Hace nos días atrás, la organización Pew Internet & American Life Project, dedicada a realizar estudios de opinión pública en USA, presentó un nuevo informe titulado “The Internet as a Resource for News and Information about Science” . Los resultados más significativos son:
La televisión está en primer lugar y luego Internet cuando los usuarios desean obtener Información científica. El 41% obtiene la mayoría de la información de la TV, el 20% de Internet, el 14% de los periódicos y un 4% de las radios. En cambio, los usuarios con conexiones de banda ancha indican que el 34% obtiene información científica de la red y el 33% de la TV.
Del estudio se desprende que ,aparentemente, Internet es la primer fuente sobre la cual acude la gente cuando necesita información sobre un tema científico específico.
Para el 87% de los usuarios americanos (128 millones de adultos) Internet es una herramienta de investigación. Donde, por ejemplo, el 70% de los usuarios ha usado la red, alguna vez, para buscar el significado de un término científico. El 65% uso Internet para aprender cosas sobre historia de la ciencia. El 55 % uso la red para verificar hechos científicos o estadísticas. El 43% ha descargado datos científicos o gráficos.
Los buscadores representan la fuente más popular para comenzar una investigación sobre temas científicos entre aquellos usuarios que usan Internet como primer lugar para obtener tal tipo de información.
La mitad de todos usuarios de internet han visitado un sitio especializado en contenidos científicos.. Por ejemplo, un 23% ha visitado National Geographic, un 19% nasa.gov, un 14% Smithsonian site, 10% sience.com y 9% nture.com.
Cerca del 80% de los usuarios que buscan información en línea intenta comprobar su exactitud en otro sitio.
jueves, noviembre 30, 2006
Técnica para facilitar búsquedas tolerantes a errores en la consulta o en el índice
Esto días estuve revisando algoritmos de apoyo a la ortografía y encontré una página donde se presenta una técnica basada en el uso de ngramas. Cada término del diccionario se divide en trigramas -segmentos de tres caracteres (casa = 6 trigramas {--c, -ca, cas, asa, sa-, a--})- y se almacenan en una tabla índice (trigrama(“a—“)=doc1, doc5,...,doc_n). Luego, cuando un usuario necesita consultar por un término al mismo se lo descompone en sus trigramas y se recuperan las entradas del índice relacionadas con cada uno de ellos. A continuación se aplica una fórmula de semejanza ortográfica (yo la conozco como distancia de Tanimoto) entre el término consultado y los distintos términos candidatos aportados por el índice. Si la semejanza supera un umbral U entonces se muestra el término como posible candidato en la respuesta. La salida de términos puede ordenarse por distancia con respecto al término de la consulta.
Hace unos años atrás un ex alumno Diego Barrientos puso a punto y valido una técnica semejante, la cual usamos para corrección ortográfica o sugerencias del tipo Google "Ud. quizo decir". Aquí pueden hallar un documento que habla acerca del algoritmo y aquí encuentran unas librerías C desarrolladas por Diego.El trabajo aún no está totalmente finalizado, se puede mejorar la calidad de las sugerencias utilizando técnicas que permitan manejar los casos de empate de términos candidatos en las listas de sugerencias, una posible herramienta sería modelos de lenguaje. SI hay alguien que le interese el tema y el C podemos discutirlo.
Hace unos años atrás un ex alumno Diego Barrientos puso a punto y valido una técnica semejante, la cual usamos para corrección ortográfica o sugerencias del tipo Google "Ud. quizo decir". Aquí pueden hallar un documento que habla acerca del algoritmo y aquí encuentran unas librerías C desarrolladas por Diego.El trabajo aún no está totalmente finalizado, se puede mejorar la calidad de las sugerencias utilizando técnicas que permitan manejar los casos de empate de términos candidatos en las listas de sugerencias, una posible herramienta sería modelos de lenguaje. SI hay alguien que le interese el tema y el C podemos discutirlo.
miércoles, noviembre 29, 2006
Off topic: Blogs amigos
Quería presentar en sociedad a un par de blogs de dos colegas, en estos caminos de la informática. Son fanáticos linuxeros y de la programación, bichos raros de los cuales hay pocos. Cuando tengan tiempo paseen por el "El Blog de Marcelo!" y "El Bit Negro". A ver si somos más y así podemos armar una comunidad y hasta tener un planet propio.
Telenoche, uso o abuso de la Wikipedia?
Recién mientras escribía, estaba escuchando en background el noticiero de canal 13 Telenoche. Alrededor de las 20:34 un señor periodista presenta una nota donde recuerda a George Harrison a 5 años de su muerte. Entre los datos que presentó, uno en particular me llamó la atención -el cual dice que fué pionero de la música electrónica- y decidí ir las páginas (ingles, español) de la Wikipedia a los efectos obtener mayor información. Ohhh, para mi agradable sorpresa el periodista estaba leyendo párrafos de las páginas. Pienso que bien !!! una institución tan noble como Telenoche utiliza tal fuente, lo cual le da importancia y la realza. Pero para mi corta alegría noto que al final no hay crédito a la misma, la Wipidedia fué ignorada totalmente.
Muchachos, por respeto a las decenas de miles de personas que construyen y preservan el conocimiento de la humanidad, la próxima vez den crédito.
Muchachos, por respeto a las decenas de miles de personas que construyen y preservan el conocimiento de la humanidad, la próxima vez den crédito.
Relevamiento sobre razones para escribir un blog
Estuve leyendo en Microsiervos una entrada sobre un trabajo realizado por Lorena Loretahur que consistió en entrevistar a una serie de bloggers a los efectos de determinar que los motiva a escribir. Tales respuestas han sido compiladas en un documento titulado "¿Por qué escribes en tu blog?". Todavía no lo he leido pero podría ser una buena fuente de datos para investigaciones sobre motivaciones en redes sociales.
martes, noviembre 28, 2006

Tutorial sobre blogs
"El abecé del universo blog" de Antonio Fumero, publicado en Telos: Cuadernos de Comunicación Tecnología y Sociedad es un tutorial distinto. Más allá de la historia y de qué son y cómo se usan y etc, etc,etc. Fumero presenta el concepto de socialware (esta palabra se la escuche por primera vez al profesor Saroka a principios de la decada de los 80 en una conferencia auspiciada por la Cooperativa Eléctrica de la Ciudad de Luján) y desarrolla bien este componente que tiene que ver con la comunidad que sustenta tales aplicaciones.
Paper que presenta un modelo de un sistema de etiquetado
El artículo de Marlow y otros "HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, ToRead" trata sobre la técnica de etiquetado o tags y presenta una revisión de trabajos académicos relacionados. Como aporte adicional presenta un modelo de un sistema de etiquetado y una taxonomía. Por otro lado trata el tema de cuales son los incentivos para que los usuarios contribuyan adosando etiquetas a distintos recursos.
Cita: "HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, ToRead." Cameron Marlow, Mor Naaman, danah boyd, Marc Davis. Proceedings of Hypertext 2006, New York: ACM Press, 2006.
Disponible en: http://www.danah.org/papers/Hypertext2006.pdf
Cita: "HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, ToRead." Cameron Marlow, Mor Naaman, danah boyd, Marc Davis. Proceedings of Hypertext 2006, New York: ACM Press, 2006.
Disponible en: http://www.danah.org/papers/Hypertext2006.pdf
Conocen a Tagsonomy?
Tagsonomy es un blog dedicado exclusivamente a presentar noticias y discutir aspectos relacionados con los tags o etiquetas. Estuve revisando las últimas entradas, el sitio parece útil y tiene información interesante para ayudar a estudiar el tema de las comunidades digitales. El problema es la frecuencia de los posts, es muy baja.
lunes, noviembre 27, 2006
Libros para descargar
La semana pasada Leo envío un correo a la lista Grulic donde nos regalaba tres entradas a libros libres para descargar. Me pareció útil y afín la temática, por eso quiero compartirlos.
Jordi Mas i Hernàndez, “Software libre: técnicamente viable, económicamente sostenible y socialmente justo” primera edición, 2005. Disponible en http://www.softcatala.org/~jmas/swl/llibrejmas.pdf
Beatriz Busaniche et al. “Prohibido pensar, propiedad privada : los monopolios sobre la vida, el conocimiento y la cultura - 1a ed., Córdoba : Fundación Vía Libre, 2006.
Disponible en http://www.vialibre.org.ar/wp-content/uploads/2006/11/prohibidopensarpropiedadprivada.pdf
David Bueno. “Copia este libro”, Ed. Dmem S.L., 2005. Disponible en http://www.rebelion.org/docs/23824.pdf
Jordi Mas i Hernàndez, “Software libre: técnicamente viable, económicamente sostenible y socialmente justo” primera edición, 2005. Disponible en http://www.softcatala.org/~jmas/swl/llibrejmas.pdf
Beatriz Busaniche et al. “Prohibido pensar, propiedad privada : los monopolios sobre la vida, el conocimiento y la cultura - 1a ed., Córdoba : Fundación Vía Libre, 2006.
Disponible en http://www.vialibre.org.ar/wp-content/uploads/2006/11/prohibidopensarpropiedadprivada.pdf
David Bueno. “Copia este libro”, Ed. Dmem S.L., 2005. Disponible en http://www.rebelion.org/docs/23824.pdf
Entrevista a Enrique Dans
Enrique es profesor en el área de tecnologías de la información en España, pero además es un analista que tiene una visión crítica y acertada de los fenómenos de usuario de Internet. He leido un reportaje publicado en Baquia y extraje algunas partes que me gustaría compartir con Uds.
Cuando se le pregunta acerca del spam responde “...el spam, en realidad, vive de una asimetría de conocimiento: el crecimiento de la Red es tan grande que el spam se nutre de las personas con poca experiencia que contestan a sus mensajes... Con el tiempo se popularizará el conocimiento acerca del spam, la cantidad de gente que contesta a ese tipo de mensajes será cada vez menor y el correo basura desaparecerá...”
Acerca del movimiento web 2.0 indica que brinda “...la posibilidad de desempeñar un papel activo. No se trata de que tengas que tener un blog, ni que estés obligado a comentar en ningún sitio, sino que, si te apetece hacerlo, tendrás sitio para ello, vivirás una actitud abierta y participativa. En breve, los sitios unidireccionales nos parecerán cosa del pasado, y cuando un medio no nos ofrezca ese tipo de prestaciones, nos encontraremos raros, incómodos...”
“...La brecha digital se reduce con servicios y contenidos de calidad, creando propuestas de valor adecuadas. ...Los poderes públicos deben limitarse a poner infraestructuras al alcance del usuario, cediendo por ejemplo el uso de sus infraestructuras a operadores en libre competencia que ofrezcan conectividad en unas condiciones interesantes para sus posibles clientes, compitiendo entre sí en mercados no distorsionados...”
Cuando se le pregunta acerca del spam responde “...el spam, en realidad, vive de una asimetría de conocimiento: el crecimiento de la Red es tan grande que el spam se nutre de las personas con poca experiencia que contestan a sus mensajes... Con el tiempo se popularizará el conocimiento acerca del spam, la cantidad de gente que contesta a ese tipo de mensajes será cada vez menor y el correo basura desaparecerá...”
Acerca del movimiento web 2.0 indica que brinda “...la posibilidad de desempeñar un papel activo. No se trata de que tengas que tener un blog, ni que estés obligado a comentar en ningún sitio, sino que, si te apetece hacerlo, tendrás sitio para ello, vivirás una actitud abierta y participativa. En breve, los sitios unidireccionales nos parecerán cosa del pasado, y cuando un medio no nos ofrezca ese tipo de prestaciones, nos encontraremos raros, incómodos...”
“...La brecha digital se reduce con servicios y contenidos de calidad, creando propuestas de valor adecuadas. ...Los poderes públicos deben limitarse a poner infraestructuras al alcance del usuario, cediendo por ejemplo el uso de sus infraestructuras a operadores en libre competencia que ofrezcan conectividad en unas condiciones interesantes para sus posibles clientes, compitiendo entre sí en mercados no distorsionados...”
domingo, noviembre 26, 2006
OLPC Argentina: Ruego a Dios que nuestros representantes sean eficaces y eficientes
La semana pasada en la casa de gobierno argentino se reunió el presidente Kirchner y Nicholas Negroponte a los efectos de empezar a cerrar el acuerdo de la “posible” adquisición de computadoras portátiles económicas. Del millón inicial solo empezaremos con unas 500, para probar y luego vemos (las cuales se entregarán antes de fin de año). Esta información es oficial y está publicada en el sitio de la casa rosada. Gracias por el dato Pablo Mancini.
Lo raro, y que todavía no me convence del proyecto, es que el grupo argentino oficial no ha abierto el juego a universidades, organizaciones profesionales y a organizaciones de usuarios, dado que esta gente está en todo el país y es la que puede 1) desarrollar soft, 2) seleccionar soft, 3) ver usos alternativos de la plataforma, 4) ayudar a construir servicios, 5) establecer redes sociales destinadas al desarrollo del alumno y su contexto familiar, 6) dar soporte técnico al alumno, la escuela, 7) ayudar a capacitar a los docentes, etc, etc, etc. Es decir a apropiarse de la tecnología en tiempo y forma, acordémonos que cuando en estos lares adquirimos un aparato electrónico ya es viejo y lo debemos amortizar en la menor cantidad de tiempo.
En este proyecto como pueblo argentino debemos ser eficaces (que llegue a todo destinatario) y eficientes ( que se use con propiedad) dado que es nuestro dinero el que se usó para comprar, por eso los que algo de tecnología manejamos debemos pedir a nuestros representantes una inversión racional. No tengan miedo en invertir en educación (solo la educación es la que hace a un soberano, el no tenerla la convierte en esclavo) pero háganlo de frente y con la sociedad y no de espaldas y para la foto (es una p. costumbre de los políticos en todos los niveles, decanos, rectores, ministros concejales, etc, etc.).
En el sitio Educ.ar pueden acceder al audio de una conferencia de hace unos meses atrás donde se explica en que consiste el proyecto OLPC y que beneficios brindaría.
Con mi deseo de éxito, saludos a todos
Lo raro, y que todavía no me convence del proyecto, es que el grupo argentino oficial no ha abierto el juego a universidades, organizaciones profesionales y a organizaciones de usuarios, dado que esta gente está en todo el país y es la que puede 1) desarrollar soft, 2) seleccionar soft, 3) ver usos alternativos de la plataforma, 4) ayudar a construir servicios, 5) establecer redes sociales destinadas al desarrollo del alumno y su contexto familiar, 6) dar soporte técnico al alumno, la escuela, 7) ayudar a capacitar a los docentes, etc, etc, etc. Es decir a apropiarse de la tecnología en tiempo y forma, acordémonos que cuando en estos lares adquirimos un aparato electrónico ya es viejo y lo debemos amortizar en la menor cantidad de tiempo.
En este proyecto como pueblo argentino debemos ser eficaces (que llegue a todo destinatario) y eficientes ( que se use con propiedad) dado que es nuestro dinero el que se usó para comprar, por eso los que algo de tecnología manejamos debemos pedir a nuestros representantes una inversión racional. No tengan miedo en invertir en educación (solo la educación es la que hace a un soberano, el no tenerla la convierte en esclavo) pero háganlo de frente y con la sociedad y no de espaldas y para la foto (es una p. costumbre de los políticos en todos los niveles, decanos, rectores, ministros concejales, etc, etc.).
En el sitio Educ.ar pueden acceder al audio de una conferencia de hace unos meses atrás donde se explica en que consiste el proyecto OLPC y que beneficios brindaría.
Con mi deseo de éxito, saludos a todos
sábado, noviembre 25, 2006
Software social como recurso para mejorar comunidades de inteligencia
Estuve leyendo un trabajo del Dr Andrus, miembro de la Central de Agencia Americana, en el cual evalúa el uso de wikis y blogs en comunidades de inteligencia mundial con la finalidad de mejorar el intercambio de información. Me pareció muy buena la parte descriptiva deherramientas de auto organización.
El trabajo se llama "The Wiki and the Blog: Toward a Complex Adaptive Intelligence Community" y fué publicado en la revista "Studies in Intelligence", Vol 49, No 3, September 2005.
El trabajo se llama "The Wiki and the Blog: Toward a Complex Adaptive Intelligence Community" y fué publicado en la revista "Studies in Intelligence", Vol 49, No 3, September 2005.
jueves, noviembre 23, 2006
Recuperación de información en el espacio web
Por Gabriel Tolosa y Fernando Bordignon
Con la aparición de la web surgieron nuevos desafíos para resolver en el área de recuperación de información debido – principalmente – a sus características y su tamaño. La web puede ser vista como un gran repositorio de información, completamente distribuido sobre Internet y accesible por gran cantidad de usuarios. Por sus orígenes como un espacio público existen millones de organizaciones y usuarios particulares que incorporan, quitan ó modifican contenido continuamente, por lo que su estructura no es estática.
Su contenido no respeta estándares de calidad, ni estilos ni organización. Como medio de publicación de información de naturaleza diversa se ha convertido en un servicio de permanente crecimiento. Una de las características de la información publicada en la web es su dinamismo, dado que pueden variar en el tiempo tanto los contenidos como su ubicación [6] [33].
El tamaño de la web es imposible de medir exactamente y muy difícil de estimar. Sin embargo, se calcula que son decenas de terabytes de información, y crece permanentemente. Está formada por documentos de diferente naturaleza y formato, desde páginas HTML hasta archivos de imágenes pasando por gran cantidad de formatos estándar y propietarios, no solamente con contenido textual, sino también con contenido multimedial.
La búsqueda de información en la web es una práctica común para los usuarios de Internet y los sistemas de recuperación de información web (conocidos como motores de búsqueda) se han convertido en herramientas indispensables para los usuarios. Su arquitectura y modo de operación se basan en poder recolectar mediante un mecanismo adecuado los documentos existentes en los sitios web. Una vez obtenidos, se llevan a cabo tareas de procesamiento que permiten extraer términos significativos contenidos dentro de los mismos, junto con otra información, a los efectos de construir estructuras de datos (índices) que permitan realizar búsquedas de manera eficiente. Luego, a partir de una consulta realizada por un usuario, un motor de búsqueda extraerá de los índices las referencias que satisfagan la consulta y se retornará una respuesta rankeada por diversos criterios al usuario. El modo de funcionamiento de los diferentes motores de búsqueda puede diferir en diversas implementaciones de los mecanismos de recolección de datos, los métodos de indexación y los algoritmos de búsqueda y rankeo.
Sin embargo, esta tarea no es sencilla y se ha convertido en un desafío para los SRI debido las características propias de la web. Baeza-Yates [2] plantea que hay desafíos de dos tipos:
a) Respecto de los datos
– Distribuidos: La web es un sistema distribuido, donde cada proveedor de información publica su información en computadoras pertenecientes a redes conectadas a Internet, sin una estructura ó topología predefinida.
– Volátiles: El dinamismo del sistema hace que exista información nueva a cada momento ó bien que cambie su contenido ó inclusive desaparezca otra que se encontraba disponible.
– No estructurados y redundantes: Básicamente, la web está formada de páginas HTML, las cuales no cuentan con una estructura única ni fija. Además, mucho del contenido se encuentra duplicado (por ejemplo, espejado).
– Calidad: En general, la calidad de la información publicada en la web es altamente variable, tanto en escritura como en actualización (existe información que puede considerarse obsoleta), e inclusive existe información con errores sintácticos, ortográficos y demás.
– Heterogeneidad: La información se puede encontrar publicada en diferentes tipos de medios (texto, audio, gráficos) con diferentes formatos para cada uno de éstos. Además, hay que contemplar los diferentes idiomas y diferentes alfabetos (por ejemplo, árabe ó chino).
b) Respecto de los usuarios.
– Especificación de la consulta: Los usuarios encuentran dificultades para precisar – en el lenguaje de consulta – su necesidad de información.
– Manejo de las respuestas: Cuando un usuario realiza una consulta se ve sobrecargado de respuestas, siendo una parte irrelevante.
Estas características – sumadas al tamaño de la web – imponen restricciones a las herramientas de búsqueda en cuanto a la cobertura y acceso a los documentos, exigiendo cada vez mayores recursos computacionales (espacio de almacenamiento, ancho de banda de las redes, ciclos de CPU) y diferentes estrategias para mejorar la calidad de las respuestas.
Referencias
[2] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[6] Brewington, B. E. y Cybenko Thayer, G. “How Dynamic is the Web?” En: Proceedings of the Ninth International World Wide Web Conference. 2000.
[33] Lawrence, S. y Giles, L. “Accessibility and Distribution of Information on the Web”. Nature, vol.400, n.6740, pags.107-109. 1999.
Con la aparición de la web surgieron nuevos desafíos para resolver en el área de recuperación de información debido – principalmente – a sus características y su tamaño. La web puede ser vista como un gran repositorio de información, completamente distribuido sobre Internet y accesible por gran cantidad de usuarios. Por sus orígenes como un espacio público existen millones de organizaciones y usuarios particulares que incorporan, quitan ó modifican contenido continuamente, por lo que su estructura no es estática.
Su contenido no respeta estándares de calidad, ni estilos ni organización. Como medio de publicación de información de naturaleza diversa se ha convertido en un servicio de permanente crecimiento. Una de las características de la información publicada en la web es su dinamismo, dado que pueden variar en el tiempo tanto los contenidos como su ubicación [6] [33].
El tamaño de la web es imposible de medir exactamente y muy difícil de estimar. Sin embargo, se calcula que son decenas de terabytes de información, y crece permanentemente. Está formada por documentos de diferente naturaleza y formato, desde páginas HTML hasta archivos de imágenes pasando por gran cantidad de formatos estándar y propietarios, no solamente con contenido textual, sino también con contenido multimedial.
La búsqueda de información en la web es una práctica común para los usuarios de Internet y los sistemas de recuperación de información web (conocidos como motores de búsqueda) se han convertido en herramientas indispensables para los usuarios. Su arquitectura y modo de operación se basan en poder recolectar mediante un mecanismo adecuado los documentos existentes en los sitios web. Una vez obtenidos, se llevan a cabo tareas de procesamiento que permiten extraer términos significativos contenidos dentro de los mismos, junto con otra información, a los efectos de construir estructuras de datos (índices) que permitan realizar búsquedas de manera eficiente. Luego, a partir de una consulta realizada por un usuario, un motor de búsqueda extraerá de los índices las referencias que satisfagan la consulta y se retornará una respuesta rankeada por diversos criterios al usuario. El modo de funcionamiento de los diferentes motores de búsqueda puede diferir en diversas implementaciones de los mecanismos de recolección de datos, los métodos de indexación y los algoritmos de búsqueda y rankeo.
Sin embargo, esta tarea no es sencilla y se ha convertido en un desafío para los SRI debido las características propias de la web. Baeza-Yates [2] plantea que hay desafíos de dos tipos:
a) Respecto de los datos
– Distribuidos: La web es un sistema distribuido, donde cada proveedor de información publica su información en computadoras pertenecientes a redes conectadas a Internet, sin una estructura ó topología predefinida.
– Volátiles: El dinamismo del sistema hace que exista información nueva a cada momento ó bien que cambie su contenido ó inclusive desaparezca otra que se encontraba disponible.
– No estructurados y redundantes: Básicamente, la web está formada de páginas HTML, las cuales no cuentan con una estructura única ni fija. Además, mucho del contenido se encuentra duplicado (por ejemplo, espejado).
– Calidad: En general, la calidad de la información publicada en la web es altamente variable, tanto en escritura como en actualización (existe información que puede considerarse obsoleta), e inclusive existe información con errores sintácticos, ortográficos y demás.
– Heterogeneidad: La información se puede encontrar publicada en diferentes tipos de medios (texto, audio, gráficos) con diferentes formatos para cada uno de éstos. Además, hay que contemplar los diferentes idiomas y diferentes alfabetos (por ejemplo, árabe ó chino).
b) Respecto de los usuarios.
– Especificación de la consulta: Los usuarios encuentran dificultades para precisar – en el lenguaje de consulta – su necesidad de información.
– Manejo de las respuestas: Cuando un usuario realiza una consulta se ve sobrecargado de respuestas, siendo una parte irrelevante.
Estas características – sumadas al tamaño de la web – imponen restricciones a las herramientas de búsqueda en cuanto a la cobertura y acceso a los documentos, exigiendo cada vez mayores recursos computacionales (espacio de almacenamiento, ancho de banda de las redes, ciclos de CPU) y diferentes estrategias para mejorar la calidad de las respuestas.
Referencias
[2] Baeza-Yates, R. y Ribeiro-Neto, B. “Modern Information Retrieval”. ACM Press. Addison Wesley. 1999.
[6] Brewington, B. E. y Cybenko Thayer, G. “How Dynamic is the Web?” En: Proceedings of the Ninth International World Wide Web Conference. 2000.
[33] Lawrence, S. y Giles, L. “Accessibility and Distribution of Information on the Web”. Nature, vol.400, n.6740, pags.107-109. 1999.
Anécdotas por Adrián Paenza
El amigo Paenza, en una columna de hace unos meses atrás en Página 12, nos trae una serie de anécdotas que relacionan a Google y a un par de matemáticos argentinos. Gracias por el dato compañero Victorio.:-)
Comparativa sobre repositorios de documentos
En Nueva Zelandia existe un proyecto denominado "Open Access
Repositories in New Zealand".El grupo de trabajo ha presentado una nueva versión de un documento donde comparan tres alternativas basadas software open source: Dspace, Eprints y Fedora.
Hay buena información técnica acerca de las capacidades de cada plataforma.
Repositories in New Zealand".El grupo de trabajo ha presentado una nueva versión de un documento donde comparan tres alternativas basadas software open source: Dspace, Eprints y Fedora.
Hay buena información técnica acerca de las capacidades de cada plataforma.
miércoles, noviembre 22, 2006
Mapa conceptual de tecnología web
En el blog Modern Life is Rubbish presentan un grafo que trata de ilustrar las distintas tecnologías web y sus relaciones.

Paquetes de soft en azul, lenguajes en beige, tecnologías centrales o de core en verde e infraestructura en gris. Para mi gusto le faltan tecnologías y algunas relaciones más, pero es un buen comienzo.
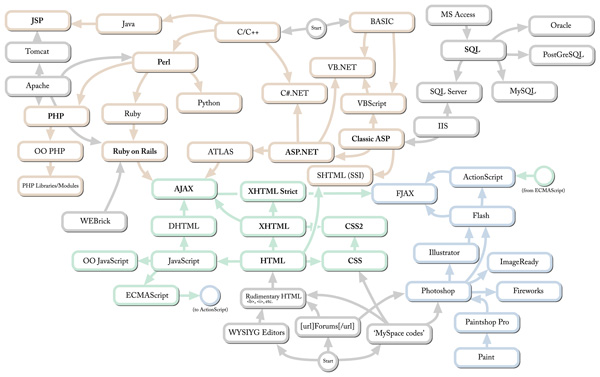
Paquetes de soft en azul, lenguajes en beige, tecnologías centrales o de core en verde e infraestructura en gris. Para mi gusto le faltan tecnologías y algunas relaciones más, pero es un buen comienzo.
lunes, noviembre 20, 2006
Modelos de Recuperación de Información
Por Gabriel Tolosa y Fernando Bordignon.
Los SRI (sistemas de recuperación de información)toman un conjunto de documentos (colección) para procesar y luego poder responder consultas. De forma básica, podemos clasificar los documentos en estructurados y no estructurados. Los primeros son aquellos en los que se pueden reconocer elementos estructurales con una semántica bien definida, mientras que los segundos corresponden a texto libre, sin formato. La diferencia fundamental de un SRI que procese documentos estructurados se encuentra en que puede extraer información adicional al contenido textual, la cual utiliza en la etapa de recuperación para facilitar la tarea y aumentar las prestaciones.
A partir de lo expresado anteriormente se presenta una posible clasificación de modelos de RI – la cual no es exhaustiva – de acuerdo a características estructurales de los documentos.

A continuación se describen – de forma somera – los modelos clásicos y el álgebra de regiones. Más adelante, en el capítulo 4, se profundizará en los modelos booleano y vectorial.
1. Modelo booleano
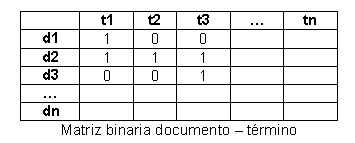
En el modelo booleano la representación de la colección de documentos se realiza sobre una matriz binaria documento–término, donde los términos han sido extraídos manualmente o automáticamente de los documentos y representan el contenido de los mismos.

Las consultas se arman con términos vinculados por operadores lógicos (AND, OR, NOT) y los resultados son referencias a documentos donde cuya representación satisface las restricciones lógicas de la expresión de búsqueda. En el modelo original no hay ranking de relevancia sobre el conjunto de respuestas a una consulta, todos los documentos poseen la misma relevancia. A continuación se muestra un ejemplo mediante conjuntos de operaciones utilizando el modelo booleano.
A = {Documentos que contienen el término T1}
B = {Documentos que contienen el término T2}

Si bien es el primer modelo desarrollado y aún se lo utiliza, no es el preferido por los ingenieros de software para sus desarrollos. Existen diversos puntos en contra que hacen que cada día se lo utilice menos y – además – se han desarrollado algunas extensiones, bajo el nombre modelo booleano extendido [64] [51], que tratan de mejorar algunos puntos débiles.
2. Modelo Vectorial
Este modelo fue planteado y desarrollado por Gerard Salton [49] y – originalmente – se implementó en un SRI llamado SMART. Aunque el modelo posee más de treinta años, actualmente se sigue utilizando debido a su buena performance en la recuperación de documentos.
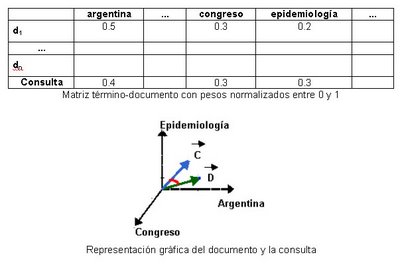
Conceptualmente, este modelo utiliza una matriz documento–término que contiene el vocabulario de la colección de referencia y los documentos existentes. En la intersección de un término t y un documento d se almacena un valor numérico de importancia del término t en el documento d; tal valor representa su poder de discriminación. Así, cada documento puede ser visto como un vector que pertenece a un espacio n-dimensional, donde n es la cantidad de términos que componen el vocabulario de la colección. En teoría, los documentos que contengan términos similares estarán a muy poca distancia entre sí sobre tal espacio. De igual forma se trata a la consulta, es un documento más y se la mapea sobre el espacio de documentos. Luego, a partir de una consulta dada es posible devolver una lista de documentos ordenados por distancia (los más relevantes primero). Para calcular la semejanza entre el vector consulta y los vectores que representan los documentos se utilizan diferentes fórmulas de distancia, siendo la más común la del coseno.
Obsérvese el siguiente ejemplo donde se representa a un documento d y a una consulta c:
Documento: “La República Argentina ha sido nominada para la realización del X Congreso Americano de Epidemiología en Zonas de Desastre. El evento se realizará ...”
Consulta: “argentina congreso epidemiología”
3. Modelo probabilístico
Fue propuesto por Robertson y Spark-Jones [47] con el objetivo de representar el proceso de recuperación de información desde el punto de vista de las probabilidades. A partir de una expresión de consulta se puede dividir una colección de N documentos en cuatro subconjuntos distintos: REL conjunto de documentos relevantes, REC conjunto de documentos recuperados, RR conjunto de documentos relevantes recuperados y NN el conjunto de documentos no relevantes no recuperados.
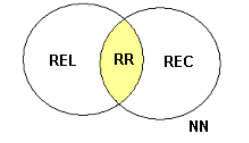
El resultado ideal de a una consulta se da cuando el conjunto REL es igual REC. Como resulta difícil lograrlo en primera intención, el usuario genera una descripción probabilística del conjunto REL y a través de sucesivas interacciones con el SRI se trata de mejorar la perfomance de recuperación. Dado que una recuperación no es inmediata dado que involucra varias interacciones con el usuario y que estudios han demostrado que su perfomance es inferior al modelo vectorial, su uso es bastante limitado.
4. Modelos para documentos estructurados
Los modelos clásicos responden a consultas, buscando sobre una estructura de datos que representa el contenido de los documentos de una colección, únicamente como listas de términos significativos. Un modelo de recuperación de documentos estructurados utiliza la estructura de los mismos a los efectos de mejorar la performance y brindar servicios alternativos al usuario (por ejemplo, uso de memoria visual, recuperación de elementos multimedia, mayor precisión sobre el ámbito de la consulta y demás).
La estructura de los documentos a indexar está dada por marcas o etiquetas, siendo los estándares más utilizados el SGML (Standard General Markup Language), el HTML (HyperText Markup Language), el XML (eXtensible Markup Language) y LATEX.
Al poseer la descripción de parte de la estructura de un documento es posible generar un grafo sobre el que se navegue y se respondan consultas de distinto tipo, por ejemplo:
–Por estructura: ¿Cuáles son las secciones del segundo capítulo?
–Por metadatos o campos: Documentos de “Editorial UNLu” editados en 1998
–Por contenido: Término “agua” en títulos de secciones
–Por elementos multimedia: Imágenes cercanas a párrafos que contengan Bush
Para Baeza-Yates existen dos modelos en esta categoría “nodos proximales” [37] y “listas no superpuestas” [8]. Ambos modelos se basan en almacenar las ocurrencias de los términos a indexar en estructuras de datos diferentes, según aparezcan en algún elemento de estructura (región) o en otro como capítulos, secciones, subsecciones y demás. En general, las regiones de una misma estructura de datos no poseen superposición, pero regiones en diferentes estructuras sí se pueden superponer.

Nótese que en el ejemplo anterior existen cuatro niveles de listas para almacenar información relativa a contenido textual y estructura de un documento tipo libro. En general, los tipos de consultas soportados son simples:
· Seleccione una región que contenga una palabra dada
· Seleccione una región X que no que no contenga una región Y
· Seleccione una región contenida en otra región
Sobre el ejemplo de estructura planteado un ejemplo de consulta sería:
[subsección[+] CONTIENE “‘tambo” ]
Como respuesta el SRI buscaría subsecciones y sub-subsecciones que contengan el término “tambo“.
Cabe mencionar que algunos motores de búsqueda de Internet ya utilizan ciertos elementos de la estructura de un documento – por ejemplo, los títulos – a los efectos de realizar tareas de rankeo, resumen automático, clasificación y otras.
La expansión de estos lenguajes de demarcación, especialmente en servicios sobre Internet, hacen que se generen y publiquen cada vez más documentos semiestructurados. Es necesario – entonces – desarrollar técnicas que aprovechen el valor agregado de los nuevos documentos. Si bien – en la actualidad – éstas no se encuentran tan desarrolladas como los modelos tradicionales, consideramos su evolución como una cuestión importante en el área de RI, especialmente a partir de investigaciones con enfoques diferentes que abordan la problemática [18] [38] [45].
Referencias
[8] Burkowski, F. “Retrieval activities in a database consisting of heterogeneous collections of structured texts”. In Belkin, N., Ingwersen, P., Pejtersen, A. M., and Fox, E., editors, Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 112–125, New York. ACM Press. 1992.
[18] Egnor, D. y Lord, R. “Structured information retrieval using XML”. En: Proceedings of the ACM SIGIR 2000 Workshop on XML and Information Retrieval, Julio 2000.
[37] Navarro, G. y Baeza-Yates, R. “A language for queries on structure and contents of textual databases”. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 93-101, New York. ACM Press. 1995.
[38] Ogilvie, P. y Callan, J. “Language Models and Structured Document Retrieval”. En: Proceedings of the first INEX workshop, 2003.
[45] Raghavan, S. Y Garcia-Molina, H. “Integrating diverse information management systems: A brief survey”. IEEE Data Engineering Bulletin, 24(4):44-52, 2001.
[47] Robertson, S.E y Spark-Jones, K. “Relevance Weighting of Search terms”. Journal of Documentation. 33, p.126-148. 1976.
[49] Salton, G. (editor). “The SMART Retrieval System – Experiments in Automatic Document Processing”. Prentice Hall In. Englewood Cliffs, NJ. 1971.
[51] Salton, G.; Fox, E.A. y Wu, H. “Extended Boolean information retrieval”. Communications of the ACM, 26(11):1022-1036. Noviembre, 1983
[64] Waller, W. G. y Kraft, D. H. “A mathematical model for a weighted Boolean retrieval system”. Information Processing and Management, Vol 15, No. 5, pp. 235-245. 1979.
Los SRI (sistemas de recuperación de información)toman un conjunto de documentos (colección) para procesar y luego poder responder consultas. De forma básica, podemos clasificar los documentos en estructurados y no estructurados. Los primeros son aquellos en los que se pueden reconocer elementos estructurales con una semántica bien definida, mientras que los segundos corresponden a texto libre, sin formato. La diferencia fundamental de un SRI que procese documentos estructurados se encuentra en que puede extraer información adicional al contenido textual, la cual utiliza en la etapa de recuperación para facilitar la tarea y aumentar las prestaciones.
A partir de lo expresado anteriormente se presenta una posible clasificación de modelos de RI – la cual no es exhaustiva – de acuerdo a características estructurales de los documentos.

A continuación se describen – de forma somera – los modelos clásicos y el álgebra de regiones. Más adelante, en el capítulo 4, se profundizará en los modelos booleano y vectorial.
1. Modelo booleano
En el modelo booleano la representación de la colección de documentos se realiza sobre una matriz binaria documento–término, donde los términos han sido extraídos manualmente o automáticamente de los documentos y representan el contenido de los mismos.
Las consultas se arman con términos vinculados por operadores lógicos (AND, OR, NOT) y los resultados son referencias a documentos donde cuya representación satisface las restricciones lógicas de la expresión de búsqueda. En el modelo original no hay ranking de relevancia sobre el conjunto de respuestas a una consulta, todos los documentos poseen la misma relevancia. A continuación se muestra un ejemplo mediante conjuntos de operaciones utilizando el modelo booleano.
A = {Documentos que contienen el término T1}
B = {Documentos que contienen el término T2}

Si bien es el primer modelo desarrollado y aún se lo utiliza, no es el preferido por los ingenieros de software para sus desarrollos. Existen diversos puntos en contra que hacen que cada día se lo utilice menos y – además – se han desarrollado algunas extensiones, bajo el nombre modelo booleano extendido [64] [51], que tratan de mejorar algunos puntos débiles.
2. Modelo Vectorial
Este modelo fue planteado y desarrollado por Gerard Salton [49] y – originalmente – se implementó en un SRI llamado SMART. Aunque el modelo posee más de treinta años, actualmente se sigue utilizando debido a su buena performance en la recuperación de documentos.
Conceptualmente, este modelo utiliza una matriz documento–término que contiene el vocabulario de la colección de referencia y los documentos existentes. En la intersección de un término t y un documento d se almacena un valor numérico de importancia del término t en el documento d; tal valor representa su poder de discriminación. Así, cada documento puede ser visto como un vector que pertenece a un espacio n-dimensional, donde n es la cantidad de términos que componen el vocabulario de la colección. En teoría, los documentos que contengan términos similares estarán a muy poca distancia entre sí sobre tal espacio. De igual forma se trata a la consulta, es un documento más y se la mapea sobre el espacio de documentos. Luego, a partir de una consulta dada es posible devolver una lista de documentos ordenados por distancia (los más relevantes primero). Para calcular la semejanza entre el vector consulta y los vectores que representan los documentos se utilizan diferentes fórmulas de distancia, siendo la más común la del coseno.
Obsérvese el siguiente ejemplo donde se representa a un documento d y a una consulta c:
Documento: “La República Argentina ha sido nominada para la realización del X Congreso Americano de Epidemiología en Zonas de Desastre. El evento se realizará ...”
Consulta: “argentina congreso epidemiología”

3. Modelo probabilístico
Fue propuesto por Robertson y Spark-Jones [47] con el objetivo de representar el proceso de recuperación de información desde el punto de vista de las probabilidades. A partir de una expresión de consulta se puede dividir una colección de N documentos en cuatro subconjuntos distintos: REL conjunto de documentos relevantes, REC conjunto de documentos recuperados, RR conjunto de documentos relevantes recuperados y NN el conjunto de documentos no relevantes no recuperados.
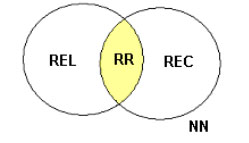
El resultado ideal de a una consulta se da cuando el conjunto REL es igual REC. Como resulta difícil lograrlo en primera intención, el usuario genera una descripción probabilística del conjunto REL y a través de sucesivas interacciones con el SRI se trata de mejorar la perfomance de recuperación. Dado que una recuperación no es inmediata dado que involucra varias interacciones con el usuario y que estudios han demostrado que su perfomance es inferior al modelo vectorial, su uso es bastante limitado.
4. Modelos para documentos estructurados
Los modelos clásicos responden a consultas, buscando sobre una estructura de datos que representa el contenido de los documentos de una colección, únicamente como listas de términos significativos. Un modelo de recuperación de documentos estructurados utiliza la estructura de los mismos a los efectos de mejorar la performance y brindar servicios alternativos al usuario (por ejemplo, uso de memoria visual, recuperación de elementos multimedia, mayor precisión sobre el ámbito de la consulta y demás).
La estructura de los documentos a indexar está dada por marcas o etiquetas, siendo los estándares más utilizados el SGML (Standard General Markup Language), el HTML (HyperText Markup Language), el XML (eXtensible Markup Language) y LATEX.
Al poseer la descripción de parte de la estructura de un documento es posible generar un grafo sobre el que se navegue y se respondan consultas de distinto tipo, por ejemplo:
–Por estructura: ¿Cuáles son las secciones del segundo capítulo?
–Por metadatos o campos: Documentos de “Editorial UNLu” editados en 1998
–Por contenido: Término “agua” en títulos de secciones
–Por elementos multimedia: Imágenes cercanas a párrafos que contengan Bush
Para Baeza-Yates existen dos modelos en esta categoría “nodos proximales” [37] y “listas no superpuestas” [8]. Ambos modelos se basan en almacenar las ocurrencias de los términos a indexar en estructuras de datos diferentes, según aparezcan en algún elemento de estructura (región) o en otro como capítulos, secciones, subsecciones y demás. En general, las regiones de una misma estructura de datos no poseen superposición, pero regiones en diferentes estructuras sí se pueden superponer.
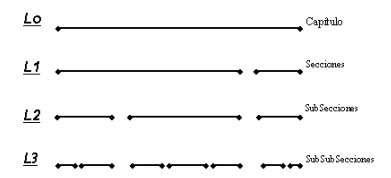
Nótese que en el ejemplo anterior existen cuatro niveles de listas para almacenar información relativa a contenido textual y estructura de un documento tipo libro. En general, los tipos de consultas soportados son simples:
· Seleccione una región que contenga una palabra dada
· Seleccione una región X que no que no contenga una región Y
· Seleccione una región contenida en otra región
Sobre el ejemplo de estructura planteado un ejemplo de consulta sería:
[subsección[+] CONTIENE “‘tambo” ]
Como respuesta el SRI buscaría subsecciones y sub-subsecciones que contengan el término “tambo“.
Cabe mencionar que algunos motores de búsqueda de Internet ya utilizan ciertos elementos de la estructura de un documento – por ejemplo, los títulos – a los efectos de realizar tareas de rankeo, resumen automático, clasificación y otras.
La expansión de estos lenguajes de demarcación, especialmente en servicios sobre Internet, hacen que se generen y publiquen cada vez más documentos semiestructurados. Es necesario – entonces – desarrollar técnicas que aprovechen el valor agregado de los nuevos documentos. Si bien – en la actualidad – éstas no se encuentran tan desarrolladas como los modelos tradicionales, consideramos su evolución como una cuestión importante en el área de RI, especialmente a partir de investigaciones con enfoques diferentes que abordan la problemática [18] [38] [45].
Referencias
[8] Burkowski, F. “Retrieval activities in a database consisting of heterogeneous collections of structured texts”. In Belkin, N., Ingwersen, P., Pejtersen, A. M., and Fox, E., editors, Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 112–125, New York. ACM Press. 1992.
[18] Egnor, D. y Lord, R. “Structured information retrieval using XML”. En: Proceedings of the ACM SIGIR 2000 Workshop on XML and Information Retrieval, Julio 2000.
[37] Navarro, G. y Baeza-Yates, R. “A language for queries on structure and contents of textual databases”. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, págs. 93-101, New York. ACM Press. 1995.
[38] Ogilvie, P. y Callan, J. “Language Models and Structured Document Retrieval”. En: Proceedings of the first INEX workshop, 2003.
[45] Raghavan, S. Y Garcia-Molina, H. “Integrating diverse information management systems: A brief survey”. IEEE Data Engineering Bulletin, 24(4):44-52, 2001.
[47] Robertson, S.E y Spark-Jones, K. “Relevance Weighting of Search terms”. Journal of Documentation. 33, p.126-148. 1976.
[49] Salton, G. (editor). “The SMART Retrieval System – Experiments in Automatic Document Processing”. Prentice Hall In. Englewood Cliffs, NJ. 1971.
[51] Salton, G.; Fox, E.A. y Wu, H. “Extended Boolean information retrieval”. Communications of the ACM, 26(11):1022-1036. Noviembre, 1983
[64] Waller, W. G. y Kraft, D. H. “A mathematical model for a weighted Boolean retrieval system”. Information Processing and Management, Vol 15, No. 5, pp. 235-245. 1979.
WikiSym 2006
WikiSym es un Simposio Internacional sobre Wikis donde se presentan investigaciones académicas y se discute en mesas redondas distintos aspectos de esta temática. El evento correspondiente al año 2006 se realizó Dinamarca con el aval de la asociación ACM. En este enlace pueden hallar las presentaciones correspondientes.
Walles y la razón de éxito de Wikipedia
En una entrevista para la revista Nature [Roxanne Khamsi, Wikipedia co-founder Jimmy Wales offers a whole new species of information online. ,BioEd Online] , Walles expresa que como experiencia previa a Wikipedia “... fundamos Nupedia, pero se tenía proceso de revisión extremadamente complicado, era un trabajo verticalista y muy académico, donde no se consideraba el aporte de voluntarios. Este modelo tradicional de alto control simplemente no funcionó. Luego nos enteramos del modelo colaborativo wiki, el cual era excelente. Cuando Wikipedia comenzó a funcionar se transformó rápidamente en un éxito. En dos semanas conseguimos hacer más trabajo que el que teníamos realizado en dos años...". Tras analizar los conceptos anteriores cabe preguntarse si la nueva enciclopedia Citizendium, la cual como característica principal presenta un modelo más rígido de control de los artículos, por parte de académicos, tendrá viabilidad ?.
domingo, noviembre 19, 2006
Ranking de penetración de Internet en América Latina
A partir de un informe sobre el estado de desarrollo de Internet el la región, presentado en la Conferencia de Naciones Unidas para el Comercio y el Desarrollo (UNCTAD), se observa que la república Argentina está en el tercer lugar en el ranking de penetración de Internet en América Latina. Los números indican que 17,7 argentinos de cada 100 se conectan a la red (la noticia indica que es una cifra superior al promedio mundial la cual es 15,6%). De los 17,7 sólo 2,2 argentinos lo hacen por banda ancha.
Sobre un total 89,13 millones de conexiones a Internet en total en Latino América y el Caribe se tiene el siguiente ranking.
1 Bermudas 65,4 usuarios cada 100 habitantes
2 Barbados 59,4 usuarios
3 Antigua y Barbuda 35,6 usuarios
4 Bahamas 31,9 usuarios
5 Dominica 32,9 usuarios
6 Martinica 32,8 usuarios,
7 Costa Rica 25,4 usuarios
8 Guayana 21,3 usuarios
9 Brasil 19,5 usuarios
10 Uruguay 19,3 usuarios
11 Argentina 17,7 usuarios
Creo que en Centro América y el Caribe la alta tasa se debe a la baja densidad de población sumado a la oferta de opciones turísticas destinadas a norteamericanos y europeos.
Las conexiones de Brasil y México suman el 60% de todas y un 25% la tienen Argentina, Chile, Colombia, Perú y Venezuela. Con respecto a desarrollo de tecnologías de conexión se sabe que en banda ancha Chile, tiene la mayor penetración 4,3 %, Argentina y México 2,2%, Brasil y Uruguay 1,8%, Venezuela 1,3%, Perú 1,2%, Colombia y República Dominicana 0,7%, El Salvador 0,6%, Panamá 0,5%, Ecuador y Nicaragua 0,2 % y Bolivia Paraguay 0,1%.
Fuente: Infobaeprofesional.com
Sobre un total 89,13 millones de conexiones a Internet en total en Latino América y el Caribe se tiene el siguiente ranking.
1 Bermudas 65,4 usuarios cada 100 habitantes
2 Barbados 59,4 usuarios
3 Antigua y Barbuda 35,6 usuarios
4 Bahamas 31,9 usuarios
5 Dominica 32,9 usuarios
6 Martinica 32,8 usuarios,
7 Costa Rica 25,4 usuarios
8 Guayana 21,3 usuarios
9 Brasil 19,5 usuarios
10 Uruguay 19,3 usuarios
11 Argentina 17,7 usuarios
Creo que en Centro América y el Caribe la alta tasa se debe a la baja densidad de población sumado a la oferta de opciones turísticas destinadas a norteamericanos y europeos.
Las conexiones de Brasil y México suman el 60% de todas y un 25% la tienen Argentina, Chile, Colombia, Perú y Venezuela. Con respecto a desarrollo de tecnologías de conexión se sabe que en banda ancha Chile, tiene la mayor penetración 4,3 %, Argentina y México 2,2%, Brasil y Uruguay 1,8%, Venezuela 1,3%, Perú 1,2%, Colombia y República Dominicana 0,7%, El Salvador 0,6%, Panamá 0,5%, Ecuador y Nicaragua 0,2 % y Bolivia Paraguay 0,1%.
Fuente: Infobaeprofesional.com
sábado, noviembre 18, 2006
Material de clase sobre Data Mining
Para todos aquellos que le interese profesionalmente o en su vida de estudiante este apasionante tema, les recomiendo consultar las notas de clase de los profesores Rajamaran y Ullman en Stanford. Hay buen material para indagar sobre posibles temas de tesinas y trabajos finales.
Sitio colaborativo sobre noticias relacionadas con la bibliotecología
Documenea es un portal basado en filtrado colaborativo y recomendaciones de enlaces que trata el dominio la documentación.
viernes, noviembre 17, 2006
Uso de Google, por parte de médicos, como fuente de consulta de su profesión
Un artículo de investigación titulado “Googling for a diagnosis--use of Google as a diagnostic aid: internet based study” de Hangwi Tang y Jennifer Hwee Kwoon es el resultado de una experiencia que tuvo por objetivo determinar cuánto podría servir la web como fuente de consulta de casos difíciles. En sus conclusiones se indica, textualmente, que “…the web is rapidly becoming an important clinical tool for doctors. The use of web based searching may help doctors to diagnose difficult cases…”
Trabajos en línea de la “Conferencia Semantic Web”
La semana pasada terminó la 5th International Semantic Web Conference, la cual se realizó en Athens, USA. En la página pueden hallar los papers que se presentaron en el encuentro.
jueves, noviembre 16, 2006
Proyecto social OpenStreetMap
Proyecto creado por Steve Coast en el año 2004 destinado a proveer de forma gratuita datos geográficos de todas partes del m undo, que utiliza un gestor wiki como organizador de contenidos. Debido a que en varios países distintas organizaciones cobran por la provisión de datos georeferenciados, un grupo de usuarios de tal información ha generado y mantenido este emprendimiento de carácter social. La comunidad OpenStreetMaps está creando mapas y habilitando el uso libre de los mismos; esto se logra debido a que algunos usuarios aportan datos, de su región geográfica, tomados con su GPS personal y otros se dedican a la edición (en línea o no) de mapas con herramientas y una metodología provista por la organización. Hoy la forma legal que tomo el proyecto para su administración y desarrollo es la de fundación sin fines de lucro.
miércoles, noviembre 15, 2006
La interacción del usuario con el Sistema de recuperación de Información (SRI)
Aquí sigo con la idea de presentar algunas partes del libro que he escrito con Gabriel Tolosa, titulado “Introducción a la Recuperación de Información”.
La tarea de recuperar información puede ser planteada de diversas formas, de acuerdo a cómo el usuario interactúa con el sistema o bien qué facilidades éste le brinda. Básicamente, la tarea se la puede dividir en:
1) Recuperación inmediata: El usuario plantea su necesidad de información y – a continuación – obtiene referencias a los documentos que el sistema evalúa como relevantes. Existen dos modalidades:
a) Búsqueda (propiamente dicha) o recuperación “ad-hoc”, donde el usuario formula una consulta en un lenguaje y el sistema la evalúa y responde. En este caso, el usuario tiene suficiente comprensión de su necesidad y sabe cómo expresar una consulta al sistema. Un ejemplo clásico son los buscadores de Internet como Google, Altavista o AllTheWeb.
b) Navegación o browsing: En este caso, el usuario utiliza un enfoque diferente al anterior. El sistema ofrece una interface con temas donde el usuario “navega” por dicha estructura y obtiene referencias a documentos a relacionados. Esto facilita la búsqueda a usuarios que no pueden definir claramente cómo comenzar con su consulta e – inclusive – van definiendo su necesidad a medida que observan diferentes documentos. Es este enfoque no se formula consulta explícita. Un ejemplo típico es el proyecto Open Directory.
En ambos casos, la colección es relativamente estática, es decir, se parte de un conjunto de documentos y la aparición de nuevos no es muy significativa. Por otro lado, las consultas son las que se van modificando ya que este proceso es proactivo por parte del usuario.
2) Recuperación diferida: El usuario especifica sus necesidades y el sistema entregará de forma continua los nuevos documentos que le lleguen y concuerden con ésta. Esta modalidad recibe el nombre de filtrado y ruteo y la necesidad del usuario – generalmente – define un “perfil” (profile) de los documentos buscados. Nótese que un “perfil” es – de alguna forma – un query y puede ser tratado como tal. Cada vez que un nuevo documento arriba al sistema se compara con el perfil y – si es relevante – se envía al usuario. Un ejemplo, es el servicio provisto por la empresa Indigo Stream Technologies denominado GoogleAlert.
En esta modalidad la consulta es relativamente estática (corresponde al profile) y el usuario tiene un rol pasivo. El dinamismo está dado por la aparición de nuevos documentos y es lo que determina mas resultados para el usuario.
En algunos casos, se plantea que documentos y consultas son objetos de la misma clase por lo que estos enfoques son – de alguna manera – visiones diferentes de una misma problemática. Bajo este punto de vista, documentos y consultas se pueden intercambiar. Sin embargo, esto no es siempre posible debido al tratamiento que se aplica a cada uno en diferentes sistemas. Algunos sistemas representan queries y documentos de diferente manera. Es más, existe una diferencia obvia en cuanto a la longitud de uno y otro que se tiene en cuenta bajo ciertos modelos de recuperación. Finalmente, en un sistema de búsqueda, existe el concepto de ranking de los documentos respuesta, mientras que en un modelo de filtrado, cada nuevo objeto es relevante a un perfil o no.
martes, noviembre 14, 2006
Según Netcraft, en el espacio web, existen alrededor de 100 millones de sitios
Una noticia de la CNN (aportada por Baquía) comenta que Internet alcanzó en el mes de octubre los 100 millones de sitios web (nótese que en el mes de setiembre se registraron 3.5 millones de nuevos sitios). Se verificó que ha doblado su tamaño desde mayo de 2005. El estudio indica que solo la mitad son web activas. Netcraft, empresa que realizó el estudio, aventuró a explicar este fenómeno, argumentando que los weblogs y los sitios web de pequeñas empresas y negocios son los principales contribuidores del número mencionado. Para Netcraft, los países donde se registró mayor crecimiento son USA, China, Alemania, Korea del Sur y Japón.
lunes, noviembre 13, 2006
Cómo son las busquedas de los investigadores en revistas electrónicas?
“Searching for electronic journal articles to support academic tasks” es el título de un artículo de investigación de Vakkari y Talja recientemente publicado. El estudio se focalizó sobre el uso de material en la Biblioteca Electrónica Nacional Finlandesa (FinELib). En la investigación se analiza cómo la jerarquía académica y el área de trabajo influencian las las estrategias de búsqueda utilizadas por el personal académico.
La principal conclusión indica que los patrones de búsqueda de artículos están cambiando debido a que hay un incremento en la disponibilidad de fuentes y posibilidades de acceso a material electrónico. Otros extractos interesantes son:
“Our results seem to confirm the findings (Tenopir et al. 2003) that in the electronic information environment, browsing journals is replaced by subject searching in databases. Searching both in full-text and reference databases was considered a considerably more important method of accessing journal literature than browsing journals.”
“There were some differences in search methods used for these tasks by academic status. First, younger researchers rely significantly more on keyword searching than senior researchers for finding journal articles for research purposes.”
Cita: Pertti Vakkari and Sanna Talja: “Searching for electronic journal articles to support academic tasks. A case study of the use of the Finnish National Electronic Library (FinELib)” in Information Research, Vol. 12 No. 1, October 2006.
domingo, noviembre 12, 2006
Para algunas universidades la enseñanza de la informática no sólo es cosmética
Estaba revisando mis canales RSS y me topé con una noticia (del canal CFI) la cual trata el tema de la promoción de desarrollo de software como estrategia para complementar la formación de alumnos de una carrera de informática.
El tema en cuestión viene de que la Universidad de Sevilla organizó un concurso de desarrollo de software libre y recibió casi 100 proyectos provenientes de grupos de alumnos de toda españa.
Como dicen ellos, y la tienen clara, "...este certamen tiene como objetivo involucrar a los estudiantes universitarios en la participación y creación de proyectos de software libre para que, de esta forma, se creen las condiciones idóneas para generar un tejido tecnológico de futuros profesionales capaces de dar soporte de soluciones basadas en software libre a empresas e instituciones...". Que buenos estos tíos, se dedican a enseñar y no a decir que enseñan o hacer cosmética educativa.
Que el ejemplo nos colonice.
El tema en cuestión viene de que la Universidad de Sevilla organizó un concurso de desarrollo de software libre y recibió casi 100 proyectos provenientes de grupos de alumnos de toda españa.
Como dicen ellos, y la tienen clara, "...este certamen tiene como objetivo involucrar a los estudiantes universitarios en la participación y creación de proyectos de software libre para que, de esta forma, se creen las condiciones idóneas para generar un tejido tecnológico de futuros profesionales capaces de dar soporte de soluciones basadas en software libre a empresas e instituciones...". Que buenos estos tíos, se dedican a enseñar y no a decir que enseñan o hacer cosmética educativa.
Que el ejemplo nos colonice.
Broder en una lecture en el MIT presentará el concepto de "information supply"
En el marco de las series "Shannon Lecture" el día 16 de noviembre Andrei Broder (Investigador principal de Yahoo) dará una confrerencia titulada "The next generation Web Search: From Information Retrieval to Information Supply". Según la página de Yahoo Labs y el documento de presentación de este evento, Broder explicará la evolución de information retrieval hacía una nueva era llamada information supply. Aquí se propone que si que el usuario realice explicitamente la consulta el sistema se de cuenta de su necesidad de información y le suministre información relevante proveniente de múltiples fuentes. A partir de sensar las actividades habituales de un usuario, el sistema decidirá cuándo, cómo, y de donde ayudarlo. Ilustra este concepto con el ejemplo de los ads en los buscadores o de la información suplementaria sobre recomendaciones en sitios de comercio electrónico.
sábado, noviembre 11, 2006
La ciencia que no se ve no existe
Este título es la frase que acompaña a la página principal del portal REDALYC (Red de Revistas Científicas de América Latina, el Caribe, España y Portugal). Este servicio, orientado a organizar la literatura científica y mejorar la visibilidad de autores de la región, ya indexa más de 42.000 artículos de cerca de 300 revistas especializadas.
Off Topic: De profesión Geek
Revisando las entradas de Microsiervos hallé una dedicada a definir que es un “geek” [http://www.microsiervos.com/archivo/internet/geek-y-nerd.html ] según el diccionario "Jargon File":
“Persona que ha elegido la concentración en vez de el conformismo; alguien que persigue la habilidad (especialmente la habilidad técnica) y la imaginación, en vez de la aceptación social de la mayoría. Los geeks habitualmente padecen una versión aguda de neofilia (sentirse atraidos, excitados y complacidos por cualquier cosa «nueva»). La mayor parte de los geeks son hábiles con los ordenadores y entienden la palabra hacker como un término de respeto, pero no todos ellos son hackers. De hecho algunos que son hackers de todas formas se llaman a sí mismos geeks porque consideran (y con toda la razón) que el término «hacker» debe ser una etiqueta que otras personas le pongan a uno, más que una etiqueta alguien se ponga a sí mismo. “
viernes, noviembre 10, 2006
Estudio sobre uso de sistemas P2P en Alemania
La empresa Ipoque ha presentado un estudio sobre tráfico P2P en Alemania entre abril-setiembre 2006. El informe detalla información acerca de protocolos utilizados, tráfico y tipo de contenidos intercambiados. Los archivos más populares son películas, música y juegos; pero los libros y los audio books han ganado terreno. La pornografía sigue teniendo una importante participación.
Sistemas P2P utilizan un 30% durante el día y un 70% por la noche de todo el tráfico que circula por Alemania, la distribución de los protocolos es la siguientes:

Bien por Gnutella vemos que aún esta vivo!!!
En el sistema BitTorrent la distribución por tipo de contenido intercambiado es la siguiente:

La distribución de tipos de descarga por tipo de contenido, según sea BitTorrent o Edonkey. es la siguiente
 Si hay alguien interesado en leer algo básico sobre sistemas compañero a compañero recomiendo este artículo que escribí, junto a Gabriel Tolosa, hace algunos años atrás y el cual fue publicado en Novática.
Si hay alguien interesado en leer algo básico sobre sistemas compañero a compañero recomiendo este artículo que escribí, junto a Gabriel Tolosa, hace algunos años atrás y el cual fue publicado en Novática.
Off topic: Mario Benedetti y sus ocurrencias
Ayer estaba releyendo el libro de Mario Benedetti "La tregua" el cual aborda temas relativos a la soledad, la vida impasible, el correr del tiempo y el como nos cerramos o encapsulamos; tomando como base una crítica a la "mediocre" clase media uruguaya de otra época. Encontré un párrafo bastante ingenioso, el cual me hizo matar de risa, ahí va:
"Volví a casa, dormí la siesta y me levanté pesado, de mal humor. Tomé unos mates y me fastidió que estuviera amargo. Entonces me vestí y me fui otra vez al Centro. Esta vez me metí en un café; conseguí una mesa junto a la ventana. En un lapso de una hora y cuarto, pasaron exactamente treinta y cinco mujeres de interés. Para entretenerme hice una estadística sobre qué me gustaba más en cada una de ellas. Lo apunté en la servilleta de papel. Este es el resultado. De dos, me gustó la cara; de cuatro, el pelo; de seis, el busto; de ocho, las piernas; de quince, el trasero. Amplia victoria de los traseros"
miércoles, noviembre 08, 2006
Lo que la WebDosBeta nos dejó
Hace algunos días, en España, finalizó el encuentro tecnológico "WebDosBeta" el cual trató sobre el movimiento llamado Web 2.0, especificamente en el ambiente hispano.
Gracias al blog habilitaron los organizadores hoy podemos acceder a algunas de las presentaciones que se ofrecieron:
Si alguién sabe algo acerca de podcasts de las charlas que avise.
Gracias al blog habilitaron los organizadores hoy podemos acceder a algunas de las presentaciones que se ofrecieron:
Si alguién sabe algo acerca de podcasts de las charlas que avise.
Recomendado: Paper sobre tags
Un trabajo de investigación sobre tags ha sido presentado por los laboratorios Yahoo Research. El trabajo de Dubinko y otros se titula “Visualizing Tags over Time” y fue presentado en la WWW´6.
Se estudió la evolución de etiquetas o tags en el sistema de registro de fotografías Flickr. El servicio es altamente utilizado, nótese que el último año, los usuarios en promedio agregaron un millón de etiquetas semanalmente. Presentan una herramienta de visualización, desarrollada a propósito, que permite ver la dinámica de los tags asociadas a fotos en una ventana de tiempo.
Cita: Micah Dubinko and Ravi Kumar and Joseph Magnani and Jasmine Novak and Prabhakar Raghavan and Andrew Tomkins. 2006. Visualizing Tags over Time. In WWW '06: Proceedings of the 15th international conference on World Wide Web (Edinburgh, Scotland). ACM Press. New York, NY, USA, 193--202.
Disponible en: http://www2006.org/programme/files/xhtml/25/fp25-dubinko-xhtml.html
martes, noviembre 07, 2006
Sifry y un nuevo informe del estado de la blogosfera
Como ya nos tiene acostumbrados Sifry, lider de Technorati, nos presenta un nuevo informe en el que detalla el estado actual de la blogosfera (espacio virtual donde residen los blogs).
A continuación traduzco el resumen de los hallazgos más importantes
· Technorati realiza el seguimiento de más de 57 millones de blogs.
· La blogosfera está duplicando su tamaño cada 230 días.
· Cerca de 100,000 nuevos blogs se crean diariamente.
· Cerca del 4% de los nuevos splogs (spam blogs) logran pasar los filtros de Technorati.
· Hay una fuerte relación entre la antigüedad y la frecuencia de los posts de un blog.
· Los datos muestran que el lenguaje español e inglés son más universales. En cambio los lenguajes asiáticas son locales o restringidos a su área geográfica de origen solamente.
Nuevos blogs entre marzo del 2003 y octubre del 2006. Se nota claramente que el fenómeno tiene una forma exponencial.

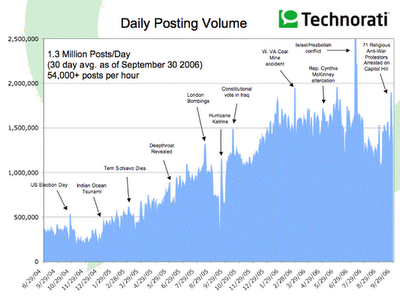
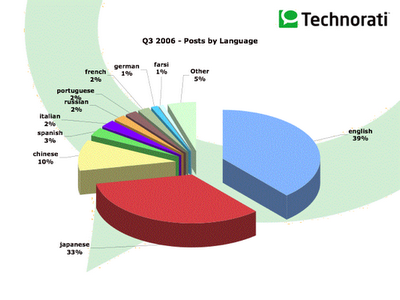
A continuación traduzco el resumen de los hallazgos más importantes
· Technorati realiza el seguimiento de más de 57 millones de blogs.
· La blogosfera está duplicando su tamaño cada 230 días.
· Cerca de 100,000 nuevos blogs se crean diariamente.
· Cerca del 4% de los nuevos splogs (spam blogs) logran pasar los filtros de Technorati.
· Hay una fuerte relación entre la antigüedad y la frecuencia de los posts de un blog.
· Los datos muestran que el lenguaje español e inglés son más universales. En cambio los lenguajes asiáticas son locales o restringidos a su área geográfica de origen solamente.
Nuevos blogs entre marzo del 2003 y octubre del 2006. Se nota claramente que el fenómeno tiene una forma exponencial.

Volumen diario de producción de artículos. Hoy se está en el orden de los 1.3 millones de nuevos artículos diarios.

Distribución de posts por lenguaje.
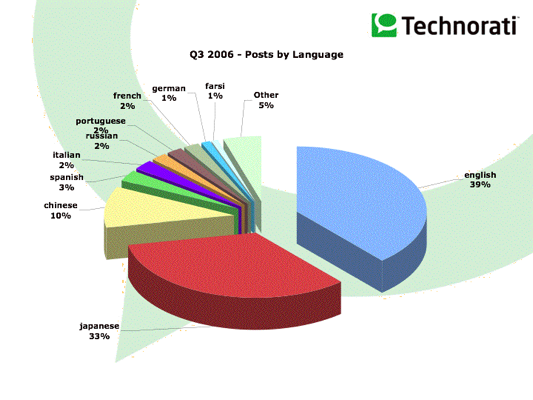
lunes, noviembre 06, 2006
Off topic: Feliz Cumpleaños Flavio
 Flavio es un amigo que está haciendo su Doctorado en Ciencias de la Computación en Nueva Zelandía. Mañana martes es su cumpleaños y quisimos hacerle un pequeño regalo, el cual consitió en brindar por su felicidad.
Flavio es un amigo que está haciendo su Doctorado en Ciencias de la Computación en Nueva Zelandía. Mañana martes es su cumpleaños y quisimos hacerle un pequeño regalo, el cual consitió en brindar por su felicidad.Disculpen, nada tiene que ver con IR o blogs o buscadores, pero este medio permite darle algunas alegrías a l0s que están lejos marcando ejemplo de conducta y vida académica.
Pd: Un beso grande a Lore!!!!
Off topic: Que grande que somos, pasamos del puesto 97 al 93
Si es una ironía, sino que otra cosa puede ser; y está en relación con que hoy la organización Transparencia Internacional publicó su "Índice de Percepción de la Corrupción 2006 ". Qué paso? mejoramos Cuánto? muy poco (casi nada) del puesto 97 los argentinos pasamos al 93 junto con Armenia, Bosnia & Herzegovina, Eritrea, Tanzania y Siria (que papita si fuera un grupo para el mundial de futbol siguiente, pero la realidad dice que no lo es).
Una percepción que tengo, la cual puede ser errónea pero hasta que no vea lo contrario la sostengo, es que como sociedad no nos damos cuenta que el problema de la corrupción es de todos y no solo de "esos llegados de Marte (con perdón de los marcianos) llamados clase política". La corrupción es parte de nuestra vida diaria, por ejemplo cuando nos pagan para hacer algo y no lo hacemos (léase ñoquis) o lo hacemos mal siendo concientes de esto, o cuando tratamos de "sobornar" a un empleado o funcionario (no comprendemos que como ciudadamos somos el socio-motor de este aparato) o cuando sabemos que tal o cual gerente de educación hace copy and paste y como corporación lo dejamos hacer "total es un buen chico (no le pega a la madre) y todos lo hacen". En definitiva creo que mientras como individuos, base de una sociedad, no tomemos conciencia que somos los potenciales motores de posibles actos de corrupción seguiremos flotando sobre tales posiciones del ranking.
Saludos y perdonen por el off topic, es solo catarsis.
Una percepción que tengo, la cual puede ser errónea pero hasta que no vea lo contrario la sostengo, es que como sociedad no nos damos cuenta que el problema de la corrupción es de todos y no solo de "esos llegados de Marte (con perdón de los marcianos) llamados clase política". La corrupción es parte de nuestra vida diaria, por ejemplo cuando nos pagan para hacer algo y no lo hacemos (léase ñoquis) o lo hacemos mal siendo concientes de esto, o cuando tratamos de "sobornar" a un empleado o funcionario (no comprendemos que como ciudadamos somos el socio-motor de este aparato) o cuando sabemos que tal o cual gerente de educación hace copy and paste y como corporación lo dejamos hacer "total es un buen chico (no le pega a la madre) y todos lo hacen". En definitiva creo que mientras como individuos, base de una sociedad, no tomemos conciencia que somos los potenciales motores de posibles actos de corrupción seguiremos flotando sobre tales posiciones del ranking.
Saludos y perdonen por el off topic, es solo catarsis.
domingo, noviembre 05, 2006
Afortunadamente, tenemos blogs. Podemos publicar lo que pensamos realmente, aún informando mal
Que título, donde queda la escuela de periodismo que allí voy (seguro que me reprueban por ser largo, bahhh). Pero la frase no es mía, es tomada del blog de Sir Tim Beners-Lee. Este señor, es aquel científico del CERN al cual a principios de los 90 se le ocurrió el concepto del espacio web tal como sigue vigente en esencia.
En estos tiempos que corren, Tim ha presentado una propuesta tendiente a generar un ámbito de estudios académicos sobre la red. El MIT (Instituto de Tecnología de Massachussetts) y la Universidad inglesa de Southampton, comienzan un programa conjunto de desarrollo de investigaciones aplicadas a Internet. La iniciativa de Berners-Lee pretende concentrar una amplia variedad de investigadores trabajando sobre una carrera de grado que forme personas que estudien Internet desde el campo tecnológico hasta sus implicaciones sociales. Hay un primer paper donde junto a otros investigadores fundamenta el por qué de este emprendimiento, en el cual explica que "...Web Science is required both as a way to understand the Web, and as a way to focus its development on key communicational and representational requirements. The text surveys central engineering issues, such as the development of the Semantic Web, Web services and P2P. Analytic approaches to discover the Web’s topology, or its graph-like structures, are examined. Finally, the Web as a technology is essentially socially embedded..."
Desde su perspectiva, los cambios generados en la sociedad por Internet son sólo el inicio de una transformación aún más profunda, la cual tiene implicaciones ingenieriles como sociales. Un concepto, el cual atrae la atención, es que para Berner Lee “...un crecimiento sin controles de la red podría traer malas consecuencias...”. Apuntando a esto indicó que la privacidad y el gerenciamiento de datos personales son puntos críticos sobre los cuales se deben realizar estudios y análisis [según reportaje de la BBC que a Tim no le gustó mucho lo que se terminó escibiendo, de allí la ironía que hay en el titular de este post].
En una entrevista realizada por "elmundo.es" (febrero 2005) Tim se refiere al tema de Internet y las libertades individuales de la siguiente forma "...La gran amenaza es que los Gobiernos controlen a la población rastreando su navegación por Internet para saber qué hacemos, con quien hablamos y qué pensamos. De esta forma, y con la excusa de buscar terroristas, consiguen muchísima información. El poder tiene mecanismos muy potentes, incluso para hacer trampas en el recuento de unas elecciones, y por eso tiene que haber otros organismos vigilantes. Estoy muy preocupado por los abusos de los derechos individuales....". En el mismo reportaje habló que si en algún momento tuviera un blog contaría su opinión acerca de Bush y la guerra, estoy esperando ansiosamente este post.
Hay una parte del blog de Tim donde habla acerca de la calidad de los materiales en la web. Me gustó su simpleza y claridad "... The way quality works on the web is through links. It works because reputable writers make links to things they consider reputable sources. So readers, when they find something distasteful or unreliable, don't just hit the back button once, they hit it twice. They remember not to follow links again through the page which took them there. One's chosen starting page, and a nurtured set of bookmarks, are the entrance points, then, to a selected subweb of information which one is generally inclined to trust and find valuable..."
Saludos
En estos tiempos que corren, Tim ha presentado una propuesta tendiente a generar un ámbito de estudios académicos sobre la red. El MIT (Instituto de Tecnología de Massachussetts) y la Universidad inglesa de Southampton, comienzan un programa conjunto de desarrollo de investigaciones aplicadas a Internet. La iniciativa de Berners-Lee pretende concentrar una amplia variedad de investigadores trabajando sobre una carrera de grado que forme personas que estudien Internet desde el campo tecnológico hasta sus implicaciones sociales. Hay un primer paper donde junto a otros investigadores fundamenta el por qué de este emprendimiento, en el cual explica que "...Web Science is required both as a way to understand the Web, and as a way to focus its development on key communicational and representational requirements. The text surveys central engineering issues, such as the development of the Semantic Web, Web services and P2P. Analytic approaches to discover the Web’s topology, or its graph-like structures, are examined. Finally, the Web as a technology is essentially socially embedded..."
Desde su perspectiva, los cambios generados en la sociedad por Internet son sólo el inicio de una transformación aún más profunda, la cual tiene implicaciones ingenieriles como sociales. Un concepto, el cual atrae la atención, es que para Berner Lee “...un crecimiento sin controles de la red podría traer malas consecuencias...”. Apuntando a esto indicó que la privacidad y el gerenciamiento de datos personales son puntos críticos sobre los cuales se deben realizar estudios y análisis [según reportaje de la BBC que a Tim no le gustó mucho lo que se terminó escibiendo, de allí la ironía que hay en el titular de este post].
En una entrevista realizada por "elmundo.es" (febrero 2005) Tim se refiere al tema de Internet y las libertades individuales de la siguiente forma "...La gran amenaza es que los Gobiernos controlen a la población rastreando su navegación por Internet para saber qué hacemos, con quien hablamos y qué pensamos. De esta forma, y con la excusa de buscar terroristas, consiguen muchísima información. El poder tiene mecanismos muy potentes, incluso para hacer trampas en el recuento de unas elecciones, y por eso tiene que haber otros organismos vigilantes. Estoy muy preocupado por los abusos de los derechos individuales....". En el mismo reportaje habló que si en algún momento tuviera un blog contaría su opinión acerca de Bush y la guerra, estoy esperando ansiosamente este post.
Hay una parte del blog de Tim donde habla acerca de la calidad de los materiales en la web. Me gustó su simpleza y claridad "... The way quality works on the web is through links. It works because reputable writers make links to things they consider reputable sources. So readers, when they find something distasteful or unreliable, don't just hit the back button once, they hit it twice. They remember not to follow links again through the page which took them there. One's chosen starting page, and a nurtured set of bookmarks, are the entrance points, then, to a selected subweb of information which one is generally inclined to trust and find valuable..."
Saludos
sábado, noviembre 04, 2006
Muhammad Yunus y su visión humanista de la tecnología
Muhammad Yunus es el actual Premio Nobel de la Paz 2006. El cual ha sido otrogado basicamente en función de sus ideas sobre el desarrollo de comunidades en estado de pobreza. Yunus también conocido como el ‘banquero de los pobres’ alla por los 70, en
Bangladesh, creó un Banco que otorgaba micro-créditos para que todos pueden pagar.
De la práctica descubrió que las mujeres eran buenas pagadoras, y que el préstamo a una mujer beneficiaba de mejor forma asu entorno familiar. Su porcentaje de morosidad es bajísimo y nada tiene que ver con el de los bancos convencionales. Su último trabajo en el área fue el establecimiento de un banco de mendigos, el cual presta dinero a indigentes, con la finalidad que puedan comprar pequeñas cosas para lugo revender. Hoy, Yunus es multimillonario y sus bancos son de los primeros en Asia y sigue con más fuerza que nunca aplicando sus ideas capaitalistas a ayudar que la gente salga de la indigencia y pobreza por sus propios medios.
Me sorprendieron algunas declaraciones de este gran hombre, relacionadas con la tecnología de las comunicaciones, las cuales copio a continuación y son parte de una entrevista que le hiciera Marcela Aguilar y publicada en la Revista de El Mercurio.
"...El nuevo milenio nos ha traído la inédita posibilidad para cada ser humano de descubrir su propio potencial y una oportunidad de cambiar su vida. Esto es verdad sin importar donde uno viva. La tecnología de la información y las comunicaciones está creando las condiciones para un mundo sin distancias y contribuyendo a que la economía se expanda a gran velocidad. Pese a que ofrece la gran posibilidad de combatir la pobreza, este potencial permanecerá inexplorado si lo dejamos a arbitrio de las fuerzas del mercado. Ellas ayudarán primero a los países ricos a volverse más ricos, a los grandes negocios a hacerse más grandes, y ellos a su vez guiarán la industria hacia sus propias metas...
..."No tiene por qué ser así. Existen poderosas personas y organizaciones en el mundo fuertemente comprometidas con el fin de la pobreza. Ellas pueden orientar la industria hacia las necesidades de la gente pobre. La tecnología puede jugar un papel inmediato en terminar con la pobreza, integrando a los pobres en el proceso de globalización, expandiendo su mercado a través del comercio electrónico, eliminando los mediadores en los negocios, creando oportunidades de trabajo internacionales a través del outsourcing, brindando educación, conocimiento y entrenamiento de habilidades de un modo amigable, y brindando servicios en salud"...
Que visión clara tiene !!!
Bangladesh, creó un Banco que otorgaba micro-créditos para que todos pueden pagar.
De la práctica descubrió que las mujeres eran buenas pagadoras, y que el préstamo a una mujer beneficiaba de mejor forma asu entorno familiar. Su porcentaje de morosidad es bajísimo y nada tiene que ver con el de los bancos convencionales. Su último trabajo en el área fue el establecimiento de un banco de mendigos, el cual presta dinero a indigentes, con la finalidad que puedan comprar pequeñas cosas para lugo revender. Hoy, Yunus es multimillonario y sus bancos son de los primeros en Asia y sigue con más fuerza que nunca aplicando sus ideas capaitalistas a ayudar que la gente salga de la indigencia y pobreza por sus propios medios.
Me sorprendieron algunas declaraciones de este gran hombre, relacionadas con la tecnología de las comunicaciones, las cuales copio a continuación y son parte de una entrevista que le hiciera Marcela Aguilar y publicada en la Revista de El Mercurio.
"...El nuevo milenio nos ha traído la inédita posibilidad para cada ser humano de descubrir su propio potencial y una oportunidad de cambiar su vida. Esto es verdad sin importar donde uno viva. La tecnología de la información y las comunicaciones está creando las condiciones para un mundo sin distancias y contribuyendo a que la economía se expanda a gran velocidad. Pese a que ofrece la gran posibilidad de combatir la pobreza, este potencial permanecerá inexplorado si lo dejamos a arbitrio de las fuerzas del mercado. Ellas ayudarán primero a los países ricos a volverse más ricos, a los grandes negocios a hacerse más grandes, y ellos a su vez guiarán la industria hacia sus propias metas...
..."No tiene por qué ser así. Existen poderosas personas y organizaciones en el mundo fuertemente comprometidas con el fin de la pobreza. Ellas pueden orientar la industria hacia las necesidades de la gente pobre. La tecnología puede jugar un papel inmediato en terminar con la pobreza, integrando a los pobres en el proceso de globalización, expandiendo su mercado a través del comercio electrónico, eliminando los mediadores en los negocios, creando oportunidades de trabajo internacionales a través del outsourcing, brindando educación, conocimiento y entrenamiento de habilidades de un modo amigable, y brindando servicios en salud"...
Que visión clara tiene !!!
viernes, noviembre 03, 2006
En el año 2004 nacía Digg
Digg es un portal de noticias que tiene la característica de tener un ranking armado por los propios usuarios a partir de un sistema de votación democrático, sin jerarquías. Su orientación es tecnológica. Los usuarios envían sus textos -cortos- y otros pares votan (promocionan o digg) por ellos, si una noticia alcanza un umbral de votos, entonces se promueve a la página principal. Por otro lado, como en los blogs, otros usuarios pueden agregar comentarios a las noticias. En una entrevista, realizada a inicios del 2006, a uno de sus creadores se plantearon los siguientes números que ilustran su dinámica "Los miembros de Digg actualmente son 140.00 y la cantidad se dobla cada tres meses. 500.000 visitantes únicos vienen al sitio Digg todos los días, una cifra que está creciendo por 100.000 cada mes. Nuevos contenidos son enviados al sitio en un promedio de 1.000 - 1.500 historia/contenidos por día."
En el año 2004, en el programa de TV "The Screen Savers", Kevin Rose (uno de sus creadores) anunció que en la red se acababa de inagurar un sitio donde la comunidad de telespectadores podía votar acerca de que noticias le interesaban. Desde la concepción de Rose la intención fue que la propia gente defina cual es la agenda informativa, esto se logró dándle poder de voto. El software que permitio gerenciar los votos se llamó Digg y en julio del año 2006 ya tenía cerca de 400.000 usuarios registrados. Para el español Menéame es un sitio que ofrece un servicio basado en Digg.
En el año 2004, en el programa de TV "The Screen Savers", Kevin Rose (uno de sus creadores) anunció que en la red se acababa de inagurar un sitio donde la comunidad de telespectadores podía votar acerca de que noticias le interesaban. Desde la concepción de Rose la intención fue que la propia gente defina cual es la agenda informativa, esto se logró dándle poder de voto. El software que permitio gerenciar los votos se llamó Digg y en julio del año 2006 ya tenía cerca de 400.000 usuarios registrados. Para el español Menéame es un sitio que ofrece un servicio basado en Digg.
jueves, noviembre 02, 2006
Librerías Clairlib para recuperación de información
El grupo de Lingüística Computacional y Recuperación de Información de la Universidad de Michigan, CLAIR (Computational Linguistics And Information Retrieval) group ha desarrollado unas librerías de information retrieval llamadas Clair.
El soft está desarrollado en lenguaje perl y tiene por objetivo asistir a los investigadores de IR y PNL. La oferta de módulos es la siguiente:
Desarrollos propios: Tokenization, Summarization, LexRank, Biased LexRank, Document Clustering, Document Indexing, PageRank, Biased Pagerank, Web Graph Analysis, Bioinformatics Text Analysis, Political Science Text Analysis, Network Building, Power Law Distribution Analysis, Network Analysis and Computation (Watts-Strogatz Clustering Coefficient, Cosines, Random Walks), Tf, Idf
Importado (como soft CPAN): Stemming, Sentence Segmentation, Web Page Download, Web Crawling, XML Parsing, XML Tree Building, XML Writing
Gracias Ojo Buscador
El soft está desarrollado en lenguaje perl y tiene por objetivo asistir a los investigadores de IR y PNL. La oferta de módulos es la siguiente:
Desarrollos propios: Tokenization, Summarization, LexRank, Biased LexRank, Document Clustering, Document Indexing, PageRank, Biased Pagerank, Web Graph Analysis, Bioinformatics Text Analysis, Political Science Text Analysis, Network Building, Power Law Distribution Analysis, Network Analysis and Computation (Watts-Strogatz Clustering Coefficient, Cosines, Random Walks), Tf, Idf
Importado (como soft CPAN): Stemming, Sentence Segmentation, Web Page Download, Web Crawling, XML Parsing, XML Tree Building, XML Writing
Gracias Ojo Buscador
miércoles, noviembre 01, 2006
JSWEB2006
El 16 y 17 de noviembre en Santiago de Compostela se realizará la segunda edición de las Jornadas Científico-Técnicas en Servicios Web - JSWEB 2006.Es un ámbito donde se busca establecer un punto de referencia para profesionales, empresas e investigadores interesados en el uso y la adopción de la plataforma de servicios Web y de las arquitecturas orientadas a servicio (SOA) en el entorno académico o industrial.
Las jornadas tienen como objetivo estrechar los lazos entre el mundo de la industria y el entorno universitario, acercando los resultados de la investigación a las empresas y creando un marco de colaboración que facilite la transferencia de tecnología, conocimiento y experiencias prácticas.
Las Jornadas están por tanto dirigidas, pero no limitadas, a grupos tales como:
· profesionales, consultores y analistas dedicados a/o que estén considerando el desarrollo o la implantación de aplicaciones software basadas en servicios Web y arquitecturas SOA.
· grupos de investigación en las áreas de servicios Web, arquitecturas orientadas a servicios, middleware o servicios Grid, que desean mostrar los avances realizados en esta área.
· grupos de investigación científica que utilicen infraestructura informática basada en servicios Grid, servicios Web o arquitecturas orientadas a servicios.
Los trabajos presentados en la edición del año 2005 se hallan en esta página
Las jornadas tienen como objetivo estrechar los lazos entre el mundo de la industria y el entorno universitario, acercando los resultados de la investigación a las empresas y creando un marco de colaboración que facilite la transferencia de tecnología, conocimiento y experiencias prácticas.
Las Jornadas están por tanto dirigidas, pero no limitadas, a grupos tales como:
· profesionales, consultores y analistas dedicados a/o que estén considerando el desarrollo o la implantación de aplicaciones software basadas en servicios Web y arquitecturas SOA.
· grupos de investigación en las áreas de servicios Web, arquitecturas orientadas a servicios, middleware o servicios Grid, que desean mostrar los avances realizados en esta área.
· grupos de investigación científica que utilicen infraestructura informática basada en servicios Grid, servicios Web o arquitecturas orientadas a servicios.
Los trabajos presentados en la edición del año 2005 se hallan en esta página
Suscribirse a:
Comentarios (Atom)
