Hoy 31 de agosto, es el denominado BlogDay, un día donde los autores de blogs presentan en sociedad 5 blogs interesantes. Aquí van los mios, pero con una pequeña variante, 5 en español y 5 en inglés (lamento no poder acceder a otras lenguas).
En español:
Google Dirson: EL cual presenta noticias de Google en español
Barrapunto: Noticias tecnológicas
Aventuras_de_un_webmaster: EL título habla
OjoBuscador: Blog sobre motores de búsqueda y posicionamiento.
Blog de Fernando Tamames
En inglés:
ScienceBlogs:
TechDir: tech news
Search Engine Watch Blog:
Sifry's Alerts:
Techcrunch:
jueves, agosto 31, 2006
Netcraft plantea que Apache ultimamente perdió una parte de mercado
Netcraft es un sitio dedicado a monitorear servicios webs del planeta. Entre sus aportes a la minería de datos mide la evolución de hosts, servidores, marcas de web servers, etc. A continuación se puede observar el gráfico de "Market Share for Top Servers Across All Domains August 1995 - August 2006" perteneciente a agosto del 2006.
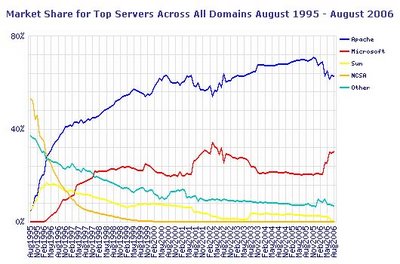
Marca Agosto 2006 Porcentaje
Apache 57.906.817 62.52
Microsoft 27.905.439 30.13
Zeus 521.619 0.56
Sun 344.862 0.37
Charlé esto con Fernando Lorge, debido a que no había comentarios públicos sobre esta aparente pérdida de mercado. Fernando me comentó que hace un tiempo había leido algo respecto a una empresa que se dedica a reservar nombres de dominios. Donde planteaba que en esta organización cambiaron de infraestructura tecnológica pasando a Microsoft Web Server los servidores Apache que tenían (1,6 millones de idle parked domains). Como cada servidor físico hostea miles de dominios para la venta, este cambio influyó bastante en las estadísticas de Netcraft.
En resumen, parece que los webmasters no han cambiado de plataforma, aparentemente este fenómeno tiene que ver con una empresa que vende dominios y utiliza millones de sitios como vidriera de sus productos.

Marca Agosto 2006 Porcentaje
Apache 57.906.817 62.52
Microsoft 27.905.439 30.13
Zeus 521.619 0.56
Sun 344.862 0.37
Charlé esto con Fernando Lorge, debido a que no había comentarios públicos sobre esta aparente pérdida de mercado. Fernando me comentó que hace un tiempo había leido algo respecto a una empresa que se dedica a reservar nombres de dominios. Donde planteaba que en esta organización cambiaron de infraestructura tecnológica pasando a Microsoft Web Server los servidores Apache que tenían (1,6 millones de idle parked domains). Como cada servidor físico hostea miles de dominios para la venta, este cambio influyó bastante en las estadísticas de Netcraft.
En resumen, parece que los webmasters no han cambiado de plataforma, aparentemente este fenómeno tiene que ver con una empresa que vende dominios y utiliza millones de sitios como vidriera de sus productos.
Interfaces alternativas de visualización
Mauro, un colaborador del Laboratorio de Redes, me acaba de acercar algunos enlaces pertenecientes a páginas web que presentan formas alternativas de visualizar noticias.
En particular Newsmap es una aplicación que de forma gráfica refleja los cambios en el servicio Google News Aggregator. A partir de una combinación de colores, tamaños y tipos de letras es posible mostrar de forma simpplificada un importante monto de información. Sus creadores dicen que "... objective is to simply demonstrate visually the relationships between data and the unseen patterns in news media. It is not thought to display an unbiased view of the news; on the contrary, it is thought to ironically accentuate the bias of it.". Los mapas se generan a partir del concepto de treemaps, que es una técnica que tiene por objetivo facilitar la visualización de estructuras jerárquicas.

En particular Newsmap es una aplicación que de forma gráfica refleja los cambios en el servicio Google News Aggregator. A partir de una combinación de colores, tamaños y tipos de letras es posible mostrar de forma simpplificada un importante monto de información. Sus creadores dicen que "... objective is to simply demonstrate visually the relationships between data and the unseen patterns in news media. It is not thought to display an unbiased view of the news; on the contrary, it is thought to ironically accentuate the bias of it.". Los mapas se generan a partir del concepto de treemaps, que es una técnica que tiene por objetivo facilitar la visualización de estructuras jerárquicas.

miércoles, agosto 30, 2006
Se viene SPIRE 2006
En octubre, en Glasgow, se realizará el décimo tercer Simposio en String Processing and Information Retrieval SPIRE 2006. Este evento es uno de los más importantes en recuperación de información. Hay que estar atento a la lista de trabajos aceptados dado que, junto con SIGIR, marcan la tendencia en líneas de investigación. La dirección del sitio oficial del evento es http://www.cis.strath.ac.uk/external/spire06/
Microsoft lanzó la versión final de su servicio de respuestas a preguntas
Microsoft lanzó la versión final de su servicio de respuestas a preguntas. Como Yahoo, Microsoft ya tiene su sitio "Windows Live QnA" [http://qna.live.com/] donde los usuarios pueden hacer consultas ,en lenguaje natural, que necesiten respuestas precisas (en qué año, dónde vive, qué es).
De nuevo los geotags
Hace algunos días en este blog escribí algo [http://ferbor.blogspot.com/2006/08/conocen-tagzania.html] sobre las etiquetas geográficas y sistemas de navegación que las soportan. En especial sobre Tagzania. Parece que Flickr venía trabajando en este tema y hace un par de días habilitó su servicio, [http://www.techcrunch.com/2006/08/29/12-million-flickr-photos-geotagged-in-24-hours/] sobre una infraestructura de Yahoo similar a Google Maps. Qué paso? en 24 horas más de 1,2 millones de fotos fueron etiquetadas con metadatos. Si quieren ver el servicio vayan a http://www.flickr.com/map
martes, agosto 29, 2006
Enlaces a cursos de IR
Estos días estuve viendo como es la dinámica de los programas de cursos de IR en distintas universidades del mundo. En particular me interesa observar si se están adaptando a los conceptos de servicio derivados de la web 2.0. Ya que estamos les paso enlaces a algunas cátedras que me parecieron interesantes:
* De Paul University
* Universidad de texas
* Sharif University of Technology
* Grupo Reina
* UNED
* De Paul University
* Universidad de texas
* Sharif University of Technology
* Grupo Reina
* UNED
lunes, agosto 28, 2006
Recomendaciones de Jakob Nielsen para seleccionar palabras claves
Jakob Nielsen es un referente en usabilidad. En su blog ha escrito un artículo acerca de como se deben seleccionar las keywords representativas de una página o un documento. Es una lectura interesante de un tipo que usa el sentido común.
Google & Writely. El editor de textos online
Writely es una aplicación que permite editar y compartir documentos a
través del browser. Ya es posible acceder a una demo sin necesidad de
invitación (como sucededía hasta hace un tiempo atrás).
La idea es establecer escritorios personales donde los usuarios trabajen
en línea, con sus propios grupos de trabajo. Writely se suma a este espacio
donde previamente estaba la planilla electrónica de Google.
través del browser. Ya es posible acceder a una demo sin necesidad de
invitación (como sucededía hasta hace un tiempo atrás).
La idea es establecer escritorios personales donde los usuarios trabajen
en línea, con sus propios grupos de trabajo. Writely se suma a este espacio
donde previamente estaba la planilla electrónica de Google.
domingo, agosto 27, 2006
Merecido reconocimiento a Kleinberg
En el marco del Congreso Mundial de Matemáticas, realizado en Madrid, se entregaron los Fields. El Premio Nevanlinna fue para Jon Kleinberg debido a sus estudios relativos a las búsquedas en el espacio web..
Hace algunos años Kleinberg desarrolló de un algoritmo semejante a Pagerank, denominado HITS. El método permite identificar dos tipos de páginas a)las autoridades (páginas que reciben muchos enlaces generalmente de buenos hubs) y b) los hubs (conectores, páginas que dan acceso a páginas con mucha autoridad). La idea base indica que los enlaces armados por personas con intereses afines que tienden a enlazar a las autoridades de una misma temática. El cálculo se realiza con recursividad y en cada vuelta se produce una retroalimentación en el valor de hub y autoridad de cada página. Esto sigue así hasta llegar a un valor estabilización (parecido a pagerank en su forma de convergencia). Si hay interés aquí pueden acceder al paper de HITS "Authoritative Sources in a Hyperlinked Environment". En Perl, en el repositorio CPAN hay un buen módulo que implementa HITS y se lo puede utilizar para ejemplificar su funcionamiento.
Hace algunos años Kleinberg desarrolló de un algoritmo semejante a Pagerank, denominado HITS. El método permite identificar dos tipos de páginas a)las autoridades (páginas que reciben muchos enlaces generalmente de buenos hubs) y b) los hubs (conectores, páginas que dan acceso a páginas con mucha autoridad). La idea base indica que los enlaces armados por personas con intereses afines que tienden a enlazar a las autoridades de una misma temática. El cálculo se realiza con recursividad y en cada vuelta se produce una retroalimentación en el valor de hub y autoridad de cada página. Esto sigue así hasta llegar a un valor estabilización (parecido a pagerank en su forma de convergencia). Si hay interés aquí pueden acceder al paper de HITS "Authoritative Sources in a Hyperlinked Environment". En Perl, en el repositorio CPAN hay un buen módulo que implementa HITS y se lo puede utilizar para ejemplificar su funcionamiento.
sábado, agosto 26, 2006
La problemática de la Recuperación de Información
Continuando con la idea de presentar algunas partes del libro que he escrito con Gabriel Tolosa, titulado “Introducción a la Recuperación de Información”, aquí se transcribe la sección denominada “La problemática de la recuperación de información”.
De forma general – según Baeza-Yates [1] – el problema de la RI puede ser estudiado desde dos puntos de vista: el computacional y el humano. El primer caso tiene que ver con la construcción de estructuras de datos y algoritmos eficientes que mejoren la calidad de las respuestas. El segundo caso corresponde al estudio del comportamiento y de las necesidades de los usuarios.

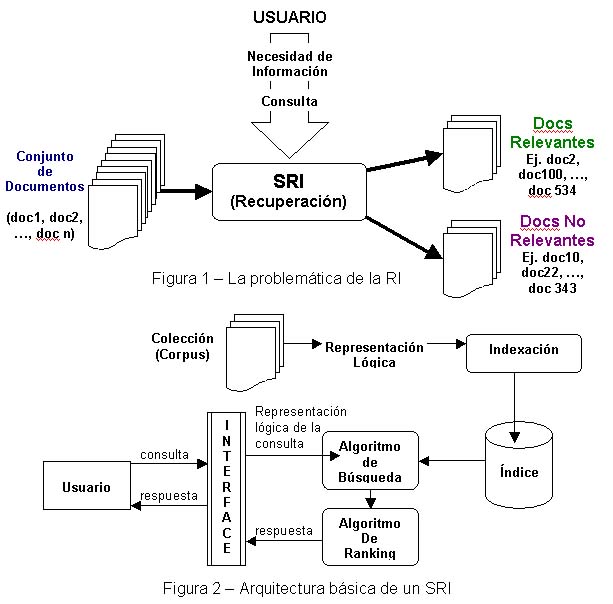
Si se analiza la problemática de la RI desde un alto nivel de abstracción (Figura 1) podemos establecer que:
– Existe una colección de documentos que contienen información de interés (sobre uno o varios temas)
– Existen usuarios con necesidades de información, quienes las plantean al SRI en forma de una consulta (en inglés, query. En adelante, ambas palabras se utilizarán indistintamente)
– Como respuesta, el sistema retorna – de forma ideal – referencias a documentos “relevantes”, es decir aquellos que satisfacen la necesidad expresada, generalmente en forma de una lista rankeada.
Planteamos que la respuesta “ideal” de un SRI está formada solamente por documentos relevantes a la consulta, pero – en la práctica – esta no es aún alcanzable. Esto se debe a que – entre otros motivos – existe el problema de compatibilizar la expresión de la necesidad de información y el lenguaje y de los documentos. Además, hay una carga de subjetividad subyacente y depende de los usuarios. Entonces, el SRI recupera la mayor cantidad posible de documentos relevantes, minimizando la cantidad de documentos no relevantes (ruido) en la respuesta. En términos de eficiencia, se plantea la idea de precisión de la respuesta, es decir, cuando más documentos relevantes contenga el conjunto solución (para una consulta dada), más preciso será.
Para cumplir con sus objetivos, un SRI debe realizar algunas tareas básicas, las cuales se encuentran – fundamentalmente – planteadas en cuestiones computacionales, a saber:
– Representación lógica de los documentos y – opcionalmente – almacenamiento del original. Algunos sistemas solo almacenan porciones de los documentos y otros lo hacen de manera completa.
– Representación de la necesidad de información del usuario en forma de consulta.
– Evaluación de los documentos respecto de una consulta para establecer la relevancia de cada uno.
– Rankeo de los documentos considerados relevantes para formar el “conjunto solución” o respuesta.
– Presentación de la respuesta al usuario.
– Retroalimentación o refinamiento de las consultas (para aumentar la calidad de la respuesta)
En la figura 2 se puede apreciar con mayor detalle la arquitectura básica de un SRI, el tratamiento de los documentos y la interacción con el usuario. Aquí se ven algunos componentes que no se habían mencionado hasta el momento.
Como podemos observar, se parte de un conjunto de documentos de texto, los cuales están compuestos por sucesiones de palabras que forman estructuras gramaticales (por ejemplo, oraciones y párrafos). Tales documentos están escritos en lenguaje natural y expresan ideas de su autor sobre un determinado tema. El conjunto de todos los documentos con los que se trata y sobre los que se deben realizar operaciones de RI se denomina corpus, colección o base de datos textual o documental. Para poder realizar operaciones sobre un corpus, es necesario obtener primero una representación lógica de todos sus documentos, la cual puede consistir en un conjunto de términos, frases u otras unidades (sintácticas o semánticas) que permitan – de alguna manera – caracterizarlos. Por ejemplo, la representación de los documentos mediante un conjunto de sus términos se la conoce como “bolsa de palabras” (bag of words).
A partir de la representación lógica existe un proceso (indexación) que llevará a cabo la construcción de estructuras de datos (normalmente denominadas índices) que la almacene y soporte búsquedas eficientes. Es importante destacar que una vez construidos los índices, los documentos del corpus pueden ser eliminados del sistema ya que éste retornará las referencias a los mismos debido a que cuenta con la información necesaria para hacerlo. En tal caso, el usuario será el encargado de localizar el documento para consultarlo. A los sistemas que funcionan bajo este modelo se los denomina “sistemas referenciales”, en contraste con los que sí almacenan y mantienen los documentos denominados “sistemas documentales” [2]. Un ejemplo de sistemas referenciales son algunos de los motores de búsqueda web, que retornan una lista de urls a los documentos, como – por ejemplo – Altavista Un caso particular es el motor de búsqueda Google el cual – en algunos casos – almacena en memoria caché el documento completo, el cual puede ser consultado durante cierto tiempo, incluso si ha desaparecido del sitio original.
El algoritmo de búsqueda acepta como entrada una expresión de consulta o query de un usuario y verificará en el índice cuáles documentos pueden satisfacerlo. Luego, un algoritmo de ranking determinará la relevancia de cada documento y retornará una lista con la respuesta. Se establece que el primer ítem de dicha lista corresponde al documento más relevante respecto de a la consulta y así sucesivamente en orden decreciente.
La interface de usuario permite que éste especifique la consulta mediante una expresión escrita en un lenguaje preestablecido y – además – sirve para mostrar las respuestas retornadas por el sistema.
Si bien hasta aquí se planteó la tarea básica de la RI y la arquitectura general de un SRI, el área es muy amplia y abarca diferentes tópicos. En general, un SRI no entrega una respuesta directa a una consulta, sino que permite localizar referencias a documentos que pueden contener información útil. Pero éste es solo uno de los aspectos del área de RI en la actualidad, ya que se ha atacado el problema con una perspectiva más amplia, proponiendo y desarrollando estrategias y modelos para mejorar y aumentar la funcionalidad de los SRI. Entre otras, la RI abarca tópicos como:
– Modelos de Recuperación: La tarea de la recuperación puede ser modelada desde distintos enfoques, por ejemplo la estadística, el álgebra de boole, el álgebra de vectores, la lógica difusa, el procesamiento del lenguaje natural y demás.
– Filtrado y Ruteo: Es un área que permite la definición de perfiles de necesidades de información por parte de usuarios y ante el ingreso de nuevos documentos al SRI, se los analiza y se lo reenvía a quienes se estima que van a ser relevantes.
– Clasificación: Aquí se realiza la rotulación automática de documentos de un corpus en base a clases previamente definidas.
– Agrupamiento (Clustering): Es una tarea similar a la clasificación pero no existen clases predefinidas. El proceso automáticamente determinará cuáles son las particiones.
– Sumarización: Área que entiende sobre técnicas de extracción de aquellas partes (palabras, frases, oraciones, párrafos) que contienen la semántica que determina la esencia de un documento.
– Detección de novedades (Novelty Detection): Se basa en la determinación de la introducción de nuevos tópicos o temas a un SRI.
– Respuestas a Preguntas (Question Answering): Consiste en hallar aquellas porciones de texto de un documento que satisfacen expresamente a una consulta, es decir, la respuesta concreta a una pregunta dada.
– Extracción de Información: Extraer aquellas porciones de texto con una alta carga semántica y establecer relaciones entre los términos o pasajes extraídos.
– Recuperación cross-language: Hallar documentos escritos en cualquier lenguaje que son relevantes a una consulta expresada en otro lenguaje (búsqueda multilingual).
– Búsquedas Web: Se refiere a los SRI que operan sobre un corpus web privado (intranet) o público (Internet). La web ha planteado nuevos desafíos al área de RI, debido a sus características particulares como – por ejemplo – dinamismo y tamaño.
– Recuperación de Información Distribuida: A diferencia de los SRI clásicos donde el corpus y las estructuras de datos que auxilian a la búsqueda están centralizadas, aquí se plantea la tarea sobre los mismos elementos pero distribuidos sobre una red de computadoras.
– Modelado de Usuarios: Esta área – a partir de la interacción de los usuarios con un SRI – estudia como se generan de forma automática perfiles que definan las necesidades de información de éstos.
– Recuperación de Información Multimedia: Más allá de que los SRI tradicionales operan sobre corpus de documentos textuales, la recuperación de información tiene que tratar con otras formas alternativas de representación como imágenes, registro de conversaciones y video.
– Desarrollo de Conjuntos (data-sets) de Prueba: A los efectos de evaluar SRI completos o nuevos métodos y técnicas es necesario disponer de juegos de prueba normalizados (corpus con preguntas y respuestas predefinidas, corpus clasificados, etc.). Esta área tiene que ver con la producción tales conjuntos, a partir de diferentes estrategias que permitan reducir la complejidad de la tarea, manejando la dificultad inherente a la carga de subjetividad existente.
Referencias
[1] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[2] Peña, R., Baeza-Yates, R., Rodriguez, J.V. “Gestión Digital de la Información”. Alfaomega Grupo Editor. 2003.
De forma general – según Baeza-Yates [1] – el problema de la RI puede ser estudiado desde dos puntos de vista: el computacional y el humano. El primer caso tiene que ver con la construcción de estructuras de datos y algoritmos eficientes que mejoren la calidad de las respuestas. El segundo caso corresponde al estudio del comportamiento y de las necesidades de los usuarios.
Si se analiza la problemática de la RI desde un alto nivel de abstracción (Figura 1) podemos establecer que:
– Existe una colección de documentos que contienen información de interés (sobre uno o varios temas)
– Existen usuarios con necesidades de información, quienes las plantean al SRI en forma de una consulta (en inglés, query. En adelante, ambas palabras se utilizarán indistintamente)
– Como respuesta, el sistema retorna – de forma ideal – referencias a documentos “relevantes”, es decir aquellos que satisfacen la necesidad expresada, generalmente en forma de una lista rankeada.
Planteamos que la respuesta “ideal” de un SRI está formada solamente por documentos relevantes a la consulta, pero – en la práctica – esta no es aún alcanzable. Esto se debe a que – entre otros motivos – existe el problema de compatibilizar la expresión de la necesidad de información y el lenguaje y de los documentos. Además, hay una carga de subjetividad subyacente y depende de los usuarios. Entonces, el SRI recupera la mayor cantidad posible de documentos relevantes, minimizando la cantidad de documentos no relevantes (ruido) en la respuesta. En términos de eficiencia, se plantea la idea de precisión de la respuesta, es decir, cuando más documentos relevantes contenga el conjunto solución (para una consulta dada), más preciso será.
Para cumplir con sus objetivos, un SRI debe realizar algunas tareas básicas, las cuales se encuentran – fundamentalmente – planteadas en cuestiones computacionales, a saber:
– Representación lógica de los documentos y – opcionalmente – almacenamiento del original. Algunos sistemas solo almacenan porciones de los documentos y otros lo hacen de manera completa.
– Representación de la necesidad de información del usuario en forma de consulta.
– Evaluación de los documentos respecto de una consulta para establecer la relevancia de cada uno.
– Rankeo de los documentos considerados relevantes para formar el “conjunto solución” o respuesta.
– Presentación de la respuesta al usuario.
– Retroalimentación o refinamiento de las consultas (para aumentar la calidad de la respuesta)
En la figura 2 se puede apreciar con mayor detalle la arquitectura básica de un SRI, el tratamiento de los documentos y la interacción con el usuario. Aquí se ven algunos componentes que no se habían mencionado hasta el momento.
Como podemos observar, se parte de un conjunto de documentos de texto, los cuales están compuestos por sucesiones de palabras que forman estructuras gramaticales (por ejemplo, oraciones y párrafos). Tales documentos están escritos en lenguaje natural y expresan ideas de su autor sobre un determinado tema. El conjunto de todos los documentos con los que se trata y sobre los que se deben realizar operaciones de RI se denomina corpus, colección o base de datos textual o documental. Para poder realizar operaciones sobre un corpus, es necesario obtener primero una representación lógica de todos sus documentos, la cual puede consistir en un conjunto de términos, frases u otras unidades (sintácticas o semánticas) que permitan – de alguna manera – caracterizarlos. Por ejemplo, la representación de los documentos mediante un conjunto de sus términos se la conoce como “bolsa de palabras” (bag of words).
A partir de la representación lógica existe un proceso (indexación) que llevará a cabo la construcción de estructuras de datos (normalmente denominadas índices) que la almacene y soporte búsquedas eficientes. Es importante destacar que una vez construidos los índices, los documentos del corpus pueden ser eliminados del sistema ya que éste retornará las referencias a los mismos debido a que cuenta con la información necesaria para hacerlo. En tal caso, el usuario será el encargado de localizar el documento para consultarlo. A los sistemas que funcionan bajo este modelo se los denomina “sistemas referenciales”, en contraste con los que sí almacenan y mantienen los documentos denominados “sistemas documentales” [2]. Un ejemplo de sistemas referenciales son algunos de los motores de búsqueda web, que retornan una lista de urls a los documentos, como – por ejemplo – Altavista Un caso particular es el motor de búsqueda Google el cual – en algunos casos – almacena en memoria caché el documento completo, el cual puede ser consultado durante cierto tiempo, incluso si ha desaparecido del sitio original.
El algoritmo de búsqueda acepta como entrada una expresión de consulta o query de un usuario y verificará en el índice cuáles documentos pueden satisfacerlo. Luego, un algoritmo de ranking determinará la relevancia de cada documento y retornará una lista con la respuesta. Se establece que el primer ítem de dicha lista corresponde al documento más relevante respecto de a la consulta y así sucesivamente en orden decreciente.
La interface de usuario permite que éste especifique la consulta mediante una expresión escrita en un lenguaje preestablecido y – además – sirve para mostrar las respuestas retornadas por el sistema.
Si bien hasta aquí se planteó la tarea básica de la RI y la arquitectura general de un SRI, el área es muy amplia y abarca diferentes tópicos. En general, un SRI no entrega una respuesta directa a una consulta, sino que permite localizar referencias a documentos que pueden contener información útil. Pero éste es solo uno de los aspectos del área de RI en la actualidad, ya que se ha atacado el problema con una perspectiva más amplia, proponiendo y desarrollando estrategias y modelos para mejorar y aumentar la funcionalidad de los SRI. Entre otras, la RI abarca tópicos como:
– Modelos de Recuperación: La tarea de la recuperación puede ser modelada desde distintos enfoques, por ejemplo la estadística, el álgebra de boole, el álgebra de vectores, la lógica difusa, el procesamiento del lenguaje natural y demás.
– Filtrado y Ruteo: Es un área que permite la definición de perfiles de necesidades de información por parte de usuarios y ante el ingreso de nuevos documentos al SRI, se los analiza y se lo reenvía a quienes se estima que van a ser relevantes.
– Clasificación: Aquí se realiza la rotulación automática de documentos de un corpus en base a clases previamente definidas.
– Agrupamiento (Clustering): Es una tarea similar a la clasificación pero no existen clases predefinidas. El proceso automáticamente determinará cuáles son las particiones.
– Sumarización: Área que entiende sobre técnicas de extracción de aquellas partes (palabras, frases, oraciones, párrafos) que contienen la semántica que determina la esencia de un documento.
– Detección de novedades (Novelty Detection): Se basa en la determinación de la introducción de nuevos tópicos o temas a un SRI.
– Respuestas a Preguntas (Question Answering): Consiste en hallar aquellas porciones de texto de un documento que satisfacen expresamente a una consulta, es decir, la respuesta concreta a una pregunta dada.
– Extracción de Información: Extraer aquellas porciones de texto con una alta carga semántica y establecer relaciones entre los términos o pasajes extraídos.
– Recuperación cross-language: Hallar documentos escritos en cualquier lenguaje que son relevantes a una consulta expresada en otro lenguaje (búsqueda multilingual).
– Búsquedas Web: Se refiere a los SRI que operan sobre un corpus web privado (intranet) o público (Internet). La web ha planteado nuevos desafíos al área de RI, debido a sus características particulares como – por ejemplo – dinamismo y tamaño.
– Recuperación de Información Distribuida: A diferencia de los SRI clásicos donde el corpus y las estructuras de datos que auxilian a la búsqueda están centralizadas, aquí se plantea la tarea sobre los mismos elementos pero distribuidos sobre una red de computadoras.
– Modelado de Usuarios: Esta área – a partir de la interacción de los usuarios con un SRI – estudia como se generan de forma automática perfiles que definan las necesidades de información de éstos.
– Recuperación de Información Multimedia: Más allá de que los SRI tradicionales operan sobre corpus de documentos textuales, la recuperación de información tiene que tratar con otras formas alternativas de representación como imágenes, registro de conversaciones y video.
– Desarrollo de Conjuntos (data-sets) de Prueba: A los efectos de evaluar SRI completos o nuevos métodos y técnicas es necesario disponer de juegos de prueba normalizados (corpus con preguntas y respuestas predefinidas, corpus clasificados, etc.). Esta área tiene que ver con la producción tales conjuntos, a partir de diferentes estrategias que permitan reducir la complejidad de la tarea, manejando la dificultad inherente a la carga de subjetividad existente.
Referencias
[1] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[2] Peña, R., Baeza-Yates, R., Rodriguez, J.V. “Gestión Digital de la Información”. Alfaomega Grupo Editor. 2003.
Libro digital sobre la blogosfera hispana
Les cuento que en nuestras investigaciones sobre autores de blogs argentinos nos hemos topado con un excelente material en formato libro, editado por José Manuel Cerezo el cual tiene la colaboración, para el armado de sus capítulos, de una serie importante de investigadores (Enrique Dans y Fernando Garrido, entre otros).
Les copio el índice del libro "La Blogosfera Hispana"
TEORÍA DE LOS BLOGS
Una teoría general del blog
José Cervera
http://blogs.20minutos.es/retiario/
La construcción de la blogosfera: yo soy mi blog (y sus conexiones)
Adolfo Estalella
www.estalella.es
MIDIENDO LA BLOGOSFERA
El tamaño de la blogosfera: medidas y herramientas
Fernando Tricas, Juan J. Merelo Víctor R. Ruiz
http://fernand0.blogalia.com, atalaya.blogalia.com, rvr.typepad.com/linotipo/
Perfil del blogger español
Gemma Ferreres/ Fernando Garrido
http://tintachina.com, www.cibersociedad.net
Visibilidad en la blogosfera. Los nuevos prescriptores
José A. del Moral
www.alianzo.com
MEDIOS, POLÍTICA Y PARTICIPACIÓN
Los medios adoptan a los blogs
Juan Varela
http://periodistas21.com
Blogs: ¿Periodismo? participativo
Juan Zafra
www.red.es
Política en red
Ignacio Escolar
http://escolar.net
Los blogs y las Administraciones Públicas
Rafael Chamorro
http://eadministracion.blogspot.com
EMPRESA 2.0
Blogs: Marketing de ida y vuelta
Fernando Polo
http://abladias.com
Blogs y empresa: de la oscuridad a la luz, pasando por las tinieblas
Enrique Dans
http://enriquedans.com
GEOGRAFÍAS Y GÉNEROS
La ficción on line: un espectáculo en directo
Hernán Casciari
http://orsai.es
De los blogs al podcasting. ¿Continuidad o disrupción?
J.A. Gelado
http://informediario.com
"Blocs": dícese de los weblogs en catalán
Vicent Partal
www.vilaweb.cat
Les copio el índice del libro "La Blogosfera Hispana"
TEORÍA DE LOS BLOGS
Una teoría general del blog
José Cervera
http://blogs.20minutos.es/retiario/
La construcción de la blogosfera: yo soy mi blog (y sus conexiones)
Adolfo Estalella
www.estalella.es
MIDIENDO LA BLOGOSFERA
El tamaño de la blogosfera: medidas y herramientas
Fernando Tricas, Juan J. Merelo Víctor R. Ruiz
http://fernand0.blogalia.com, atalaya.blogalia.com, rvr.typepad.com/linotipo/
Perfil del blogger español
Gemma Ferreres/ Fernando Garrido
http://tintachina.com, www.cibersociedad.net
Visibilidad en la blogosfera. Los nuevos prescriptores
José A. del Moral
www.alianzo.com
MEDIOS, POLÍTICA Y PARTICIPACIÓN
Los medios adoptan a los blogs
Juan Varela
http://periodistas21.com
Blogs: ¿Periodismo? participativo
Juan Zafra
www.red.es
Política en red
Ignacio Escolar
http://escolar.net
Los blogs y las Administraciones Públicas
Rafael Chamorro
http://eadministracion.blogspot.com
EMPRESA 2.0
Blogs: Marketing de ida y vuelta
Fernando Polo
http://abladias.com
Blogs y empresa: de la oscuridad a la luz, pasando por las tinieblas
Enrique Dans
http://enriquedans.com
GEOGRAFÍAS Y GÉNEROS
La ficción on line: un espectáculo en directo
Hernán Casciari
http://orsai.es
De los blogs al podcasting. ¿Continuidad o disrupción?
J.A. Gelado
http://informediario.com
"Blocs": dícese de los weblogs en catalán
Vicent Partal
www.vilaweb.cat
jueves, agosto 24, 2006
Libro "Digital Economy Fact" edición 2006
Para aquellos que necesiten datos acerca de Internet y su evolución mundial les recomiendo la nueva edición del libro "Digital Economy Fact Book", recién publicado por la Fundación del Progreso y de la Libertad (parece una ironía pero tiene sede en Washington). El libro resume información recopilada de distintas fuentes públicas y privadas. El material se halla listo para descargar en http://www.pff.org/issues-pubs/books/factbook_2006.pdf.
En los próximos días espero poder leelo y hacerles comentarios sobre los tópicos más im portantes que halle.
En los próximos días espero poder leelo y hacerles comentarios sobre los tópicos más im portantes que halle.
miércoles, agosto 23, 2006
Wikipedia un ejemplo de proyecto social a gran escala
He sido invitado por un grupo de alumnos de la UNLu para organizar una mesa debate sobre software libre y educación. A los efectos de abrir el evento estoy preparando un pequeño documento donde se exponen casos de éxito de comunidades digitales, es decir donde hay auto organización por parte de pares. En particular pienso hablar sobre el proyecto Wikipedia, algo del folksonomías, redes P2P entre otros. Les acerco un borrador sobre Wikipedia sobre el cual me gustaría que puedan aportar ideas o puntos de vista para el debate.
Wikipedia un ejemplo de producto de calidad certificada
Jimmy Wales es el fundador, -en enero del año 2001, de una enciclopedia libre de carácter participativo denominada “Wikipedia”. Sobre los alcances logrados ha manifestado que “..como el rock and roll, la Wikipedia implica un giro cultural...”. Su comunidad de usuarios ha logrado crear un espacio en el que se puede extraer e ingresar conocimiento, el cual probablemente será expandido o corregido por otros pares de forma libre. El producto logrado es un ejemplo a escala donde se observa como ha tenido éxito un modelo de producción colaborativa de bienes de carácter intelectual y lo más importante que tanto su uso y su edición son libres.
Cualquier usuario de Internet puede editar contenidos de la Wikipedia, aportando nuevos artículos, completando existentes, traduciendo artículos de una lengua a otra, corrigiendo errores de ortografía o simplemente participando de foros. Los participantes voluntarios son los “wikipedistas” y en un nivel superior de responsabilidad están los administradores o “bibliotecarios”, los cuales poseen mandato para borrar páginas, restaurar su contenido o bloquear a usuarios no deseados. Actualmente la comunidad cuenta con más de un 1 millón de usuarios registrados y con casi 4 millones de artículos en 229 idiomas.
Con respecto a los derechos de autor del material publicado, la enciclopedia utiliza como base la licencia libre GNU creada por Richard Stallman. La cual permite distribuir copias, ya sea gratuitas o con un precio determinado, y modificar los artículos muy libremente siempre y cuando se respeten ciertas reglas básicas. Los usuarios no pueden agregar contenido bajo reglas copyright que no sea compatible con la licencia GNU.
Wikipedia está en un estado de madurez que según Wales se expresa a partir del concepto que aquellos que contribuyan a mantenerla y expandirla deben centrar sus esfuerzos en la calidad de la información publicada (básicamente en precisión y ortografía) más que la cantidad de entradas nuevas aportadas. En agosto del año 2006 se registraban más de un 1,3 millones de entradas para la lengua inglesa y alrededor de 143.000 para el español .
Con respecto al estado actual de calidad de los artículos publicados, la revista científica Nature a fines del año 2005 indicó que no hallan importantes diferencias de edición con la Enciclopedia Británica. Un experimento que consistió en aplicarle el sistema de revisión por pares a artículos de ambas publicaciones indicó que la Enciclopedia Británica tiene un margen de errores levemente menor que Wikipedia. Se compararon 42 artículos y Wikipedia tiene un promedio cuatro errores por artículo y la Enciclopedia Británica tres. Los revisores expertos hallaron ocho errores serios (4 en cada enciclopedia) y 285 errores menores (162 en Wikipedia y 123 en la Enciclopedia Británica). Lo importante a destacar es que la utilización de editores pagos no produce una mejor calidad de resultados que los aportados por editores ad honorem. Como dato interesante el costo de la Enciclopedia Británica es de alrededor de los 1.400 dólares.
La expansión e intensidad de uso de la Wikipedia anuncian el surgimiento de un posible clásico de la humanidad. Hay varios proyectos que estudian la forma de construir distribuciones en DVD o en CDROM, a los efectos que las comunidades menos desarrolladas, lugares donde aún no llega Internet, puedan acceder a sus contenidos. Por otro lado en lo referente a intensidad de uso hay datos que ilustran que es un recurso preferido por parte de los internautas. Utilizando los datos de preferencias de navegación a sitios, provistos por la empresa Alexa en agosto del año 2006, se observa que Wikipedia se halla en el puesto 16 en el ranking general. En el puesto 19 en el ranking de argentina, 18 en México, 6 en Suiza y 18 en Japón.
Fernando Bordignon
Wikipedia un ejemplo de producto de calidad certificada
Jimmy Wales es el fundador, -en enero del año 2001, de una enciclopedia libre de carácter participativo denominada “Wikipedia”. Sobre los alcances logrados ha manifestado que “..como el rock and roll, la Wikipedia implica un giro cultural...”. Su comunidad de usuarios ha logrado crear un espacio en el que se puede extraer e ingresar conocimiento, el cual probablemente será expandido o corregido por otros pares de forma libre. El producto logrado es un ejemplo a escala donde se observa como ha tenido éxito un modelo de producción colaborativa de bienes de carácter intelectual y lo más importante que tanto su uso y su edición son libres.
Cualquier usuario de Internet puede editar contenidos de la Wikipedia, aportando nuevos artículos, completando existentes, traduciendo artículos de una lengua a otra, corrigiendo errores de ortografía o simplemente participando de foros. Los participantes voluntarios son los “wikipedistas” y en un nivel superior de responsabilidad están los administradores o “bibliotecarios”, los cuales poseen mandato para borrar páginas, restaurar su contenido o bloquear a usuarios no deseados. Actualmente la comunidad cuenta con más de un 1 millón de usuarios registrados y con casi 4 millones de artículos en 229 idiomas.
Con respecto a los derechos de autor del material publicado, la enciclopedia utiliza como base la licencia libre GNU creada por Richard Stallman. La cual permite distribuir copias, ya sea gratuitas o con un precio determinado, y modificar los artículos muy libremente siempre y cuando se respeten ciertas reglas básicas. Los usuarios no pueden agregar contenido bajo reglas copyright que no sea compatible con la licencia GNU.
Wikipedia está en un estado de madurez que según Wales se expresa a partir del concepto que aquellos que contribuyan a mantenerla y expandirla deben centrar sus esfuerzos en la calidad de la información publicada (básicamente en precisión y ortografía) más que la cantidad de entradas nuevas aportadas. En agosto del año 2006 se registraban más de un 1,3 millones de entradas para la lengua inglesa y alrededor de 143.000 para el español .
Con respecto al estado actual de calidad de los artículos publicados, la revista científica Nature a fines del año 2005 indicó que no hallan importantes diferencias de edición con la Enciclopedia Británica. Un experimento que consistió en aplicarle el sistema de revisión por pares a artículos de ambas publicaciones indicó que la Enciclopedia Británica tiene un margen de errores levemente menor que Wikipedia. Se compararon 42 artículos y Wikipedia tiene un promedio cuatro errores por artículo y la Enciclopedia Británica tres. Los revisores expertos hallaron ocho errores serios (4 en cada enciclopedia) y 285 errores menores (162 en Wikipedia y 123 en la Enciclopedia Británica). Lo importante a destacar es que la utilización de editores pagos no produce una mejor calidad de resultados que los aportados por editores ad honorem. Como dato interesante el costo de la Enciclopedia Británica es de alrededor de los 1.400 dólares.
La expansión e intensidad de uso de la Wikipedia anuncian el surgimiento de un posible clásico de la humanidad. Hay varios proyectos que estudian la forma de construir distribuciones en DVD o en CDROM, a los efectos que las comunidades menos desarrolladas, lugares donde aún no llega Internet, puedan acceder a sus contenidos. Por otro lado en lo referente a intensidad de uso hay datos que ilustran que es un recurso preferido por parte de los internautas. Utilizando los datos de preferencias de navegación a sitios, provistos por la empresa Alexa en agosto del año 2006, se observa que Wikipedia se halla en el puesto 16 en el ranking general. En el puesto 19 en el ranking de argentina, 18 en México, 6 en Suiza y 18 en Japón.
Fernando Bordignon
martes, agosto 22, 2006
Mercado de los motores de búsqueda a Julio 2006
Ya se han publicado datos sobre las preferencias de uso de los principales servicios de búsqueda en Internet en USA. Como siempre Google primero, pero se empieza a ver que Yahoo está logrando una marcada tendencia hacía el crecimiento (a costa de lo que pierde MSN). También están los datos de Hitwise & Nielsen que confirman esta tendencia.


lunes, agosto 21, 2006
El profesor Keith Van Rijsbergen ganó el premio "Gerard Salton"
Keith van Rijsbergen es profesor en el Department of Computing Science de la University of Glasgow y lidera el "Information Retrieval Group". Desde el año 1969 ha investigado en IR teórica y aplicada. Este año en el marco del SIGIR se le ha entregado el premio "Gerard Salton" el cual es el máximo galardón de esta comunidad. Es un premio que se da cada 3 años y basicamente se evalua la trayectoria y aportes al conocimiento.
Ganadores de otros años son:
2003 - Prof. W. Bruce Croft
2000 - Stephen Robertson
1997 - Tefko Saracevic
1994 - William Cooper
1991 - Cyril Cleverdon
1988 - Karen Sparck Jones
1983 - Gerard Salton
Ganadores de otros años son:
2003 - Prof. W. Bruce Croft
2000 - Stephen Robertson
1997 - Tefko Saracevic
1994 - William Cooper
1991 - Cyril Cleverdon
1988 - Karen Sparck Jones
1983 - Gerard Salton
Nuevos motores de consulta
Estuve revisando algunos nuevos servicios de búsqueda. Les paso una somera descripción de cada uno. Sería interesante poder intercambiar impresiones sobre su comportamiento con quienes los hayan utilizado.
LivePlasma: Es un servicio de búsqueda orientado a películas y a música. A partir de un nombre de tema, intérprete, película, actor o director. El sistema arma un grafo de relación con otros objetos vecinos. Según versiones a los efectos de determinar qué relación existe entre cada tipo de música el sistema toma datos del sitio Amazon. En particular, extrae información acerca de qué otras compras han realizado aquellas personas que han comprado algún disco de dicho músico.
ZoomInfo: Es un motor de búsqueda (puesto en marcha a inicios del 2005) que se enfoca a la localización de personas y de compañías. Ofrece resúmenes de datos acerca de compañías y personas. Es un motor de consulta orientado a la localización de personas y organizaciones. En agosto del 2006 Zoominfo informaba que eran más de 31 millones de personas y 2 millones de empresas las que tenían indexadas en su base de datos. La información la recolecta de varias fuentes, como ser: sitios web, boletines de prensa, agencias de prensa, entre otros.
Gravee: Es un buscador tradicional con algunas características propias. A medida que el usuario examina los resultados puede evaluarlos como positivos o negativos, tal información será tomada como recomendación para otros usuarios. Los sitios hallados pueden ser almacenados en una sección de favoritos. Los usuarios dueños de blogs pueden añadir en sus sitios interfaces de consulta con Gravee y recibir una recompensa económica por ello. Los generadores de contenido indexado por Gravee pueden tener un dinero a cambio de ellos. En Gravee se pretende cambiar compartir los ingresos publicitarios con los propietarios contenidos y aquellos que fomenten el uso del servicio.
Jookster: Se basa en que los usuarios pueden afinar las búsqueda en referencia a lo previamente que hayan buscado otros miembros de la comunidad. Si un usuario busca "NNN", llega a CCC y lo cataloga como bueno, luego otro usuario consulte por “NNN” a Jookster tendrá a “NNN” bien posicionado en la lista de respuestas. El servicio es ideal para grupos de usuarios con temáticas afines dado que cooperativamente pueden tener una buena perfomance en sus consultas. Se basa en el concepto de búsquedas sociales.
Krugle: Es un servicio de búsqueda especializado en buscar sobre código fuente y documentos técnicos. Su fin es parecido al del sistema Koders. Las consultas son por palabra o palabras claves, y se puede elegir entre 17 lenguajes de programación. Se puede definir el ámbito de búsqueda, por ejemplo buscar en método o función, en definiciones, de quién hereda, en variables y en definición de clases.
LivePlasma: Es un servicio de búsqueda orientado a películas y a música. A partir de un nombre de tema, intérprete, película, actor o director. El sistema arma un grafo de relación con otros objetos vecinos. Según versiones a los efectos de determinar qué relación existe entre cada tipo de música el sistema toma datos del sitio Amazon. En particular, extrae información acerca de qué otras compras han realizado aquellas personas que han comprado algún disco de dicho músico.
ZoomInfo: Es un motor de búsqueda (puesto en marcha a inicios del 2005) que se enfoca a la localización de personas y de compañías. Ofrece resúmenes de datos acerca de compañías y personas. Es un motor de consulta orientado a la localización de personas y organizaciones. En agosto del 2006 Zoominfo informaba que eran más de 31 millones de personas y 2 millones de empresas las que tenían indexadas en su base de datos. La información la recolecta de varias fuentes, como ser: sitios web, boletines de prensa, agencias de prensa, entre otros.
Gravee: Es un buscador tradicional con algunas características propias. A medida que el usuario examina los resultados puede evaluarlos como positivos o negativos, tal información será tomada como recomendación para otros usuarios. Los sitios hallados pueden ser almacenados en una sección de favoritos. Los usuarios dueños de blogs pueden añadir en sus sitios interfaces de consulta con Gravee y recibir una recompensa económica por ello. Los generadores de contenido indexado por Gravee pueden tener un dinero a cambio de ellos. En Gravee se pretende cambiar compartir los ingresos publicitarios con los propietarios contenidos y aquellos que fomenten el uso del servicio.
Jookster: Se basa en que los usuarios pueden afinar las búsqueda en referencia a lo previamente que hayan buscado otros miembros de la comunidad. Si un usuario busca "NNN", llega a CCC y lo cataloga como bueno, luego otro usuario consulte por “NNN” a Jookster tendrá a “NNN” bien posicionado en la lista de respuestas. El servicio es ideal para grupos de usuarios con temáticas afines dado que cooperativamente pueden tener una buena perfomance en sus consultas. Se basa en el concepto de búsquedas sociales.
Krugle: Es un servicio de búsqueda especializado en buscar sobre código fuente y documentos técnicos. Su fin es parecido al del sistema Koders. Las consultas son por palabra o palabras claves, y se puede elegir entre 17 lenguajes de programación. Se puede definir el ámbito de búsqueda, por ejemplo buscar en método o función, en definiciones, de quién hereda, en variables y en definición de clases.
domingo, agosto 20, 2006
Conocen Tagzania?
Es una plataforma colaborativa basada en la filosofía propia de las folksonomias, donde través de las etiquetas proporcionadas por los usuarios se van rotulando y compartiendo distintos objetos espaciales (paisajes, lugares, regiones, etc) de su interés . El usuario registrado puede añadir lugares a su cuenta personal con la finalidad de crear y documentar sitio y mapas Su forma de operación es similar al servicio proporcionado por del.icio.us , pero en compartir páginas web de interés se comparten lugares preferidos sobre los mapas provistos Google. Es un servicio social de mantenimiento de una base de datos de marcadores geográfico ('social geomarking tool').
A continuación se ve una captura de pantalla con un ejemplo de geotag basado en la Universidad Nacional de Luján.
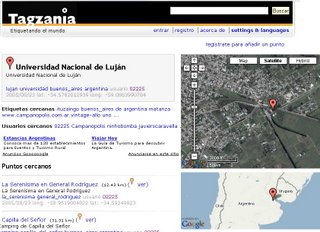
A continuación se ve una captura de pantalla con un ejemplo de geotag basado en la Universidad Nacional de Luján.
jueves, agosto 17, 2006
El entorno de la recuperación de información - I
Hace algún tiempo, con mi compañero de trabajo Gabriel Tolosa, he escrito un libro de caracter docente, que introduce al atrevido lector al mundo de la recuperación de información.
La anécdota dice que por cuestiones burocráticas propias de alguna institución pública, el mencionado material aún "duerme" -en algún cajón de escritorio de un gerente- el sueño de querer ser. La excusa pública es que se está esperando por alguna reglamentación (la cual parece que a nadie le importa tratarla) para evaluarse si debe publicarse o no. La historia dice que hace dos años el material sigue esperando.
Hemos decidido publicar algunas pasajes de dicho libro en este blog a los efectos de poder poner a disposición de los interesados algunos mínimos conocimiento sobre este apasionante tema lllamdo "recuperación de información".
Históricamente, el hombre ha necesitado de medios sobre los cuales representar todo acerca del mundo que lo rodea y de reflejar – de alguna manera – su evolución. La escritura ha sido el mecanismo “tradicional” y fundamental que soporta su conocimiento en el tiempo.
Esta misma evolución ha facilitado la existencia de diferentes medios de representación de la escritura, llegando hasta nuestros días donde la información se representa digitalmente y es posible su almacenamiento y su distribución masiva en forma simple y rápida, a través de redes de computadoras. La digitalización abrió nuevos horizontes en las formas en que el hombre puede tratar con la información que produce.
De igual manera, el volumen de información existente crece permanentemente y adquiere diferentes formas de representación, desde simples archivos de texto en una computadora personal o un periódico electrónico hasta librerías digitales y espacios mucho más grandes y complejos como la web. Algunos investigadores han planteado que – desde hace varios años – existe un fenómeno denominado “sobrecarga de información” [35] debido a que el volumen y la disponibilidad hacen que los usuarios no cuenten con suficiente tiempo físico para “procesar” todo el cúmulo de medios a su alcance [9].
Entonces, resulta importante tratar con toda esa información disponible electrónicamente para que pueda servir a diferentes personas (usuarios) en diferentes situaciones. Esto plantea un desafío interesante: hay importantes volúmenes de información y hay usuarios que se pueden beneficiar de alguna manera con la posibilidad de acceder a ésta, por lo tanto, cómo poder unir preguntas con respuestas, necesidades de información con documentos, consultas con resultados? Bien, en las ciencias de la computación existe un área, la Recuperación de Información (Information Retrieval), que estudia y propone soluciones al escenario presentado, planteando modelos, algoritmos y heurísticas.
La Recuperación de Información (RI) no es un área nueva, sino que se viene desarrollando desde finales de la década de 1950. Sin embargo, en la actualidad adquiere un rol más importante debido al valor que tiene la información. Se puede plantear que disponer o no de la información justa en tiempo y forma puede resultar en el éxito o fracaso de una operación. De aquí, la importancia de los Sistemas de Recuperación de Información (SRI) que pueden manejar – con ciertas limitaciones – estas situaciones de manera eficaz y eficiente.
Pero, ¿Qué se entiende concretamente por “Recuperación de Información”? Para Ricardo Baeza-Yates y otros [2] “la Recuperación de Información trata con la representación, el almacenamiento, la organización y el acceso a ítems de información”.
Años antes, Salton [50] propuso una definición amplia que plantea que el área de RI “es un campo relacionado con la estructura, análisis, organización, almacenamiento, búsqueda y recuperación de información”.
Cabe aclarar que en las definiciones anteriores los elementos de información son no estructurados, tales como documentos de texto libre (por ejemplo, un archivo de texto que contenga La Biblia) ó semi-estructurados, como lo son las páginas web.
Croft [16] estima que la recuperación de información es “el conjunto de tareas mediante las cuales el usuario localiza y accede a los recursos de información que son pertinentes para la resolución del problema planteado. En estas tareas desempeñan un papel fundamental los lenguajes documentales, las técnicas de resumen, la descripción del objeto documental, etc.”. Por otro lado, Korfhage [25] definió la RI como “la localización y presentación a un usuario de información relevante a una necesidad de información expresada como una pregunta”
Ciertamente, es un área amplia, donde se abarcan diferentes tópicos, algunos computacionales como el almacenamiento y la organización; y otros relacionados con el lenguaje y los usuarios como la representación y la recuperación propiamente dicha.
Nótese que Croft y Korfhage plantean explícitamente el rol del usuario como fuente de consultas y destinatario de las respuestas. Por lo tanto, de manera más genérica, podemos plantear que la recuperación de información intenta resolver el problema de “encontrar y rankear documentos relevantes que satisfagan la necesidad de información de un usuario, expresada en un determinado lenguaje de consulta”. Sin embargo, existe un problema que dificulta sobremanera esta tarea y consiste en poder “compatibilizar” y comparar el lenguaje en que está expresada tal necesidad de información y el lenguaje de los documentos.
[2] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[9] Carlson, C. “Information overload, retrieval strategies and Internet user empowerment”.In Haddon, Leslie, Eds. Proceedings The Good, the Bad and the Irrelevant (COST 269) 1(1), pp. 169-173, Helsinki (Finland). 2003.
[16] Croft, W.B. “Approaches to intelligent information retrieval.” Information Proccesing & Management, 23, 4, pp. 249-254. 1987.
[25] Korfhage, R. R. “Information Storage and Retrieval”. New York. Wiley Computer Publishing. 1997.
[35] Maes, P. “Agents that Reduce Work and Information Overload”. Communications of the ACM, Vol. 37, Nro. 7, págs. 30-40. 1994.
[50] Salton, G. Y Mc Gill, M.J. “Introducttion to Modern Information Retrieval”. New York. Mc Graw-Hill Computer Series. 1983.
La anécdota dice que por cuestiones burocráticas propias de alguna institución pública, el mencionado material aún "duerme" -en algún cajón de escritorio de un gerente- el sueño de querer ser. La excusa pública es que se está esperando por alguna reglamentación (la cual parece que a nadie le importa tratarla) para evaluarse si debe publicarse o no. La historia dice que hace dos años el material sigue esperando.
Hemos decidido publicar algunas pasajes de dicho libro en este blog a los efectos de poder poner a disposición de los interesados algunos mínimos conocimiento sobre este apasionante tema lllamdo "recuperación de información".
Históricamente, el hombre ha necesitado de medios sobre los cuales representar todo acerca del mundo que lo rodea y de reflejar – de alguna manera – su evolución. La escritura ha sido el mecanismo “tradicional” y fundamental que soporta su conocimiento en el tiempo.
Esta misma evolución ha facilitado la existencia de diferentes medios de representación de la escritura, llegando hasta nuestros días donde la información se representa digitalmente y es posible su almacenamiento y su distribución masiva en forma simple y rápida, a través de redes de computadoras. La digitalización abrió nuevos horizontes en las formas en que el hombre puede tratar con la información que produce.
De igual manera, el volumen de información existente crece permanentemente y adquiere diferentes formas de representación, desde simples archivos de texto en una computadora personal o un periódico electrónico hasta librerías digitales y espacios mucho más grandes y complejos como la web. Algunos investigadores han planteado que – desde hace varios años – existe un fenómeno denominado “sobrecarga de información” [35] debido a que el volumen y la disponibilidad hacen que los usuarios no cuenten con suficiente tiempo físico para “procesar” todo el cúmulo de medios a su alcance [9].
Entonces, resulta importante tratar con toda esa información disponible electrónicamente para que pueda servir a diferentes personas (usuarios) en diferentes situaciones. Esto plantea un desafío interesante: hay importantes volúmenes de información y hay usuarios que se pueden beneficiar de alguna manera con la posibilidad de acceder a ésta, por lo tanto, cómo poder unir preguntas con respuestas, necesidades de información con documentos, consultas con resultados? Bien, en las ciencias de la computación existe un área, la Recuperación de Información (Information Retrieval), que estudia y propone soluciones al escenario presentado, planteando modelos, algoritmos y heurísticas.
La Recuperación de Información (RI) no es un área nueva, sino que se viene desarrollando desde finales de la década de 1950. Sin embargo, en la actualidad adquiere un rol más importante debido al valor que tiene la información. Se puede plantear que disponer o no de la información justa en tiempo y forma puede resultar en el éxito o fracaso de una operación. De aquí, la importancia de los Sistemas de Recuperación de Información (SRI) que pueden manejar – con ciertas limitaciones – estas situaciones de manera eficaz y eficiente.
Pero, ¿Qué se entiende concretamente por “Recuperación de Información”? Para Ricardo Baeza-Yates y otros [2] “la Recuperación de Información trata con la representación, el almacenamiento, la organización y el acceso a ítems de información”.
Años antes, Salton [50] propuso una definición amplia que plantea que el área de RI “es un campo relacionado con la estructura, análisis, organización, almacenamiento, búsqueda y recuperación de información”.
Cabe aclarar que en las definiciones anteriores los elementos de información son no estructurados, tales como documentos de texto libre (por ejemplo, un archivo de texto que contenga La Biblia) ó semi-estructurados, como lo son las páginas web.
Croft [16] estima que la recuperación de información es “el conjunto de tareas mediante las cuales el usuario localiza y accede a los recursos de información que son pertinentes para la resolución del problema planteado. En estas tareas desempeñan un papel fundamental los lenguajes documentales, las técnicas de resumen, la descripción del objeto documental, etc.”. Por otro lado, Korfhage [25] definió la RI como “la localización y presentación a un usuario de información relevante a una necesidad de información expresada como una pregunta”
Ciertamente, es un área amplia, donde se abarcan diferentes tópicos, algunos computacionales como el almacenamiento y la organización; y otros relacionados con el lenguaje y los usuarios como la representación y la recuperación propiamente dicha.
Nótese que Croft y Korfhage plantean explícitamente el rol del usuario como fuente de consultas y destinatario de las respuestas. Por lo tanto, de manera más genérica, podemos plantear que la recuperación de información intenta resolver el problema de “encontrar y rankear documentos relevantes que satisfagan la necesidad de información de un usuario, expresada en un determinado lenguaje de consulta”. Sin embargo, existe un problema que dificulta sobremanera esta tarea y consiste en poder “compatibilizar” y comparar el lenguaje en que está expresada tal necesidad de información y el lenguaje de los documentos.
[2] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[9] Carlson, C. “Information overload, retrieval strategies and Internet user empowerment”.In Haddon, Leslie, Eds. Proceedings The Good, the Bad and the Irrelevant (COST 269) 1(1), pp. 169-173, Helsinki (Finland). 2003.
[16] Croft, W.B. “Approaches to intelligent information retrieval.” Information Proccesing & Management, 23, 4, pp. 249-254. 1987.
[25] Korfhage, R. R. “Information Storage and Retrieval”. New York. Wiley Computer Publishing. 1997.
[35] Maes, P. “Agents that Reduce Work and Information Overload”. Communications of the ACM, Vol. 37, Nro. 7, págs. 30-40. 1994.
[50] Salton, G. Y Mc Gill, M.J. “Introducttion to Modern Information Retrieval”. New York. Mc Graw-Hill Computer Series. 1983.
Opiniones del gerente de Yahoo Argentina
Recomiendo leer la nota titulada "La Argentina perdió ante Brasil el liderazgo de Internet”. La cual fue realziada al gerente de Yahoo argentina hace algunos días atrás.
Medición de audiencia de sitios de Internet - Junio 2006
El Interactive Advertising Bureau de Argetina constantemente mide la medición de audiencia de sitios de Internet de sus asociados. En junio del 2006 se registró un incremento, tanto en cantidad de visitantes únicos, páginas vistas y sesiones realizadas. Les invito a ver los sitios y números en IAB - Interactive Advertising Bureau
martes, agosto 15, 2006
¿Cuál es la plataforma preferida por los usuarios de Internet?
En el día de ayer la empresa OneStat.com [www.onestat.com] publicó datos acera de las preferencias en el uso plataformas de escritorio, por parte de los usuarios de Internet, aquí la cruda realidad:
1. Windows XP 86.80%
2. Windows 2000 6.09%
3. Windows 98 2.68%
4. Macintosh 2.32%
5. Windows ME 1.09%
6. Linux 0.36%
7. Windows NT 0.24%
8. Mac Power PC 0.15%
1. Windows XP 86.80%
2. Windows 2000 6.09%
3. Windows 98 2.68%
4. Macintosh 2.32%
5. Windows ME 1.09%
6. Linux 0.36%
7. Windows NT 0.24%
8. Mac Power PC 0.15%
Datos sobre Internet en Argentina - Informe D´alessio Irol 2004-2005
Finalmente he hallado un documento, encargado a la consultora D´alessio Irol por el diario Clarín, que ilustra de mejor manera la expansión y uso de Internet en nuestro país. Se caracteriza el uso por edad, nivel socioeconómico, lugar de acceso, costumbres de navegación, entre otros.
domingo, agosto 13, 2006
Ya hay información a partir de los datos liberados por AOL
Hace alrededor de 10 días AOL liberó datos para que la comunidad científica haga estudios de comportamiento de usuarios con la finalidad de mejorar los servicios de IR. Más hallá del acostumbrado circo medíatico que generan ciertos medios con "responsabilidad social" ya existen resultados derivados de las primeras investigaciones.
Por ejemplo la distribución de clicks de usuarios sobre enlaces proporcionados en las listas de salida del buscador es:
1ro 42,1%
2do 11,9%
3ro 8,5%
4to 6,1%
5to 4,9%
6to 4,1%
7mo 3,4%
8vo 3,0%
9no 2,8%
10mo 3,0%
Total de búsquedas: 9.038.794
Total de Clicks: 4.926.623
A partir de ahora podemos ver realmente el valor de las adwords.
Por ejemplo la distribución de clicks de usuarios sobre enlaces proporcionados en las listas de salida del buscador es:
1ro 42,1%
2do 11,9%
3ro 8,5%
4to 6,1%
5to 4,9%
6to 4,1%
7mo 3,4%
8vo 3,0%
9no 2,8%
10mo 3,0%
Total de búsquedas: 9.038.794
Total de Clicks: 4.926.623
A partir de ahora podemos ver realmente el valor de las adwords.
Datos sobre Internet en Argentina
Hace algunos días prometí alcanzar datos sobre el crecimiento de Internet en Argentina, todavía no tengo suficiente material actualizado para concluir algo con cierta solidez. Pero les alcanzo algo de ACNielsen publicado en la Nación.
"Casi el 40% de los hogares de Capital y el conurbano poseen computadoras
Según un estudio realizado por la consultora ACNielsen, el 39,5% de los hogares de Capital Federal y el Gran Buenos Aires posee al menos una computadora.
En otro ejemplo de lo que es la brecha digital en el país, el acceso a las nuevas tecnologías vuelve a quedar marcado por las escalas sociales. Mientras que el 90,9% de los hogares ABC1 cuentan con computadoras personales, el nivel desciende al 62,2% en las viviendas de clase media y al 14,5% en los de menores recursos.
De a uno . La mayoría de los hogares posee una sola computadora, sin embargo el informe de la consultora destaca una importante penetración de 2 o más equipos en las viviendas de mayor ingreso.
Del total de casos relevados, el 10,4% tiene dos equipos en el hogar y sólo el 2,0%, 3 o más. En el segmento ABC1, el 21,7% de los hogares cuenta con 2 computadoras y el 6,4%, 3 o más.
Internet . El 62% de los hogares que poseen computadoras tienen a su vez contratados servicios de Internet: 69,1% en Capital y 57.5% en el conurbano bonaerense.
Entre el total de conectados a la Web, el 49,3% cuenta con un servicio de banda ancha, frente al 21,5% que tiene un abono dial-up y al 27,1% que elige conectarse de un acceso dial-up gratuito.
La proporción de conexiones en Capital se divide en: 53,5%, banda ancha; 22,3% dial-up gratuito; y 20,9% dial-up con abono. En tanto que en el Gran Buenos Aires, la participación es de: 46,0% banda ancha; 30,7% dial-up gratuito; y 21,9% dial-up con abono.
... El 35% de los consumidores argentinos manifiestan invertir en tecnología luego de cubrir sus necesidades básicas. "
Fuente "La Nación" [http://www.lanacion.com.ar/tecnologia/nota.asp?nota_id=820294 ]
"Casi el 40% de los hogares de Capital y el conurbano poseen computadoras
Según un estudio realizado por la consultora ACNielsen, el 39,5% de los hogares de Capital Federal y el Gran Buenos Aires posee al menos una computadora.
En otro ejemplo de lo que es la brecha digital en el país, el acceso a las nuevas tecnologías vuelve a quedar marcado por las escalas sociales. Mientras que el 90,9% de los hogares ABC1 cuentan con computadoras personales, el nivel desciende al 62,2% en las viviendas de clase media y al 14,5% en los de menores recursos.
De a uno . La mayoría de los hogares posee una sola computadora, sin embargo el informe de la consultora destaca una importante penetración de 2 o más equipos en las viviendas de mayor ingreso.
Del total de casos relevados, el 10,4% tiene dos equipos en el hogar y sólo el 2,0%, 3 o más. En el segmento ABC1, el 21,7% de los hogares cuenta con 2 computadoras y el 6,4%, 3 o más.
Internet . El 62% de los hogares que poseen computadoras tienen a su vez contratados servicios de Internet: 69,1% en Capital y 57.5% en el conurbano bonaerense.
Entre el total de conectados a la Web, el 49,3% cuenta con un servicio de banda ancha, frente al 21,5% que tiene un abono dial-up y al 27,1% que elige conectarse de un acceso dial-up gratuito.
La proporción de conexiones en Capital se divide en: 53,5%, banda ancha; 22,3% dial-up gratuito; y 20,9% dial-up con abono. En tanto que en el Gran Buenos Aires, la participación es de: 46,0% banda ancha; 30,7% dial-up gratuito; y 21,9% dial-up con abono.
... El 35% de los consumidores argentinos manifiestan invertir en tecnología luego de cubrir sus necesidades básicas. "
Fuente "La Nación" [http://www.lanacion.com.ar/tecnologia/nota.asp?nota_id=820294 ]
Datos sobre el avance de las redes sociales
La empresa americana Compete presentó un estudio acerca de las redes sociales comparándolas con los portales. Sobre una muestra de 2 millones de norteamericanos la empresa concluyó que las redes sociales se están acercando al tráfico de los grandes portales como Yahoo y Google.
Entre los hallazgos más importantes se cuentan: a)En el mes de junio 2 de cada tres navegantes visitaron un sitio de red social y b) Desde enero de 2004 el número de personas que visitaron o son parte de una red social ha crecido en un 109%
Ver la noticia en http://blog.compete.com/index.php/2006/08/11/top-social-networks-gaining-on-top-portals-yahoo-google/
Miren como avanzó MySpace.
Entre los hallazgos más importantes se cuentan: a)En el mes de junio 2 de cada tres navegantes visitaron un sitio de red social y b) Desde enero de 2004 el número de personas que visitaron o son parte de una red social ha crecido en un 109%
Ver la noticia en http://blog.compete.com/index.php/2006/08/11/top-social-networks-gaining-on-top-portals-yahoo-google/
Miren como avanzó MySpace.
Estudio actualizado sobre la blogósfera
David Sifry, creador de Technorati, ha actulizado su estudio sobre el estado de la blogósfera. Es interesante ver en mismo como evoluciona, piensen que hoy duplica su tamaño cada 200 días. Cada día se crean alrededor de 175.000 blogs. El volumen de posteo muestra que hay 1,6 de millones de posts por día.
Interesante fenómeno social mundial, dado que en los blogs, en general, el internauta deja su actitud pasiva de buscador de información y se convierte en una fuente que retroalimenta la web.
Saludos.
Interesante fenómeno social mundial, dado que en los blogs, en general, el internauta deja su actitud pasiva de buscador de información y se convierte en una fuente que retroalimenta la web.
Saludos.
sábado, agosto 12, 2006
Cluto, una aplicación interesante para trabajar con clusters
En esta mini entrada quería comentar acerca de una aplicación simple pero poderosa orientada a la generación de clusters (análisis de conglomerados). CLUTO (http://glaros.dtc.umn.edu/gkhome/views/cluto) es una aplicación abierta y se adapta a varios ambientes -biología, IR, ecnonomía, etc-.
Personalmente la he utilizado para experimentos de clasificación de textos y me ha servido bastante. SU característica principal es la sencillez de uso, su contra la escalabilidad en W32 (si la matriz de atributos es grande crashea y ajo o ir a un Linux).
Si quieren hacer una prueba rápida de clasificación de textos hagan lo siguiente:
1) Genere un archivo donde se encuentren los n docs a clasificar, para lo cual cada línea representa un documento con sus atributos seleccionados (términos importantes del mismo)
archivo:mio.raw
doc1 término1 término2 ... términoN
doc2 término1 término2 ... términoJ
doc3 término1 término2 ... términoK
...
docM término1 término2 ... términoL
Tratar que los términos contengan la semántica del documento y no sean palabras vacias o de uso frecuente (artículos, preposiciones, conjunciones, etc). Si puede hacerlo normalize los términos en género y número y si son verbos llévelos a su infinitivo.
2) Usando la aplicación doc2mat (viene con Cluto) convierta a mio.raw en estructuras de datos que Cluto pueda procesar
perl doc2mat -nlskip=1 mio.raw mio.mat
nlskip le indica que el primer atributo es el nombre del objeto
En el directorio ahora tendrá los archivos mio.raw y mio.clabel (es el lexicon) y mio.rlabel (nombres de objetos a clusterizar)
3) Ahora hay que generar las clases, para eso se utiliza la aplicación vcluster
vcluster mio.mat 6
Donde 6 hace referencia al número k de clases que se desean generar
Por pantalla se mostrarán una serie de datos que son resultados del procesamiento. En el directorio hallará al archivo mio.mat.clustering.6 que contiene tantos registros como objetos a clasificar y los registros tienen un único atributo que es el número de clase que se le ha asignado, el orden es el mismo que hay en mio.rlabel.
Bueno ahora sigan ustedes, la aplicación tiene una cantidad interesante de parámetros y fucniones de optimización, como así tambie´n interfaces de visualización de clases generadas.
El manual de Cluto en http://glaros.dtc.umn.edu/gkhome/fetch/sw/cluto/manual.pdf
A clusterizar que se acaba el mundo!!!
Personalmente la he utilizado para experimentos de clasificación de textos y me ha servido bastante. SU característica principal es la sencillez de uso, su contra la escalabilidad en W32 (si la matriz de atributos es grande crashea y ajo o ir a un Linux).
Si quieren hacer una prueba rápida de clasificación de textos hagan lo siguiente:
1) Genere un archivo donde se encuentren los n docs a clasificar, para lo cual cada línea representa un documento con sus atributos seleccionados (términos importantes del mismo)
archivo:mio.raw
doc1 término1 término2 ... términoN
doc2 término1 término2 ... términoJ
doc3 término1 término2 ... términoK
...
docM término1 término2 ... términoL
Tratar que los términos contengan la semántica del documento y no sean palabras vacias o de uso frecuente (artículos, preposiciones, conjunciones, etc). Si puede hacerlo normalize los términos en género y número y si son verbos llévelos a su infinitivo.
2) Usando la aplicación doc2mat (viene con Cluto) convierta a mio.raw en estructuras de datos que Cluto pueda procesar
perl doc2mat -nlskip=1 mio.raw mio.mat
nlskip le indica que el primer atributo es el nombre del objeto
En el directorio ahora tendrá los archivos mio.raw y mio.clabel (es el lexicon) y mio.rlabel (nombres de objetos a clusterizar)
3) Ahora hay que generar las clases, para eso se utiliza la aplicación vcluster
vcluster mio.mat 6
Donde 6 hace referencia al número k de clases que se desean generar
Por pantalla se mostrarán una serie de datos que son resultados del procesamiento. En el directorio hallará al archivo mio.mat.clustering.6 que contiene tantos registros como objetos a clasificar y los registros tienen un único atributo que es el número de clase que se le ha asignado, el orden es el mismo que hay en mio.rlabel.
Bueno ahora sigan ustedes, la aplicación tiene una cantidad interesante de parámetros y fucniones de optimización, como así tambie´n interfaces de visualización de clases generadas.
El manual de Cluto en http://glaros.dtc.umn.edu/gkhome/fetch/sw/cluto/manual.pdf
A clusterizar que se acaba el mundo!!!
viernes, agosto 11, 2006
Servicio público de almacenamiento de favoritos
En los últimos años, ciertos sitios basados en el concepto de almacenar y compartir direcciones de recursos sugeridos por usuarios han tenido un importante crecimiento. En general sitios como Del.icio.us o Furl almacenan colecciones de enlaces sugeridos por los usuarios.
Cuando los usuarios están navegando y se encuentran con alguna página o recurso interesante, que deseen registrar su existencia lo pueden hacer de dos modos a saber: a) registrando en su máquina la dirección por medio del uso de la facilidad de los navegadores, conocida como “marcadores” o b) registrando la dirección del recurso en una cuenta personal de un servicio público de almacenamiento de favoritos (social bookmarking services). En ambos casos la información quedará almacenada y el usuario en tiempo futuro podrá volver utilizarla. Pero en el segundo caso tal recomendación será compartida entre otros usuarios que necesiten sugerencias.
En estos servicios los recursos almacenados por los usuarios son asignados, por ellos mismos, a categorías y se les adjuntan una serie de etiquetas o tags que mejor describen su contenido. Tal información será utilizada por el servicio a los efectos de armar esquemas de recuperación de información.
Más allá de los marcadores, Blogger [http://www.blogger.com] es un ejemplo interesante donde se puede apreciar la navegación o exploración basada en etiquetas (no brinda servicio de almacenamiento de favoritos). En su sección perfiles se presenta por cada usuario una página con datos personales que, entre otras cosas, hablan acerca de su localización geográfica y preferencias, los cuales son etiquetas. Cada etiqueta es un enlace a otros perfiles de usuarios que comparten tal preferencia, así se arma una red de enlaces que vinculan usuarios que comparten algún gusto o están en una misma área geográfica.
En el mundo académico un uso interesante de marcadores sociales se da en el sitio CiteULike el cual permite que investigadores puedan intercambiar sus preferencias en citas bibliográficas (ver también Connotea). Por ejemplo el investigador X trabaja actualmente investigando sobre el tema Y. Este señor posee una cuenta en CiteULike y todas las referencias a trabajos que le han llamado la atención las guarda en un espacio compartido. Cualquier otro investigador que también le interese la temática Y puede consultar las preferencias de X dado que las mismas seguramente le serán útiles al tratar el mismo objeto de estudio.
Documento comparativo sobre servicios de marcadores
Enlaces a servicios de marcadores
Cuando los usuarios están navegando y se encuentran con alguna página o recurso interesante, que deseen registrar su existencia lo pueden hacer de dos modos a saber: a) registrando en su máquina la dirección por medio del uso de la facilidad de los navegadores, conocida como “marcadores” o b) registrando la dirección del recurso en una cuenta personal de un servicio público de almacenamiento de favoritos (social bookmarking services). En ambos casos la información quedará almacenada y el usuario en tiempo futuro podrá volver utilizarla. Pero en el segundo caso tal recomendación será compartida entre otros usuarios que necesiten sugerencias.
En estos servicios los recursos almacenados por los usuarios son asignados, por ellos mismos, a categorías y se les adjuntan una serie de etiquetas o tags que mejor describen su contenido. Tal información será utilizada por el servicio a los efectos de armar esquemas de recuperación de información.
Más allá de los marcadores, Blogger [http://www.blogger.com] es un ejemplo interesante donde se puede apreciar la navegación o exploración basada en etiquetas (no brinda servicio de almacenamiento de favoritos). En su sección perfiles se presenta por cada usuario una página con datos personales que, entre otras cosas, hablan acerca de su localización geográfica y preferencias, los cuales son etiquetas. Cada etiqueta es un enlace a otros perfiles de usuarios que comparten tal preferencia, así se arma una red de enlaces que vinculan usuarios que comparten algún gusto o están en una misma área geográfica.
En el mundo académico un uso interesante de marcadores sociales se da en el sitio CiteULike el cual permite que investigadores puedan intercambiar sus preferencias en citas bibliográficas (ver también Connotea). Por ejemplo el investigador X trabaja actualmente investigando sobre el tema Y. Este señor posee una cuenta en CiteULike y todas las referencias a trabajos que le han llamado la atención las guarda en un espacio compartido. Cualquier otro investigador que también le interese la temática Y puede consultar las preferencias de X dado que las mismas seguramente le serán útiles al tratar el mismo objeto de estudio.
Documento comparativo sobre servicios de marcadores
Enlaces a servicios de marcadores
- HLOM(www.hyperlinkomatic.com)
- Gibeov (gibeo.net)
- Furl (www.furl.net)
- Spurl (www.spurl.net)
- del.icio.us (del.icio.us)
- CiteULike (www.citeulike.org)
- Connotea (www.connotea.org)
jueves, agosto 10, 2006
Semana del SIGIR
Esta semana, en Seattle, se está llevando a cabo el evento más importante de la ACM sobre recuperación de información SIGIR-2006. Es interesante hacer notar que a este evento llegan muchos papers pero son pocos los que se seleccionan para su exposición. En general es una vidriera para que los laboratorios más importantes del mundo presenten el estado del arte en diversos tópicos relacionados con IR (Q&A, cross language retrieval, web mining, topic detection, entre otros).
Recomiendo ir a la página de trabajos aceptados y ver cuales son los temas en que la gente está trabajando ahora. También es notorio ver como Microsoft China ha aportado trabajos. Otras cosas interesantes de ver son los tutoriales.
Recomiendo ir a la página de trabajos aceptados y ver cuales son los temas en que la gente está trabajando ahora. También es notorio ver como Microsoft China ha aportado trabajos. Otras cosas interesantes de ver son los tutoriales.
Off topic: pero interesante para debatir
Hace algunos días alguien posteo, a la lista Solar, un supuesto relato de un joven que trabaja en un "call center". En el mismo se cuentan una serie de cosas que recuerdan a los mejores tiempos de los señores feudales. No se si es verdad, pero me llama la atención el tema.
Cada uno tiene su criterio y experiencias de vida, por lo tanto sabá valorarlo, pero si en parte es verdad creo que hay gente que se está equivocando en el uso de la tecnología.
Les dejo el enlace: ¿Sábe donde trabaja su hijo?
Cada uno tiene su criterio y experiencias de vida, por lo tanto sabá valorarlo, pero si en parte es verdad creo que hay gente que se está equivocando en el uso de la tecnología.
Les dejo el enlace: ¿Sábe donde trabaja su hijo?
miércoles, agosto 09, 2006
Nuevos datasets para investigar en IR
Los laboratorios de AOL Research han puesto a disposición de investigadores de recuperación de información y otras disciplinas datos de comportamiento de usuarios en su servicio de búqueda.
Por lo que comenté en otro artículo de este blog, tal información puede servir para entener más las motiviaciones de consulta de los usuarios, resolver automaticamente la ambiguedad, y brindar listas de salida con mayor presición.
Para los que deseen chusmear sobre web mining le recomiendo este paper para largar "A Picture of Search" G. Pass, A. Chawdry y C. Torgeson.
Los saludo
- 20,000 consultas etiquetadas y clasificadas por expertos.
- 3,5 millones de consultas web tipo QA (pregunta/respuesta)
- Trazas de consultas para 500,000 usuarios tomadas durante 3 meses, +- 20 millones de consultas. (Esto trajo lío y aparentemente lo han sacado)
- Datos de llegada de consultas para análisis por teoría de colas
- Cerca de 2 millones de consultas realizadas a dominios del gobierno americano.
Por lo que comenté en otro artículo de este blog, tal información puede servir para entener más las motiviaciones de consulta de los usuarios, resolver automaticamente la ambiguedad, y brindar listas de salida con mayor presición.
Para los que deseen chusmear sobre web mining le recomiendo este paper para largar "A Picture of Search" G. Pass, A. Chawdry y C. Torgeson.
Los saludo
martes, agosto 08, 2006
Datos de penetración de Internet en USA
La organización americana de opinión pública PEW, en abril de este año presentó los resultados de una encuesta sobre uso de la red en la población. Si bien en nuestro país hay posquísimos datos, ver en otros paises lo que pasa puede darnos una magnitud acerca de donde estamos involucrados. (A futuro prometo ver como está localmente el fenómeno de la red). Volviendo al tema principal, los hallazgos más importantes son:
• The share of online Americans who say the internet has greatly improved their ability to shop has doubled—from 16% to 32%—since March 2001.
• The share of online Americans who say the internet has greatly improved the way they pursue hobbies and interests has grown to 33%, up from 20% in March 2001.
• The share of online Americans who say the internet has greatly improved their ability to do their job has grown to 35%, up from 24% in March 2001.
• The share of online Americans who say the internet has greatly improved the way they get information about health care has grown to 20%, up from 17% in March 2001.
Es interesante ver como crece el uso y en cada día que pasa los usuarios empiezan a tomar como natural el hacer cosas por la red. Pienso que para profesionales de la información estos tipos de datos pueden ayudarle a percibir escenarios futuros donde apliquen de la mejor forma posible sus conocimientos.
• The share of online Americans who say the internet has greatly improved their ability to shop has doubled—from 16% to 32%—since March 2001.
• The share of online Americans who say the internet has greatly improved the way they pursue hobbies and interests has grown to 33%, up from 20% in March 2001.
• The share of online Americans who say the internet has greatly improved their ability to do their job has grown to 35%, up from 24% in March 2001.
• The share of online Americans who say the internet has greatly improved the way they get information about health care has grown to 20%, up from 17% in March 2001.
Es interesante ver como crece el uso y en cada día que pasa los usuarios empiezan a tomar como natural el hacer cosas por la red. Pienso que para profesionales de la información estos tipos de datos pueden ayudarle a percibir escenarios futuros donde apliquen de la mejor forma posible sus conocimientos.
lunes, agosto 07, 2006
¿Qué hacen los chicos en los laboratorios?
Estuve paseando por los laboratorios de Yahoo , Microsoft y Google y con sorpresa vi que ambas empresas enfocaron sus dólares, perdón investigaciones, hacía dejar de ver al usuario como un señor gris anónimo, carente de personalidad, que buscar con intención comercial o académica o de entretenimiento da los mismo. Total lo procesamos de la misma forma y le armamos los rankings de salida con los mismos algoritmos, es como si fueras al restaurant y te mixen la entrada, el plato principal y el postre, y te den todo junto !!!Total son todas proteinas!!!.
Parece que han empezado a caracterizar al señor usuario, sino miren las siguientes líneas de trabajo:
Búsqueda personalizada Google almacena tus búsquedas y sitios que has accedido a partir de los rankings. Luego te permite buscar
sobre ellos para tener más precisión en futuras consultas
Google Trends para ver como se ponen de moda tópicos
Web Alerts para que Google te avise si hay novdades en un tema de interes, (topics tracks)
Mindset: Intent-driven Search Excelente proyecto de Google donde lo que hacen es tratar de armar rankings con más o menos referencias a sitios comerciales según quiera el usuarios. Esto permitiría elevar la presición según el tipo de intención de búsqueda del usuarios. Por ejemplo si quiere documentos académicos puede bajar el umbral y filtrar la mayoría de las páginas de venta que nada tienen que ver con lo académico.
Microsoft China tiene un proyecto similar donde hace un análisis multivariado de las características de las páginas spam y genera reglas para detectarlas (en caso que a alguien le interese el tema hay mucho para investigar :-) ) Antes había demostradores, ahora no los puedo encontrar.
Saludos y los comentarios para cuándo?
Parece que han empezado a caracterizar al señor usuario, sino miren las siguientes líneas de trabajo:
Búsqueda personalizada Google almacena tus búsquedas y sitios que has accedido a partir de los rankings. Luego te permite buscar
sobre ellos para tener más precisión en futuras consultas
Google Trends para ver como se ponen de moda tópicos
Web Alerts para que Google te avise si hay novdades en un tema de interes, (topics tracks)
Mindset: Intent-driven Search Excelente proyecto de Google donde lo que hacen es tratar de armar rankings con más o menos referencias a sitios comerciales según quiera el usuarios. Esto permitiría elevar la presición según el tipo de intención de búsqueda del usuarios. Por ejemplo si quiere documentos académicos puede bajar el umbral y filtrar la mayoría de las páginas de venta que nada tienen que ver con lo académico.
Microsoft China tiene un proyecto similar donde hace un análisis multivariado de las características de las páginas spam y genera reglas para detectarlas (en caso que a alguien le interese el tema hay mucho para investigar :-) ) Antes había demostradores, ahora no los puedo encontrar.
Saludos y los comentarios para cuándo?
domingo, agosto 06, 2006
Algunas notas sobre orígenes de los weblogs
Tengan paciencia dado que como dice el título esta entrada está todavía en calidad de borrador. Espero comentarios
Según el servicio de bitácoras Blogger (http://www.blogger.com) ,auspiciado por Google, un blog “es un sitio Web fácil de usar en el cual puede, entre otras muchas cosas, expresar rápidamente sus opiniones e interactuar con otros usuarios”.
Los blogs, weblogs o bitácoras en español son espacios personales (es raro pero pueden ser multiautor) de escritura informal en Internet. En español a los weblogs se los conoce como bitácoras, y este término deriva de la expresión inglesa “log book” que quiere decir “cuaderno de bitácora”. En principio o en su forma original se pueden visualizar como un diario digital y compartido (con retroalimentación por parte de terceros que lo leen) que una persona usa para informar, compartir, debatir aquellas cosas que le interesan o gustan. En un blog cada tema o artículo (post) posee una fecha de publicación y se organiza automáticamente en orden cronológico inverso, a los efectos que la anotación más reciente es la que primera en aparecer. Tras la definición anterior, puede verse que los weblogs pertenecen a una clase de herramientas llamadas de construcción colaborativa tales como canales IRS, espacios wiki, catálogos colectivos tipo Flickr, entre otros
Para Civallero [CIVALLERO] hay una serie de términos que se asocian a los blogs tales como: libertad, apertura, independencia, sencillez, potencia, difusión, visibilidad, creatividad, imaginación y comunicación.
Debbie Weil, en WordBiz Report (http://www.wordbiz.com/archive/20blogdefs.shtml) ha recogido por parte de usuarios algunas definiciones de weblogs, como ser: “una forma de auto expresión auténtica”, “una herramienta de publicación instantánea”, “una revista en línea con contenido actualizado con alta perioricidad”, “periodismo amateur”, “una alternativa a los medios más importantes” o “una herramienta para enseñarle como escribir a los estudiantes” entre otras definiciones. Nótese que a partir de estas definiciones se puede tener una percepción más amplia acerca de la finalidad de uso de las bitácoras y su significancia para los usuarios de tales herramientas.
Dado que los weblogs son espacios gratuitos fáciles de crear y con múltiples posibilidades, se convierten en potenciales herramientas educativas que pueden ser usadas con un objetivo didáctico.
La expresión weblog empieza a utilizarse en el año 1997, dado que Jorn Barguer lo usó en su sitio “Robot Wisdom” (http://www.robotwisdom.com/log1997m12.html), años antes otros usuarios de internet tuvieron sitios con formatos similares, como por ejemplo links.net (http://www.links.net/vita/web/story.html) desde el año 1994 o incluso una página una página del National Center for Supercomputer Applications (NSCA) en el año 1993. En 1999 aparece el primer sitio de alojamiento gratuito de blogs denominado Blogger y tambien aparece el blog en español Barrapunto.com (), el cual tiene por temática el tratamiento de información relacionada con el software libre. El fenómeno toma reconocimiento mundial y en julio del año 2005 se lleva a cabo la Primer Conferencia Weblogs -.Comunicación (1CWCOM) realizada en México. También el mismo año aquellos usuarios que desean instalarse su propio blog a partir de su propia distribución de software disponen de la primera versión en español de la herramienta WordPress () .
Para Blood [BLOOD] los weblogs son como un diálogo o charla entre varias personas. Dado que se materializan en una página web con entradas (mensajes) ordenadas por fecha. En general, cualquier visitantes puede dejar su opinión sobre los temas tratados dejando un mensaje asociado a los mismos para que todo el mundo lo pueda ver. Este formato de conversación entre usuarios tiende a crear comunidades que se expresan en tiempo real. Su modo simplificado de publicación, donde el uso es intuitivo, facilita la retroalimentación de los temas a partir de fomentar su utilización.
Según David Sifry [EL PAIS, 2006], fundador de la empresa Technorati, a cada segundo que pasa nace un blog y cada seis meses se duplica la población de la blogósfera, la cual indica que hoy 60 veces más grande que hace tres años. De los 41 millones de blogs registrados en Technorati existen más de 19 millones de blogs que se continúan actualizando tres meses después de ser creados, esta proporción está creciendo (un 5% más que hace seis meses atrás), lo cual demuestra que el movimiento está en expansión.
Sifry expresa el carácter popular y comunitario, de los weblogs, con un ejemplo en el cual dice que más de 400 periódicos de Estados Unidos se han asociado a Technorati con la intención de poder comentar las noticias en el mismo instante que se leen, y ver lo que opinan otros. Por otro lado, justifica la importancia de los blogs para los servicios de búsqueda tradicionales diciendo que son estos los que aportan contenidos frescos, que son en parte los preferidos por los usuarios, según Sifry “la realidad es que la gente está escribiendo constantemente. Technorati te busca textos escritos hace cinco minutos de la actualidad más candente”, “Technorati contribuye a democratizar el medio. Democratiza el sistema. Eso es la Web 2.0, donde cada voz tiene su oportunidad de ser oída.”
El servicio ofrecido de Technorati nació a partir de necesidades personales de su fundador David Sifry [EL PAIS, 2006], donde años atrás como usuario de blogs se dio cuenta que existían herramientas para buscar en otros blogs por temas o por fechas o por personas y los servicios tradicionales de búsqueda no indexaban correctamente tales sitios. Desde el concepto de lograr un servicio de búsqueda solo blogs partió la idea de construir Technorati. Actualmente el servicio creado por Sifry ayuda expandir la blogosfera, regularmente visita más de 41 millones de blogs (dados de junio del 2006), detecta los más populares ya sea por visitas o por temas. A principios del año 2005 Technorati lanzó Technorati Tags, a los efectos que los uaurios empiecen a usar a usar etiquetas tipo “rel= tag” asociadas a los enlaces “href=”. Tales inclusiones sirven como auxiliares a las categorías con que se clasifiquen los posts de un weblog.
En la entrevista Sifry expresa que Technorati contribuye a democratizar el medio, y esa es la función de la Web 2.0, donde cada usuario tiene su oportunidad de ser oído.
En los últimos tiempos se ha fortalecido una especialización por formatos, empezaron a surgir audioblogs, photoblogs y videoblogs.
[EL PAIS, 2006] Diario El País. “Entrevista a David Sifry, fundador de Technorati “ Diario El País, 1 de junio 2006, disponible en URL
http://www.elpais.es/articulo/portada/David/Sifry/fundador/Technorati/soy/editor/siglo/XXI/elpcibpor/20060601elpcibpor_1/Tes/
[BOOD] BLOOD, REBECCA. The Weblog Handbook: Practical Advice on Creating and Maintaining Your Blog. Cambridge: Perseus Publishing 2002.
[FELIPE] Isabel Andreu Felipe “Los weblogs: ¿Son Literatura Gris? “
[6] MERLO VEGA, J.A.; SORLI ROJO, A. Weblogs: un recurso para los Revista Española de Documentación Científica, profesionales de la información. Abril-Junio 2003, vol. 26, n. 2, p. 227-236. Disponible en: http://exlibris.usal.es/merlo/escritos/weblogs.htm
[CIVALLERO] Civallero, Edgardo (2006) Cuadernos de bitácora : los weblogs como herramientas de trabajo de las bibliotecas. http://eprints.rclis.org/archive/00006747/, 2006
Según el servicio de bitácoras Blogger (http://www.blogger.com) ,auspiciado por Google, un blog “es un sitio Web fácil de usar en el cual puede, entre otras muchas cosas, expresar rápidamente sus opiniones e interactuar con otros usuarios”.
Los blogs, weblogs o bitácoras en español son espacios personales (es raro pero pueden ser multiautor) de escritura informal en Internet. En español a los weblogs se los conoce como bitácoras, y este término deriva de la expresión inglesa “log book” que quiere decir “cuaderno de bitácora”. En principio o en su forma original se pueden visualizar como un diario digital y compartido (con retroalimentación por parte de terceros que lo leen) que una persona usa para informar, compartir, debatir aquellas cosas que le interesan o gustan. En un blog cada tema o artículo (post) posee una fecha de publicación y se organiza automáticamente en orden cronológico inverso, a los efectos que la anotación más reciente es la que primera en aparecer. Tras la definición anterior, puede verse que los weblogs pertenecen a una clase de herramientas llamadas de construcción colaborativa tales como canales IRS, espacios wiki, catálogos colectivos tipo Flickr, entre otros
Para Civallero [CIVALLERO] hay una serie de términos que se asocian a los blogs tales como: libertad, apertura, independencia, sencillez, potencia, difusión, visibilidad, creatividad, imaginación y comunicación.
Debbie Weil, en WordBiz Report (http://www.wordbiz.com/archive/20blogdefs.shtml) ha recogido por parte de usuarios algunas definiciones de weblogs, como ser: “una forma de auto expresión auténtica”, “una herramienta de publicación instantánea”, “una revista en línea con contenido actualizado con alta perioricidad”, “periodismo amateur”, “una alternativa a los medios más importantes” o “una herramienta para enseñarle como escribir a los estudiantes” entre otras definiciones. Nótese que a partir de estas definiciones se puede tener una percepción más amplia acerca de la finalidad de uso de las bitácoras y su significancia para los usuarios de tales herramientas.
Dado que los weblogs son espacios gratuitos fáciles de crear y con múltiples posibilidades, se convierten en potenciales herramientas educativas que pueden ser usadas con un objetivo didáctico.
La expresión weblog empieza a utilizarse en el año 1997, dado que Jorn Barguer lo usó en su sitio “Robot Wisdom” (http://www.robotwisdom.com/log1997m12.html), años antes otros usuarios de internet tuvieron sitios con formatos similares, como por ejemplo links.net (http://www.links.net/vita/web/story.html) desde el año 1994 o incluso una página una página del National Center for Supercomputer Applications (NSCA) en el año 1993. En 1999 aparece el primer sitio de alojamiento gratuito de blogs denominado Blogger y tambien aparece el blog en español Barrapunto.com (), el cual tiene por temática el tratamiento de información relacionada con el software libre. El fenómeno toma reconocimiento mundial y en julio del año 2005 se lleva a cabo la Primer Conferencia Weblogs -.Comunicación (1CWCOM) realizada en México. También el mismo año aquellos usuarios que desean instalarse su propio blog a partir de su propia distribución de software disponen de la primera versión en español de la herramienta WordPress () .
Para Blood [BLOOD] los weblogs son como un diálogo o charla entre varias personas. Dado que se materializan en una página web con entradas (mensajes) ordenadas por fecha. En general, cualquier visitantes puede dejar su opinión sobre los temas tratados dejando un mensaje asociado a los mismos para que todo el mundo lo pueda ver. Este formato de conversación entre usuarios tiende a crear comunidades que se expresan en tiempo real. Su modo simplificado de publicación, donde el uso es intuitivo, facilita la retroalimentación de los temas a partir de fomentar su utilización.
Según David Sifry [EL PAIS, 2006], fundador de la empresa Technorati, a cada segundo que pasa nace un blog y cada seis meses se duplica la población de la blogósfera, la cual indica que hoy 60 veces más grande que hace tres años. De los 41 millones de blogs registrados en Technorati existen más de 19 millones de blogs que se continúan actualizando tres meses después de ser creados, esta proporción está creciendo (un 5% más que hace seis meses atrás), lo cual demuestra que el movimiento está en expansión.
Sifry expresa el carácter popular y comunitario, de los weblogs, con un ejemplo en el cual dice que más de 400 periódicos de Estados Unidos se han asociado a Technorati con la intención de poder comentar las noticias en el mismo instante que se leen, y ver lo que opinan otros. Por otro lado, justifica la importancia de los blogs para los servicios de búsqueda tradicionales diciendo que son estos los que aportan contenidos frescos, que son en parte los preferidos por los usuarios, según Sifry “la realidad es que la gente está escribiendo constantemente. Technorati te busca textos escritos hace cinco minutos de la actualidad más candente”, “Technorati contribuye a democratizar el medio. Democratiza el sistema. Eso es la Web 2.0, donde cada voz tiene su oportunidad de ser oída.”
El servicio ofrecido de Technorati nació a partir de necesidades personales de su fundador David Sifry [EL PAIS, 2006], donde años atrás como usuario de blogs se dio cuenta que existían herramientas para buscar en otros blogs por temas o por fechas o por personas y los servicios tradicionales de búsqueda no indexaban correctamente tales sitios. Desde el concepto de lograr un servicio de búsqueda solo blogs partió la idea de construir Technorati. Actualmente el servicio creado por Sifry ayuda expandir la blogosfera, regularmente visita más de 41 millones de blogs (dados de junio del 2006), detecta los más populares ya sea por visitas o por temas. A principios del año 2005 Technorati lanzó Technorati Tags, a los efectos que los uaurios empiecen a usar a usar etiquetas tipo “rel= tag” asociadas a los enlaces “href=”. Tales inclusiones sirven como auxiliares a las categorías con que se clasifiquen los posts de un weblog.
En la entrevista Sifry expresa que Technorati contribuye a democratizar el medio, y esa es la función de la Web 2.0, donde cada usuario tiene su oportunidad de ser oído.
En los últimos tiempos se ha fortalecido una especialización por formatos, empezaron a surgir audioblogs, photoblogs y videoblogs.
[EL PAIS, 2006] Diario El País. “Entrevista a David Sifry, fundador de Technorati “ Diario El País, 1 de junio 2006, disponible en URL
http://www.elpais.es/articulo/portada/David/Sifry/fundador/Technorati/soy/editor/siglo/XXI/elpcibpor/20060601elpcibpor_1/Tes/
[BOOD] BLOOD, REBECCA. The Weblog Handbook: Practical Advice on Creating and Maintaining Your Blog. Cambridge: Perseus Publishing 2002.
[FELIPE] Isabel Andreu Felipe “Los weblogs: ¿Son Literatura Gris? “
[6] MERLO VEGA, J.A.; SORLI ROJO, A. Weblogs: un recurso para los Revista Española de Documentación Científica, profesionales de la información. Abril-Junio 2003, vol. 26, n. 2, p. 227-236. Disponible en: http://exlibris.usal.es/merlo/escritos/weblogs.htm
[CIVALLERO] Civallero, Edgardo (2006) Cuadernos de bitácora : los weblogs como herramientas de trabajo de las bibliotecas. http://eprints.rclis.org/archive/00006747/, 2006
viernes, agosto 04, 2006
Hay comentarios sobre servicios basados en tags?
Uds. han utilizado algunos de los siguientes servicios basados en etiquetas o tags? Si es así cual fue su experiencia, que piensan de los tags ayudan o solo son una moda?. Si no lo hicieron prueben con algunos de los siguientes sitios
-Flickr [www.flickr.com] sitio que permite publicar fotos
-CiteULike [www.citeulike.org] servicio destinado a que los profesores e investigadores almacenen enlaces personales a material académico científico.
-GenieLab [http://genielab.com] servicio de recomendación de recursos musicales
-Tagcloud, que clasifica fuentes de noticias bajo protocolo RSS.
-Technorati clasifica las anotaciones de los blogs
-Flickr [www.flickr.com] sitio que permite publicar fotos
-CiteULike [www.citeulike.org] servicio destinado a que los profesores e investigadores almacenen enlaces personales a material académico científico.
-GenieLab [http://genielab.com] servicio de recomendación de recursos musicales
-Tagcloud, que clasifica fuentes de noticias bajo protocolo RSS.
-Technorati clasifica las anotaciones de los blogs
Sobre weblogs
Actualmente una de mis líneas de trabajo es la Web 2.0, en particular estos días estoy avergiguando la génesis y evolución de la blogósfera. Les paso la síntesis de una encuesta a autores nortemaericanos de blogs realizada por PEW.
Un estudio más actual, del año 2006, de Pew Internet & American Life Project [LENHART] sobre autores de blogs norteamericanos indica que los weblogs están inspirando a un nuevo grupo de escritores a compartir sus pensamientos con el mundo. El 54% de los escritores de blogs dicen que nunca antes publicaron algún escrito. El 8% de los usuarios norteamricanos de Internet mantienen un blog y el 39% lee blogs. El estudio indica que el uso dominiante de la blogósfera norteamericana (espacio virtual donde residen los blogs) es como diario personal (7% de los autores indican que los usan para hablar de su vida y sus experiencias principalmente) y los autores, en su mayoría, no se identifican con la profesión o hobby de periodista. Entre otros fines temáticos luego se hallan los siguientes temas: política 11%, entretenimiento 7%, deportes 6%, noticias y eventos 5%, negocios 5%, tecnología 4%. El r4% de los autores tiene menos de 30 años y el 55% de los autores utilza un seudónimo. El 84% lo toma com hobby. El 59% invierte entre una a dos horas por semana en mantenerlos. La mayoría de los autores los mantiene por que dicen que son un buen instyrumento para expresar su creatividad, documentar sus experiencias personales, compartir con otros. El 77% de los autores de blogs ha compartido previamente algún recurso, como ser fotos, historias, videos, etc. El 87% permite que otros usuarios envien comentarios a sus artículos. El 18% ofrece servicios de sindicación de contenidos.
[LENHART] Amanda Lenhart and Susannah Fox. “Bloggers: A portrait of the internet’s new storytellers“. Pew Internet & American Life Project, 2006
Tienen otros datos que no sean solo de norteamericanos?
Un estudio más actual, del año 2006, de Pew Internet & American Life Project [LENHART] sobre autores de blogs norteamericanos indica que los weblogs están inspirando a un nuevo grupo de escritores a compartir sus pensamientos con el mundo. El 54% de los escritores de blogs dicen que nunca antes publicaron algún escrito. El 8% de los usuarios norteamricanos de Internet mantienen un blog y el 39% lee blogs. El estudio indica que el uso dominiante de la blogósfera norteamericana (espacio virtual donde residen los blogs) es como diario personal (7% de los autores indican que los usan para hablar de su vida y sus experiencias principalmente) y los autores, en su mayoría, no se identifican con la profesión o hobby de periodista. Entre otros fines temáticos luego se hallan los siguientes temas: política 11%, entretenimiento 7%, deportes 6%, noticias y eventos 5%, negocios 5%, tecnología 4%. El r4% de los autores tiene menos de 30 años y el 55% de los autores utilza un seudónimo. El 84% lo toma com hobby. El 59% invierte entre una a dos horas por semana en mantenerlos. La mayoría de los autores los mantiene por que dicen que son un buen instyrumento para expresar su creatividad, documentar sus experiencias personales, compartir con otros. El 77% de los autores de blogs ha compartido previamente algún recurso, como ser fotos, historias, videos, etc. El 87% permite que otros usuarios envien comentarios a sus artículos. El 18% ofrece servicios de sindicación de contenidos.
[LENHART] Amanda Lenhart and Susannah Fox. “Bloggers: A portrait of the internet’s new storytellers“. Pew Internet & American Life Project, 2006
Tienen otros datos que no sean solo de norteamericanos?
Chin chin he habilitado mi blog
Hola gente, mi nombre es Fernando Bordignon y disfruto la vida, entre otas cosas, investigando sobre recuperación de información y el fenómeno denominado "information overload" (frase acuñada por Pattie Maes en el MIT hace algunos -bastantes- años atrás).
Como soy medio despelotado (o tal vez es la edad y aún no lo reconozco) quiero inagurar este ámbito por tres razones: a) la práctica: necesito disponer de un espacio donde pueda almacenar mis notas de estudio (reflexiones, traducciones, estadísticas, etc) b) la social: me gustaría exponer y debatir, en forma de literatura gris, algunas ideas sobre mi temas de investigación y c)la personal: he descubierto que me gusta escribir.
Saludos a todos y a ver que sale de esto !!!
Como soy medio despelotado (o tal vez es la edad y aún no lo reconozco) quiero inagurar este ámbito por tres razones: a) la práctica: necesito disponer de un espacio donde pueda almacenar mis notas de estudio (reflexiones, traducciones, estadísticas, etc) b) la social: me gustaría exponer y debatir, en forma de literatura gris, algunas ideas sobre mi temas de investigación y c)la personal: he descubierto que me gusta escribir.
Saludos a todos y a ver que sale de esto !!!
Suscribirse a:
Entradas (Atom)
