Los SRI (sistemas de recuperación de información)toman un conjunto de documentos (colección) para procesar y luego poder responder consultas. De forma básica, podemos clasificar los documentos en estructurados y no estructurados. Los primeros son aquellos en los que se pueden reconocer elementos estructurales con una semántica bien definida, mientras que los segundos corresponden a texto libre, sin formato. La diferencia fundamental de un SRI que procese documentos estructurados se encuentra en que puede extraer información adicional al contenido textual, la cual utiliza en la etapa de recuperación para facilitar la tarea y aumentar las prestaciones.
A partir de lo expresado anteriormente se presenta una posible clasificación de modelos de RI – la cual no es exhaustiva – de acuerdo a características estructurales de los documentos.

A continuación se describen – de forma somera – los modelos clásicos y el álgebra de regiones. Más adelante, en el capítulo 4, se profundizará en los modelos booleano y vectorial.
1. Modelo booleano
En el modelo booleano la representación de la colección de documentos se realiza sobre una matriz binaria documento–término, donde los términos han sido extraídos manualmente o automáticamente de los documentos y representan el contenido de los mismos.
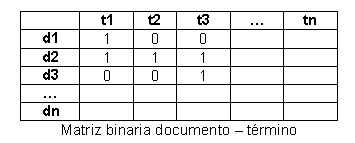
Las consultas se arman con términos vinculados por operadores lógicos (AND, OR, NOT) y los resultados son referencias a documentos donde cuya representación satisface las restricciones lógicas de la expresión de búsqueda. En el modelo original no hay ranking de relevancia sobre el conjunto de respuestas a una consulta, todos los documentos poseen la misma relevancia. A continuación se muestra un ejemplo mediante conjuntos de operaciones utilizando el modelo booleano.
A = {Documentos que contienen el término T1}
B = {Documentos que contienen el término T2}

Si bien es el primer modelo desarrollado y aún se lo utiliza, no es el preferido por los ingenieros de software para sus desarrollos. Existen diversos puntos en contra que hacen que cada día se lo utilice menos y – además – se han desarrollado algunas extensiones, bajo el nombre modelo booleano extendido [64] [51], que tratan de mejorar algunos puntos débiles.
2. Modelo Vectorial
Este modelo fue planteado y desarrollado por Gerard Salton [49] y – originalmente – se implementó en un SRI llamado SMART. Aunque el modelo posee más de treinta años, actualmente se sigue utilizando debido a su buena performance en la recuperación de documentos.
Conceptualmente, este modelo utiliza una matriz documento–término que contiene el vocabulario de la colección de referencia y los documentos existentes. En la intersección de un término t y un documento d se almacena un valor numérico de importancia del término t en el documento d; tal valor representa su poder de discriminación. Así, cada documento puede ser visto como un vector que pertenece a un espacio n-dimensional, donde n es la cantidad de términos que componen el vocabulario de la colección. En teoría, los documentos que contengan términos similares estarán a muy poca distancia entre sí sobre tal espacio. De igual forma se trata a la consulta, es un documento más y se la mapea sobre el espacio de documentos. Luego, a partir de una consulta dada es posible devolver una lista de documentos ordenados por distancia (los más relevantes primero). Para calcular la semejanza entre el vector consulta y los vectores que representan los documentos se utilizan diferentes fórmulas de distancia, siendo la más común la del coseno.
Obsérvese el siguiente ejemplo donde se representa a un documento d y a una consulta c:
Documento: “La República Argentina ha sido nominada para la realización del X Congreso Americano de Epidemiología en Zonas de Desastre. El evento se realizará ...”
Consulta: “argentina congreso epidemiología”

3. Modelo probabilístico
Fue propuesto por Robertson y Spark-Jones [47] con el objetivo de representar el proceso de recuperación de información desde el punto de vista de las probabilidades. A partir de una expresión de consulta se puede dividir una colección de N documentos en cuatro subconjuntos distintos: REL conjunto de documentos relevantes, REC conjunto de documentos recuperados, RR conjunto de documentos relevantes recuperados y NN el conjunto de documentos no relevantes no recuperados.
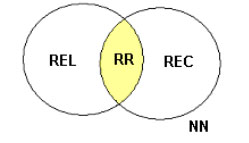
El resultado ideal de a una consulta se da cuando el conjunto REL es igual REC. Como resulta difícil lograrlo en primera intención, el usuario genera una descripción probabilística del conjunto REL y a través de sucesivas interacciones con el SRI se trata de mejorar la perfomance de recuperación. Dado que una recuperación no es inmediata dado que involucra varias interacciones con el usuario y que estudios han demostrado que su perfomance es inferior al modelo vectorial, su uso es bastante limitado.
4. Modelos para documentos estructurados
Los modelos clásicos responden a consultas, buscando sobre una estructura de datos que representa el contenido de los documentos de una colección, únicamente como listas de términos significativos. Un modelo de recuperación de documentos estructurados utiliza la estructura de los mismos a los efectos de mejorar la performance y brindar servicios alternativos al usuario (por ejemplo, uso de memoria visual, recuperación de elementos multimedia, mayor precisión sobre el ámbito de la consulta y demás).
La estructura de los documentos a indexar está dada por marcas o etiquetas, siendo los estándares más utilizados el SGML (Standard General Markup Language), el HTML (HyperText Markup Language), el XML (eXtensible Markup Language) y LATEX.
Al poseer la descripción de parte de la estructura de un documento es posible generar un grafo sobre el que se navegue y se respondan consultas de distinto tipo, por ejemplo:
–Por estructura: ¿Cuáles son las secciones del segundo capítulo?
–Por metadatos o campos: Documentos de “Editorial UNLu” editados en 1998
–Por contenido: Término “agua” en títulos de secciones
–Por elementos multimedia: Imágenes cercanas a párrafos que contengan Bush
Para Baeza-Yates existen dos modelos en esta categoría “nodos proximales” [37] y “listas no superpuestas” [8]. Ambos modelos se basan en almacenar las ocurrencias de los términos a indexar en estructuras de datos diferentes, según aparezcan en algún elemento de estructura (región) o en otro como capítulos, secciones, subsecciones y demás. En general, las regiones de una misma estructura de datos no poseen superposición, pero regiones en diferentes estructuras sí se pueden superponer.
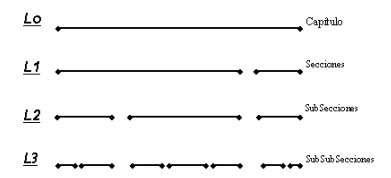
Nótese que en el ejemplo anterior existen cuatro niveles de listas para almacenar información relativa a contenido textual y estructura de un documento tipo libro. En general, los tipos de consultas soportados son simples:
· Seleccione una región que contenga una palabra dada
· Seleccione una región X que no que no contenga una región Y
· Seleccione una región contenida en otra región
Sobre el ejemplo de estructura planteado un ejemplo de consulta sería:
[subsección[+] CONTIENE “‘tambo” ]
Como respuesta el SRI buscaría subsecciones y sub-subsecciones que contengan el término “tambo“.
Cabe mencionar que algunos motores de búsqueda de Internet ya utilizan ciertos elementos de la estructura de un documento – por ejemplo, los títulos – a los efectos de realizar tareas de rankeo, resumen automático, clasificación y otras.
La expansión de estos lenguajes de demarcación, especialmente en servicios sobre Internet, hacen que se generen y publiquen cada vez más documentos semiestructurados. Es necesario – entonces – desarrollar técnicas que aprovechen el valor agregado de los nuevos documentos. Si bien – en la actualidad – éstas no se encuentran tan desarrolladas como los modelos tradicionales, consideramos su evolución como una cuestión importante en el área de RI, especialmente a partir de investigaciones con enfoques diferentes que abordan la problemática [18] [38] [45].
Referencias
[8] Burkowski, F. “Retrieval activities in a database consisting of heterogeneous collections of structured texts”. In Belkin, N., Ingwersen, P., Pejtersen, A. M., and Fox, E., editors, Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 112–125, New York. ACM Press. 1992.
[18] Egnor, D. y Lord, R. “Structured information retrieval using XML”. En: Proceedings of the ACM SIGIR 2000 Workshop on XML and Information Retrieval, Julio 2000.
[37] Navarro, G. y Baeza-Yates, R. “A language for queries on structure and contents of textual databases”. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 93-101, New York. ACM Press. 1995.
[38] Ogilvie, P. y Callan, J. “Language Models and Structured Document Retrieval”. En: Proceedings of the first INEX workshop, 2003.
[45] Raghavan, S. Y Garcia-Molina, H. “Integrating diverse information management systems: A brief survey”. IEEE Data Engineering Bulletin, 24(4):44-52, 2001.
[47] Robertson, S.E y Spark-Jones, K. “Relevance Weighting of Search terms”. Journal of Documentation. 33, p.126-148. 1976.
[49] Salton, G. (editor). “The SMART Retrieval System – Experiments in Automatic Document Processing”. Prentice Hall In. Englewood Cliffs, NJ. 1971.
[51] Salton, G.; Fox, E.A. y Wu, H. “Extended Boolean information retrieval”. Communications of the ACM, 26(11):1022-1036. Noviembre, 1983
[64] Waller, W. G. y Kraft, D. H. “A mathematical model for a weighted Boolean retrieval system”. Information Processing and Management, Vol 15, No. 5, pp. 235-245. 1979.

6 comentarios:
www.recursos-blog.blogspot.com
Hola, ¿qué tal? Dejo aquí una web mía donde explico modelos de recuperación de información. No lo explico mejor, pero sí de otra manera. Además, si gracias a este blog consigo que mi profesor vea la página en Google, aprobaría la asignatura y ¡¡os lo agradecería mucho!!
Modelos de recuperacion
Si el enlace no funciona:
http://modelosderecuperacion.iespana.es
Gracias!! Un saludo!!
Hola Fernando!
Soy de la cursada de este año en Taller Libre I (IR) que la dicta Gabriel Tolosa, y de casualidad (en realidad buscando mas información sobre el modelo probabilístico) me encontre con tu blog.
Esta muy bueno el apunte que armaste con el, es un buen resumen.
Bueno a lo que vengo, una pequeñisima colaboración: En la parte del Modelo Booleano,hay un error en el diagrama de ben, en la consulta T1 and NOT T2 el conjunto resultante debería ser la resta entre A y B.
Eso es todo, un saludo.
Gracias, se ha pasado por alto el marcado correcto en el gráfico de Venn. Ya estoy cambiando el dibujo de la negación de la implicación.
Saludos
Fernando
holla amigos,Me encanta su website,buen espacio, Te falta sólo una herramienta de traducción el resto tudo ok!
hasta
excusa mi mal espanol!
Yo estudié programación cuando estaba en el colegio y la verdad que me sirvió bastante porque pude empezar a trabajar para unos hoteles en Mendoza que mudaron su centro de desarrollos aquí. Hay muchas empresas de Buenos Aires que están haciendo lo mismo, asumo que será mejor para los costos.
Publicar un comentario