De forma general – según Baeza-Yates [1] – el problema de la RI puede ser estudiado desde dos puntos de vista: el computacional y el humano. El primer caso tiene que ver con la construcción de estructuras de datos y algoritmos eficientes que mejoren la calidad de las respuestas. El segundo caso corresponde al estudio del comportamiento y de las necesidades de los usuarios.
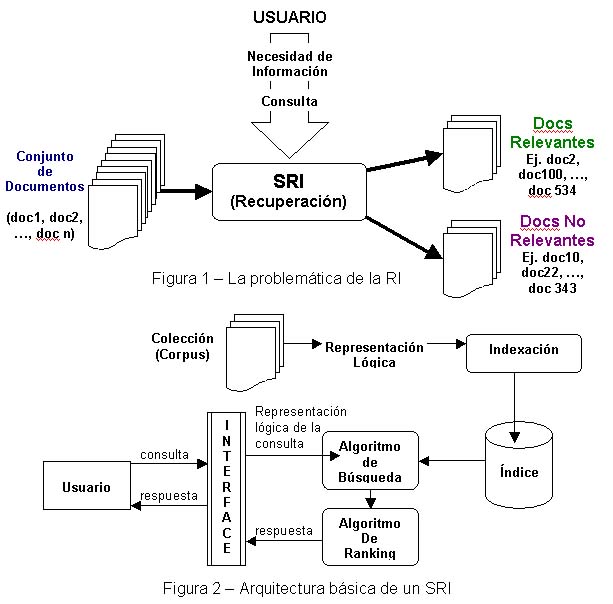
Si se analiza la problemática de la RI desde un alto nivel de abstracción (Figura 1) podemos establecer que:
– Existe una colección de documentos que contienen información de interés (sobre uno o varios temas)
– Existen usuarios con necesidades de información, quienes las plantean al SRI en forma de una consulta (en inglés, query. En adelante, ambas palabras se utilizarán indistintamente)
– Como respuesta, el sistema retorna – de forma ideal – referencias a documentos “relevantes”, es decir aquellos que satisfacen la necesidad expresada, generalmente en forma de una lista rankeada.
Planteamos que la respuesta “ideal” de un SRI está formada solamente por documentos relevantes a la consulta, pero – en la práctica – esta no es aún alcanzable. Esto se debe a que – entre otros motivos – existe el problema de compatibilizar la expresión de la necesidad de información y el lenguaje y de los documentos. Además, hay una carga de subjetividad subyacente y depende de los usuarios. Entonces, el SRI recupera la mayor cantidad posible de documentos relevantes, minimizando la cantidad de documentos no relevantes (ruido) en la respuesta. En términos de eficiencia, se plantea la idea de precisión de la respuesta, es decir, cuando más documentos relevantes contenga el conjunto solución (para una consulta dada), más preciso será.
Para cumplir con sus objetivos, un SRI debe realizar algunas tareas básicas, las cuales se encuentran – fundamentalmente – planteadas en cuestiones computacionales, a saber:
– Representación lógica de los documentos y – opcionalmente – almacenamiento del original. Algunos sistemas solo almacenan porciones de los documentos y otros lo hacen de manera completa.
– Representación de la necesidad de información del usuario en forma de consulta.
– Evaluación de los documentos respecto de una consulta para establecer la relevancia de cada uno.
– Rankeo de los documentos considerados relevantes para formar el “conjunto solución” o respuesta.
– Presentación de la respuesta al usuario.
– Retroalimentación o refinamiento de las consultas (para aumentar la calidad de la respuesta)
En la figura 2 se puede apreciar con mayor detalle la arquitectura básica de un SRI, el tratamiento de los documentos y la interacción con el usuario. Aquí se ven algunos componentes que no se habían mencionado hasta el momento.
Como podemos observar, se parte de un conjunto de documentos de texto, los cuales están compuestos por sucesiones de palabras que forman estructuras gramaticales (por ejemplo, oraciones y párrafos). Tales documentos están escritos en lenguaje natural y expresan ideas de su autor sobre un determinado tema. El conjunto de todos los documentos con los que se trata y sobre los que se deben realizar operaciones de RI se denomina corpus, colección o base de datos textual o documental. Para poder realizar operaciones sobre un corpus, es necesario obtener primero una representación lógica de todos sus documentos, la cual puede consistir en un conjunto de términos, frases u otras unidades (sintácticas o semánticas) que permitan – de alguna manera – caracterizarlos. Por ejemplo, la representación de los documentos mediante un conjunto de sus términos se la conoce como “bolsa de palabras” (bag of words).
A partir de la representación lógica existe un proceso (indexación) que llevará a cabo la construcción de estructuras de datos (normalmente denominadas índices) que la almacene y soporte búsquedas eficientes. Es importante destacar que una vez construidos los índices, los documentos del corpus pueden ser eliminados del sistema ya que éste retornará las referencias a los mismos debido a que cuenta con la información necesaria para hacerlo. En tal caso, el usuario será el encargado de localizar el documento para consultarlo. A los sistemas que funcionan bajo este modelo se los denomina “sistemas referenciales”, en contraste con los que sí almacenan y mantienen los documentos denominados “sistemas documentales” [2]. Un ejemplo de sistemas referenciales son algunos de los motores de búsqueda web, que retornan una lista de urls a los documentos, como – por ejemplo – Altavista Un caso particular es el motor de búsqueda Google el cual – en algunos casos – almacena en memoria caché el documento completo, el cual puede ser consultado durante cierto tiempo, incluso si ha desaparecido del sitio original.
El algoritmo de búsqueda acepta como entrada una expresión de consulta o query de un usuario y verificará en el índice cuáles documentos pueden satisfacerlo. Luego, un algoritmo de ranking determinará la relevancia de cada documento y retornará una lista con la respuesta. Se establece que el primer ítem de dicha lista corresponde al documento más relevante respecto de a la consulta y así sucesivamente en orden decreciente.
La interface de usuario permite que éste especifique la consulta mediante una expresión escrita en un lenguaje preestablecido y – además – sirve para mostrar las respuestas retornadas por el sistema.
Si bien hasta aquí se planteó la tarea básica de la RI y la arquitectura general de un SRI, el área es muy amplia y abarca diferentes tópicos. En general, un SRI no entrega una respuesta directa a una consulta, sino que permite localizar referencias a documentos que pueden contener información útil. Pero éste es solo uno de los aspectos del área de RI en la actualidad, ya que se ha atacado el problema con una perspectiva más amplia, proponiendo y desarrollando estrategias y modelos para mejorar y aumentar la funcionalidad de los SRI. Entre otras, la RI abarca tópicos como:
– Modelos de Recuperación: La tarea de la recuperación puede ser modelada desde distintos enfoques, por ejemplo la estadística, el álgebra de boole, el álgebra de vectores, la lógica difusa, el procesamiento del lenguaje natural y demás.
– Filtrado y Ruteo: Es un área que permite la definición de perfiles de necesidades de información por parte de usuarios y ante el ingreso de nuevos documentos al SRI, se los analiza y se lo reenvía a quienes se estima que van a ser relevantes.
– Clasificación: Aquí se realiza la rotulación automática de documentos de un corpus en base a clases previamente definidas.
– Agrupamiento (Clustering): Es una tarea similar a la clasificación pero no existen clases predefinidas. El proceso automáticamente determinará cuáles son las particiones.
– Sumarización: Área que entiende sobre técnicas de extracción de aquellas partes (palabras, frases, oraciones, párrafos) que contienen la semántica que determina la esencia de un documento.
– Detección de novedades (Novelty Detection): Se basa en la determinación de la introducción de nuevos tópicos o temas a un SRI.
– Respuestas a Preguntas (Question Answering): Consiste en hallar aquellas porciones de texto de un documento que satisfacen expresamente a una consulta, es decir, la respuesta concreta a una pregunta dada.
– Extracción de Información: Extraer aquellas porciones de texto con una alta carga semántica y establecer relaciones entre los términos o pasajes extraídos.
– Recuperación cross-language: Hallar documentos escritos en cualquier lenguaje que son relevantes a una consulta expresada en otro lenguaje (búsqueda multilingual).
– Búsquedas Web: Se refiere a los SRI que operan sobre un corpus web privado (intranet) o público (Internet). La web ha planteado nuevos desafíos al área de RI, debido a sus características particulares como – por ejemplo – dinamismo y tamaño.
– Recuperación de Información Distribuida: A diferencia de los SRI clásicos donde el corpus y las estructuras de datos que auxilian a la búsqueda están centralizadas, aquí se plantea la tarea sobre los mismos elementos pero distribuidos sobre una red de computadoras.
– Modelado de Usuarios: Esta área – a partir de la interacción de los usuarios con un SRI – estudia como se generan de forma automática perfiles que definan las necesidades de información de éstos.
– Recuperación de Información Multimedia: Más allá de que los SRI tradicionales operan sobre corpus de documentos textuales, la recuperación de información tiene que tratar con otras formas alternativas de representación como imágenes, registro de conversaciones y video.
– Desarrollo de Conjuntos (data-sets) de Prueba: A los efectos de evaluar SRI completos o nuevos métodos y técnicas es necesario disponer de juegos de prueba normalizados (corpus con preguntas y respuestas predefinidas, corpus clasificados, etc.). Esta área tiene que ver con la producción tales conjuntos, a partir de diferentes estrategias que permitan reducir la complejidad de la tarea, manejando la dificultad inherente a la carga de subjetividad existente.
Referencias
[1] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[2] Peña, R., Baeza-Yates, R., Rodriguez, J.V. “Gestión Digital de la Información”. Alfaomega Grupo Editor. 2003.

No hay comentarios.:
Publicar un comentario