in a database consisting of heterogeneous collections of structured texts”. In Belkin, N., Ingwersen, P., Pejtersen, A. M., and Fox, E., editors, Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 112–125, New York. ACM Press. 1992.
[18] Egnor, D. y Lord, R. “Structured information retrieval using XML”. En: Proceedings of the ACM SIGIR 2000 Workshop on XML and Information Retrieval, Julio 2000.
[37] Navarro, G. y Baeza-Yates, R. “A language for queries on structure and contents of textual databases”. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 93-101, New York. ACM Press. 1995.
[38] Ogilvie, P. y Callan, J. “Language Models and Structured Document Retrieval”. En: Proceedings of the first INEX workshop, 2003.
[45] Raghavan, S. Y Garcia-Molina, H. “Integrating diverse information management systems: A brief survey”. IEEE Data Engineering Bulletin, 24(4):44-52, 2001.
[47] Robertson, S.E y Spark-Jones, K. “Relevance Weighting of Search terms”. Journal of Documentation. 33, p.126-148. 1976.
[49] Salton, G. (editor). “The SMART Retrieval System – Experiments in Automatic Document Processing”. Prentice Hall In. Englewood Cliffs, NJ. 1971.
[51] Salton, G.; Fox, E.A. y Wu, H. “Extended Boolean information retrieval”. Communications of the ACM, 26(11):1022-1036. Noviembre, 1983
[64] Waller, W. G. y Kraft, D. H. “A mathematical model for a weighted Boolean retrieval system”. Information Processing and Management, Vol 15, No. 5, pp. 235-245. 1979.
Los SRI (sistemas de recuperación de información)toman un conjunto de documentos (colección) para procesar y luego poder responder consultas. De forma básica, podemos clasificar los documentos en estructurados y no estructurados. Los primeros son aquellos en los que se pueden reconocer elementos estructurales con una semántica bien definida, mientras que los segundos corresponden a texto libre, sin formato. La diferencia fundamental de un SRI que procese documentos estructurados se encuentra en que puede extraer información adicional al contenido textual, la cual utiliza en la etapa de recuperación para facilitar la tarea y aumentar las prestaciones.
A partir de lo expresado anteriormente se presenta una posible clasificación de modelos de RI – la cual no es exhaustiva – de acuerdo a características estructurales de los documentos.

A continuación se describen – de forma somera – los modelos clásicos y el álgebra de regiones. Más adelante, en el capítulo 4, se profundizará en los modelos booleano y vectorial.
1. Modelo booleano
En el modelo booleano la representación de la colección de documentos se realiza sobre una matriz binaria documento–término, donde los términos han sido extraídos manualmente o automáticamente de los documentos y representan el contenido de los mismos.
Las consultas se arman con términos vinculados por operadores lógicos (AND, OR, NOT) y los resultados son referencias a documentos donde cuya representación satisface las restricciones lógicas de la expresión de búsqueda. En el modelo original no hay ranking de relevancia sobre el conjunto de respuestas a una consulta, todos los documentos poseen la misma relevancia. A continuación se muestra un ejemplo mediante conjuntos de operaciones utilizando el modelo booleano.
A = {Documentos que contienen el término T1}
B = {Documentos que contienen el término T2}

Si bien es el primer modelo desarrollado y aún se lo utiliza, no es el preferido por los ingenieros de software para sus desarrollos. Existen diversos puntos en contra que hacen que cada día se lo utilice menos y – además – se han desarrollado algunas extensiones, bajo el nombre modelo booleano extendido [64] [51], que tratan de mejorar algunos puntos débiles.
2. Modelo Vectorial
Este modelo fue planteado y desarrollado por Gerard Salton [49] y – originalmente – se implementó en un SRI llamado SMART. Aunque el modelo posee más de treinta años, actualmente se sigue utilizando debido a su buena performance en la recuperación de documentos.
Conceptualmente, este modelo utiliza una matriz documento–término que contiene el vocabulario de la colección de referencia y los documentos existentes. En la intersección de un término t y un documento d se almacena un valor numérico de importancia del término t en el documento d; tal valor representa su poder de discriminación. Así, cada documento puede ser visto como un vector que pertenece a un espacio n-dimensional, donde n es la cantidad de términos que componen el vocabulario de la colección. En teoría, los documentos que contengan términos similares estarán a muy poca distancia entre sí sobre tal espacio. De igual forma se trata a la consulta, es un documento más y se la mapea sobre el espacio de documentos. Luego, a partir de una consulta dada es posible devolver una lista de documentos ordenados por distancia (los más relevantes primero). Para calcular la semejanza entre el vector consulta y los vectores que representan los documentos se utilizan diferentes fórmulas de distancia, siendo la más común la del coseno.
Obsérvese el siguiente ejemplo donde se representa a un documento d y a una consulta c:
Documento: “La República Argentina ha sido nominada para la realización del X Congreso Americano de Epidemiología en Zonas de Desastre. El evento se realizará ...”
Consulta: “argentina congreso epidemiología”

3. Modelo probabilístico
Fue propuesto por Robertson y Spark-Jones [47] con el objetivo de representar el proceso de recuperación de información desde el punto de vista de las probabilidades. A partir de una expresión de consulta se puede dividir una colección de N documentos en cuatro subconjuntos distintos: REL conjunto de documentos relevantes, REC conjunto de documentos recuperados, RR conjunto de documentos relevantes recuperados y NN el conjunto de documentos no relevantes no recuperados.
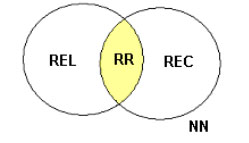
El resultado ideal de a una consulta se da cuando el conjunto REL es igual REC. Como resulta difícil lograrlo en primera intención, el usuario genera una descripción probabilística del conjunto REL y a través de sucesivas interacciones con el SRI se trata de mejorar la perfomance de recuperación. Dado que una recuperación no es inmediata dado que involucra varias interacciones con el usuario y que estudios han demostrado que su perfomance es inferior al modelo vectorial, su uso es bastante limitado.
4. Modelos para documentos estructurados
Los modelos clásicos responden a consultas, buscando sobre una estructura de datos que representa el contenido de los documentos de una colección, únicamente como listas de términos significativos. Un modelo de recuperación de documentos estructurados utiliza la estructura de los mismos a los efectos de mejorar la performance y brindar servicios alternativos al usuario (por ejemplo, uso de memoria visual, recuperación de elementos multimedia, mayor precisión sobre el ámbito de la consulta y demás).
La estructura de los documentos a indexar está dada por marcas o etiquetas, siendo los estándares más utilizados el SGML (Standard General Markup Language), el HTML (HyperText Markup Language), el XML (eXtensible Markup Language) y LATEX.
Al poseer la descripción de parte de la estructura de un documento es posible generar un grafo sobre el que se navegue y se respondan consultas de distinto tipo, por ejemplo:
–Por estructura: ¿Cuáles son las secciones del segundo capítulo?
–Por metadatos o campos: Documentos de “Editorial UNLu” editados en 1998
–Por contenido: Término “agua” en títulos de secciones
–Por elementos multimedia: Imágenes cercanas a párrafos que contengan Bush
Para Baeza-Yates existen dos modelos en esta categoría “nodos proximales” [37] y “listas no superpuestas” [8]. Ambos modelos se basan en almacenar las ocurrencias de los términos a indexar en estructuras de datos diferentes, según aparezcan en algún elemento de estructura (región) o en otro como capítulos, secciones, subsecciones y demás. En general, las regiones de una misma estructura de datos no poseen superposición, pero regiones en diferentes estructuras sí se pueden superponer.
Nótese que en el ejemplo anterior existen cuatro niveles de listas para almacenar información relativa a contenido textual y estructura de un documento tipo libro. En general, los tipos de consultas soportados son simples:
· Seleccione una región que contenga una palabra dada
· Seleccione una región X que no que no contenga una región Y
· Seleccione una región contenida en otra región
Sobre el ejemplo de estructura planteado un ejemplo de consulta sería:
[subsección[+] CONTIENE “‘tambo” ]
Como respuesta el SRI buscaría subsecciones y sub-subsecciones que contengan el término “tambo“.
Cabe mencionar que algunos motores de búsqueda de Internet ya utilizan ciertos elementos de la estructura de un documento – por ejemplo, los títulos – a los efectos de realizar tareas de rankeo, resumen automático, clasificación y otras.
La expansión de estos lenguajes de demarcación, especialmente en servicios sobre Internet, hacen que se generen y publiquen cada vez más documentos semiestructurados. Es necesario – entonces – desarrollar técnicas que aprovechen el valor agregado de los nuevos documentos. Si bien – en la actualidad – éstas no se encuentran tan desarrolladas como los modelos tradicionales, consideramos su evolución como una cuestión importante en el área de RI, especialmente a partir de investigaciones con enfoques diferentes que abordan la problemática [18] [38] [45].
Referencias
[8] Burkowski, F. “Retrieval activities in a database consisting of heterogeneous collections of structured texts”. In Belkin, N., Ingwersen, P., Pejtersen, A. M., and Fox, E., editors, Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 112–125, New York. ACM Press. 1992.
[18] Egnor, D. y Lord, R. “Structured information retrieval using XML”. En: Proceedings of the ACM SIGIR 2000 Workshop on XML and Information Retrieval, Julio 2000.
[37] Navarro, G. y Baeza-Yates, R. “A language for queries on structure and contents of textual databases”. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 93-101, New York. ACM Press. 1995.
[38] Ogilvie, P. y Callan, J. “Language Models and Structured Document Retrieval”. En: Proceedings of the first INEX workshop, 2003.
[45] Raghavan, S. Y Garcia-Molina, H. “Integrating diverse information management systems: A brief survey”. IEEE Data Engineering Bulletin, 24(4):44-52, 2001.
[47] Robertson, S.E y Spark-Jones, K. “Relevance Weighting of Search terms”. Journal of Documentation. 33, p.126-148. 1976.
[49] Salton, G. (editor). “The SMART Retrieval System – Experiments in Automatic Document Processing”. Prentice Hall In. Englewood Cliffs, NJ. 1971.
[51] Salton, G.; Fox, E.A. y Wu, H. “Extended Boolean information retrieval”. Communications of the ACM, 26(11):1022-1036. Noviembre, 1983
[64] Waller, W. G. y Kraft, D. H. “A mathematical model for a weighted Boolean retrieval system”. Information Processing and Management, Vol 15, No. 5, pp. 235-245. 1979.
WikiSym 2006
WikiSym es un Simposio Internacional sobre Wikis donde se presentan investigaciones académicas y se discute en mesas redondas distintos aspectos de esta temática. El evento correspondiente al año 2006 se realizó Dinamarca con el aval de la asociación ACM. En este enlace pueden hallar las presentaciones correspondientes.
Walles y la razón de éxito de Wikipedia
En una entrevista para la revista Nature [Roxanne Khamsi, Wikipedia co-founder Jimmy Wales offers a whole new species of information online. ,BioEd Online] , Walles expresa que como experiencia previa a Wikipedia “... fundamos Nupedia, pero se tenía proceso de revisión extremadamente complicado, era un trabajo verticalista y muy académico, donde no se consideraba el aporte de voluntarios. Este modelo tradicional de alto control simplemente no funcionó. Luego nos enteramos del modelo colaborativo wiki, el cual era excelente. Cuando Wikipedia comenzó a funcionar se transformó rápidamente en un éxito. En dos semanas conseguimos hacer más trabajo que el que teníamos realizado en dos años...". Tras analizar los conceptos anteriores cabe preguntarse si la nueva enciclopedia Citizendium, la cual como característica principal presenta un modelo más rígido de control de los artículos, por parte de académicos, tendrá viabilidad ?.
domingo, noviembre 19, 2006
Ranking de penetración de Internet en América Latina
A partir de un informe sobre el estado de desarrollo de Internet el la región, presentado en la Conferencia de Naciones Unidas para el Comercio y el Desarrollo (UNCTAD), se observa que la república Argentina está en el tercer lugar en el ranking de penetración de Internet en América Latina. Los números indican que 17,7 argentinos de cada 100 se conectan a la red (la noticia indica que es una cifra superior al promedio mundial la cual es 15,6%). De los 17,7 sólo 2,2 argentinos lo hacen por banda ancha.
Sobre un total 89,13 millones de conexiones a Internet en total en Latino América y el Caribe se tiene el siguiente ranking.
1 Bermudas 65,4 usuarios cada 100 habitantes
2 Barbados 59,4 usuarios
3 Antigua y Barbuda 35,6 usuarios
4 Bahamas 31,9 usuarios
5 Dominica 32,9 usuarios
6 Martinica 32,8 usuarios,
7 Costa Rica 25,4 usuarios
8 Guayana 21,3 usuarios
9 Brasil 19,5 usuarios
10 Uruguay 19,3 usuarios
11 Argentina 17,7 usuarios
Creo que en Centro América y el Caribe la alta tasa se debe a la baja densidad de población sumado a la oferta de opciones turísticas destinadas a norteamericanos y europeos.
Las conexiones de Brasil y México suman el 60% de todas y un 25% la tienen Argentina, Chile, Colombia, Perú y Venezuela. Con respecto a desarrollo de tecnologías de conexión se sabe que en banda ancha Chile, tiene la mayor penetración 4,3 %, Argentina y México 2,2%, Brasil y Uruguay 1,8%, Venezuela 1,3%, Perú 1,2%, Colombia y República Dominicana 0,7%, El Salvador 0,6%, Panamá 0,5%, Ecuador y Nicaragua 0,2 % y Bolivia Paraguay 0,1%.
Fuente: Infobaeprofesional.com
Sobre un total 89,13 millones de conexiones a Internet en total en Latino América y el Caribe se tiene el siguiente ranking.
1 Bermudas 65,4 usuarios cada 100 habitantes
2 Barbados 59,4 usuarios
3 Antigua y Barbuda 35,6 usuarios
4 Bahamas 31,9 usuarios
5 Dominica 32,9 usuarios
6 Martinica 32,8 usuarios,
7 Costa Rica 25,4 usuarios
8 Guayana 21,3 usuarios
9 Brasil 19,5 usuarios
10 Uruguay 19,3 usuarios
11 Argentina 17,7 usuarios
Creo que en Centro América y el Caribe la alta tasa se debe a la baja densidad de población sumado a la oferta de opciones turísticas destinadas a norteamericanos y europeos.
Las conexiones de Brasil y México suman el 60% de todas y un 25% la tienen Argentina, Chile, Colombia, Perú y Venezuela. Con respecto a desarrollo de tecnologías de conexión se sabe que en banda ancha Chile, tiene la mayor penetración 4,3 %, Argentina y México 2,2%, Brasil y Uruguay 1,8%, Venezuela 1,3%, Perú 1,2%, Colombia y República Dominicana 0,7%, El Salvador 0,6%, Panamá 0,5%, Ecuador y Nicaragua 0,2 % y Bolivia Paraguay 0,1%.
Fuente: Infobaeprofesional.com
sábado, noviembre 18, 2006
Material de clase sobre Data Mining
Para todos aquellos que le interese profesionalmente o en su vida de estudiante este apasionante tema, les recomiendo consultar las notas de clase de los profesores Rajamaran y Ullman en Stanford. Hay buen material para indagar sobre posibles temas de tesinas y trabajos finales.
Sitio colaborativo sobre noticias relacionadas con la bibliotecología
Documenea es un portal basado en filtrado colaborativo y recomendaciones de enlaces que trata el dominio la documentación.
viernes, noviembre 17, 2006
Uso de Google, por parte de médicos, como fuente de consulta de su profesión
Un artículo de investigación titulado “Googling for a diagnosis--use of Google as a diagnostic aid: internet based study” de Hangwi Tang y Jennifer Hwee Kwoon es el resultado de una experiencia que tuvo por objetivo determinar cuánto podría servir la web como fuente de consulta de casos difíciles. En sus conclusiones se indica, textualmente, que “…the web is rapidly becoming an important clinical tool for doctors. The use of web based searching may help doctors to diagnose difficult cases…”
Trabajos en línea de la “Conferencia Semantic Web”
La semana pasada terminó la 5th International Semantic Web Conference, la cual se realizó en Athens, USA. En la página pueden hallar los papers que se presentaron en el encuentro.
jueves, noviembre 16, 2006
Proyecto social OpenStreetMap
Proyecto creado por Steve Coast en el año 2004 destinado a proveer de forma gratuita datos geográficos de todas partes del m undo, que utiliza un gestor wiki como organizador de contenidos. Debido a que en varios países distintas organizaciones cobran por la provisión de datos georeferenciados, un grupo de usuarios de tal información ha generado y mantenido este emprendimiento de carácter social. La comunidad OpenStreetMaps está creando mapas y habilitando el uso libre de los mismos; esto se logra debido a que algunos usuarios aportan datos, de su región geográfica, tomados con su GPS personal y otros se dedican a la edición (en línea o no) de mapas con herramientas y una metodología provista por la organización. Hoy la forma legal que tomo el proyecto para su administración y desarrollo es la de fundación sin fines de lucro.
miércoles, noviembre 15, 2006
La interacción del usuario con el Sistema de recuperación de Información (SRI)
Aquí sigo con la idea de presentar algunas partes del libro que he escrito con Gabriel Tolosa, titulado “Introducción a la Recuperación de Información”.
La tarea de recuperar información puede ser planteada de diversas formas, de acuerdo a cómo el usuario interactúa con el sistema o bien qué facilidades éste le brinda. Básicamente, la tarea se la puede dividir en:
1) Recuperación inmediata: El usuario plantea su necesidad de información y – a continuación – obtiene referencias a los documentos que el sistema evalúa como relevantes. Existen dos modalidades:
a) Búsqueda (propiamente dicha) o recuperación “ad-hoc”, donde el usuario formula una consulta en un lenguaje y el sistema la evalúa y responde. En este caso, el usuario tiene suficiente comprensión de su necesidad y sabe cómo expresar una consulta al sistema. Un ejemplo clásico son los buscadores de Internet como Google, Altavista o AllTheWeb.
b) Navegación o browsing: En este caso, el usuario utiliza un enfoque diferente al anterior. El sistema ofrece una interface con temas donde el usuario “navega” por dicha estructura y obtiene referencias a documentos a relacionados. Esto facilita la búsqueda a usuarios que no pueden definir claramente cómo comenzar con su consulta e – inclusive – van definiendo su necesidad a medida que observan diferentes documentos. Es este enfoque no se formula consulta explícita. Un ejemplo típico es el proyecto Open Directory.
En ambos casos, la colección es relativamente estática, es decir, se parte de un conjunto de documentos y la aparición de nuevos no es muy significativa. Por otro lado, las consultas son las que se van modificando ya que este proceso es proactivo por parte del usuario.
2) Recuperación diferida: El usuario especifica sus necesidades y el sistema entregará de forma continua los nuevos documentos que le lleguen y concuerden con ésta. Esta modalidad recibe el nombre de filtrado y ruteo y la necesidad del usuario – generalmente – define un “perfil” (profile) de los documentos buscados. Nótese que un “perfil” es – de alguna forma – un query y puede ser tratado como tal. Cada vez que un nuevo documento arriba al sistema se compara con el perfil y – si es relevante – se envía al usuario. Un ejemplo, es el servicio provisto por la empresa Indigo Stream Technologies denominado GoogleAlert.
En esta modalidad la consulta es relativamente estática (corresponde al profile) y el usuario tiene un rol pasivo. El dinamismo está dado por la aparición de nuevos documentos y es lo que determina mas resultados para el usuario.
En algunos casos, se plantea que documentos y consultas son objetos de la misma clase por lo que estos enfoques son – de alguna manera – visiones diferentes de una misma problemática. Bajo este punto de vista, documentos y consultas se pueden intercambiar. Sin embargo, esto no es siempre posible debido al tratamiento que se aplica a cada uno en diferentes sistemas. Algunos sistemas representan queries y documentos de diferente manera. Es más, existe una diferencia obvia en cuanto a la longitud de uno y otro que se tiene en cuenta bajo ciertos modelos de recuperación. Finalmente, en un sistema de búsqueda, existe el concepto de ranking de los documentos respuesta, mientras que en un modelo de filtrado, cada nuevo objeto es relevante a un perfil o no.
martes, noviembre 14, 2006
Según Netcraft, en el espacio web, existen alrededor de 100 millones de sitios
Una noticia de la CNN (aportada por Baquía) comenta que Internet alcanzó en el mes de octubre los 100 millones de sitios web (nótese que en el mes de setiembre se registraron 3.5 millones de nuevos sitios). Se verificó que ha doblado su tamaño desde mayo de 2005. El estudio indica que solo la mitad son web activas. Netcraft, empresa que realizó el estudio, aventuró a explicar este fenómeno, argumentando que los weblogs y los sitios web de pequeñas empresas y negocios son los principales contribuidores del número mencionado. Para Netcraft, los países donde se registró mayor crecimiento son USA, China, Alemania, Korea del Sur y Japón.
lunes, noviembre 13, 2006
Cómo son las busquedas de los investigadores en revistas electrónicas?
“Searching for electronic journal articles to support academic tasks” es el título de un artículo de investigación de Vakkari y Talja recientemente publicado. El estudio se focalizó sobre el uso de material en la Biblioteca Electrónica Nacional Finlandesa (FinELib). En la investigación se analiza cómo la jerarquía académica y el área de trabajo influencian las las estrategias de búsqueda utilizadas por el personal académico.
La principal conclusión indica que los patrones de búsqueda de artículos están cambiando debido a que hay un incremento en la disponibilidad de fuentes y posibilidades de acceso a material electrónico. Otros extractos interesantes son:
“Our results seem to confirm the findings (Tenopir et al. 2003) that in the electronic information environment, browsing journals is replaced by subject searching in databases. Searching both in full-text and reference databases was considered a considerably more important method of accessing journal literature than browsing journals.”
“There were some differences in search methods used for these tasks by academic status. First, younger researchers rely significantly more on keyword searching than senior researchers for finding journal articles for research purposes.”
Cita: Pertti Vakkari and Sanna Talja: “Searching for electronic journal articles to support academic tasks. A case study of the use of the Finnish National Electronic Library (FinELib)” in Information Research, Vol. 12 No. 1, October 2006.
domingo, noviembre 12, 2006
Para algunas universidades la enseñanza de la informática no sólo es cosmética
Estaba revisando mis canales RSS y me topé con una noticia (del canal CFI) la cual trata el tema de la promoción de desarrollo de software como estrategia para complementar la formación de alumnos de una carrera de informática.
El tema en cuestión viene de que la Universidad de Sevilla organizó un concurso de desarrollo de software libre y recibió casi 100 proyectos provenientes de grupos de alumnos de toda españa.
Como dicen ellos, y la tienen clara, "...este certamen tiene como objetivo involucrar a los estudiantes universitarios en la participación y creación de proyectos de software libre para que, de esta forma, se creen las condiciones idóneas para generar un tejido tecnológico de futuros profesionales capaces de dar soporte de soluciones basadas en software libre a empresas e instituciones...". Que buenos estos tíos, se dedican a enseñar y no a decir que enseñan o hacer cosmética educativa.
Que el ejemplo nos colonice.
El tema en cuestión viene de que la Universidad de Sevilla organizó un concurso de desarrollo de software libre y recibió casi 100 proyectos provenientes de grupos de alumnos de toda españa.
Como dicen ellos, y la tienen clara, "...este certamen tiene como objetivo involucrar a los estudiantes universitarios en la participación y creación de proyectos de software libre para que, de esta forma, se creen las condiciones idóneas para generar un tejido tecnológico de futuros profesionales capaces de dar soporte de soluciones basadas en software libre a empresas e instituciones...". Que buenos estos tíos, se dedican a enseñar y no a decir que enseñan o hacer cosmética educativa.
Que el ejemplo nos colonice.
Suscribirse a:
Comentarios (Atom)
