Continuando con la idea de presentar algunas partes del libro que he escrito con Gabriel Tolosa, titulado “Introducción a la Recuperación de Información”, ahora nos vamos a dedicar tratar las diferencias existentes entre recuperación de datos y recuperación de información.
Muchos usuarios se encuentran familiarizados con el concepto de recuperación de datos (RD), especialmente aquellos que – a menudo – interactúan con sistemas de consulta en bases de datos relacionales ó en registros de alguna naturaleza, como por ejemplo, un registro de los empleados de una organización. Sin embargo, hay diferencias significativas en los conceptos que definen que el tratamiento de las unidades (datos o información) en cada caso sean completamente diferentes.
Básicamente, existen diferencias sustanciales en cuanto a los objetos con que se trata y su representación, la especificación de las consultas y los resultados.
En el área de RD los objetos que se tratan son estructuras de datos conocidas. Su representación se basa en un formato previo definido y con un significado implícito (hay una sintaxis y semántica no ambigua) para cada elemento. Por ejemplo, una tabla en una base de datos que almacena instancias de clientes de una organización posee un conjunto de columnas que definen los atributos de todos los clientes y cada fila corresponde a uno en particular. Nótese que cada elemento (atributo) tiene un dominio conocido y su semántica está claramente establecida. Por otro lado, en el área de recuperación de información (RI) la unidad u objeto de tratamiento es básicamente un documento de texto – en general – sin estructura.
En cuanto a la especificación de las consultas, en el área de RD se cuenta con una estructura bien definida dada por un lenguaje de consulta que permite su especificación de manera exacta. Las consultas no son ambiguas y consisten en un conjunto de condiciones que deben cumplir los ítems a evaluar para que la misma se satisfaga. Por ejemplo, en el modelo de bases de datos, las consultas especifican – entre otros – utilizando el lenguaje SQL (Structured Query Language) cuya semántica es precisa:
SQL // En lenguaje natural _
SELECT * // Seleccionar todos los clientes de
FROM Clientes // Chivilcoy que deban más de 10000 pesos
WHERE Localidad = “Chivilcoy” // (se sabe, por definición, que lo que deben
AND Saldo_Cuenta > 10000 // es su saldo de cuenta)
En este ejemplo, se puede ver la clara semántica de la consulta en SQL a partir de que se conoce que existe un atributo Localidad y otro Saldo_Cuenta y lo que cada uno representa. Sin embargo, esto no es tan directo ni tan simple cuando se trata de recuperar documentos en el contexto de la RI. En primer lugar, debido a que la necesidad de un usuario puede ser difícil de expresar. Por ejemplo, supóngase que se desea encontrar:
“Documentos que contengan información biográfica de los entrenadores de los equipos de fútbol de Argentina que ganaron más torneos en los últimos 10 años”
La primera dificultad consiste en construir una expresión de consulta que refleje exactamente esta necesidad de información del usuario. Especialmente, si se tiene en cuenta que para resolverla completamente quizá primero se requiera de conocer información parcial, por ejemplo, “ganaron más torneos en los últimos 10 años”. ¿Qué significa “ganaron más torneos”? Esta es una situación subjetiva y – en muchos casos – el sistema debe manejar estas cuestiones, junto con ambigüedades (por ejemplo, palabras cuyo significado está determinado por el contexto) e incompletitud de la mejor manera posible. De hecho, los documentos y las expresiones de consulta se interpretan de forma que el proceso de recuperación determine un grado de similitud entre éstos.
Finalmente, en un sistema de RD los resultados consisten en el conjunto completo de elementos que satisfacen todas las condiciones del query. Como la consulta no admite errores, el resultado es exacto, ni uno más, ni uno menos. Y el orden de aparición es simplemente casual (a menos que específicamente se desee ordenar por alguna columna), pero en todos los casos este orden es irrelevante respecto de la consulta y no significa nada, es decir, no se puede implementar sistema de rankeo alguno. En el área de RI, aparece el concepto de relevancia y la salida (respuesta) se encuentra confeccionada de acuerdo a algún criterio que evalúa la “similitud” que existe entre la consulta y cada documento. Por lo tanto, el resultado es un ranking (que no es sinónimo de “orden”, tal como se lo entiende habitualmente en RD), donde la primera posición corresponde al documento más relevante a la consulta y así decrece sucesivamente. El proceso de recuperación de información puede retornar documentos que no sean relevantes para el usuario, es decir, que el conjunto de respuesta no es exacto.
A continuación, se resumen las diferencias más significativas entre un SRI y un sistema de RD como lo es un Sistema de Gestión de Bases de Datos (SGBD).
SGBD
Estructura: Información estructurada con semántica bien definida.
Recuperación: Determinística. Todo el conjunto solución es relevante para el usuario
Consulta y Lenguaje: Especificación precisa (no hay ambigüedad). Lenguaje formal, preciso y estructurado.
Resultados: Aciertos exactos
SRI
Estructura: Información semi o no estructurada.
Recuperación: Probabilística. Una porción de los documentos recuperados puede no ser relevante.
Consulta y Lenguaje: Hay imprecisión en su formulación. Lenguaje natural, ambiguo y no estructurado.
Resultados: Aciertos parciales
Otros autores también establecieron las diferencias entre ambos conceptos: Grossman y otro [Grossman] claramente muestran la diferencia cuando enuncian que “la recuperación de información es encontrar documentos relevantes, no encontrar simples correspondencias a unos patrones de bits”. Nótese la diferencia sustancial que existe en tratar de encontrar documentos “relevantes” a una consulta o – simplemente – encontrar aquellos donde “coinciden” patrones de términos o se cumplen ciertas condiciones. En el caso de la RD, la tarea es relativamente sencilla, mientras que en área de RI es extremadamente compleja y no existe aún una solución definitiva al problema.
[Grossman] Grossman, D. y Frieder, O. “Information Retrieval. Algorithms and Heuristics”. Kluwer Academic Publishers. 1998.
viernes, septiembre 29, 2006
jueves, septiembre 28, 2006
Off topic: En una democracia no hay lugar para desapariciones
Quiero publicar esta triste noticia de mi país Argentina. El señor Julio Jorge López fue testigo en el juicio al represor Miguel Etchecolatz (ya juzgado y condenado), desde hace varios días está desaparecido y es buscado en todo el país.
Creo que esta no es una noticia más, es un hecho en si que una democracia no puede tolerar, si alguien conce al señor de la foto por favor comuníquese con la policía.

Creo que esta no es una noticia más, es un hecho en si que una democracia no puede tolerar, si alguien conce al señor de la foto por favor comuníquese con la policía.

miércoles, septiembre 27, 2006
Honestidad académica
CLEF 2006 -Cross Language Evaluation Forum
Ha finalizado el evento CLEF 2006, el cual fue realizado en Alicante (España). En la página del programa del evento hay algunas presentaciones.
Congreso Internacional: Oportunidades en la Sociedad de la Informació
La gente de Infoxicacion está haciendo la promoción del IV Congreso Internacional: Oportunidades en la Sociedad de la Información. El evento lo organiza la Universidad de Costa Rica y se realizará entre el 8-10 de noviembre del 2006.
Cronología de los servicios de búsqueda (1945-2006)
Un artículo del blog Search Marketing titulado "History of Search Engines: From 1945 to Google 2006" presenta una breve cronología sobre el desarrollo de los motores de consulta.
Directorio de software relacionado con la recuperación de información
Karpanta
Motor de recuperación de información experimental desarrollado por el Grupo Reina (Universidad de Salamanca).
Okapi
Software de indexación de colecciones de documentos.
Bow
Es una herramienta, diseñada por Andrew McCallum's, destinada a ayudar al estudio de modelos de lenguaje, recuperación de información, clasificación y agrupamiento de documentos. Se distribuye en código fuente bajo licencia GNU. h
TnT
Etiquetador léxico que corre sobre plataformas Solaris y Linux.
Editor XML
jEdit: es un editor de archivos en formato XML de licencia libre. Oisee plugins para sopòrtar extensiones del lenguaje.
CLUTO
Paquete orientado a tareas de análisis de conglomerados (clustering). Corre en plataformas Linux, Sun y Windows 2000.
NLTK
Clasificador que incorpora diversos métodos (Naive Bayes, MaxEnt, etc). t
Orange
Software de minería de datos desarrollado en C++. Incluye técnicas de SVM, análisis de conglomerados, regresión logística, etc.
WebSPHINX
Web crawler de uso moderado.
Balie
Herramienta destinada a la extracción de información.
SWISH-E
Motor de consulta.
XML Query Engine
Motor de consulta que indexa documentos en formato XML. h
ht://Dig
Motor de consulta de uso popular.
Snowball
Herramienta para desarrollo de stemmers.
Weka
Software de soporte a la minería de datos. Desarrollado en java.
MG
Managing Gigabytes, software de recuperación de información.
Lucene
Motor de consulta freeware, codificado en Java.
Motor de recuperación de información experimental desarrollado por el Grupo Reina (Universidad de Salamanca).
Okapi
Software de indexación de colecciones de documentos.
Bow
Es una herramienta, diseñada por Andrew McCallum's, destinada a ayudar al estudio de modelos de lenguaje, recuperación de información, clasificación y agrupamiento de documentos. Se distribuye en código fuente bajo licencia GNU. h
TnT
Etiquetador léxico que corre sobre plataformas Solaris y Linux.
Editor XML
jEdit: es un editor de archivos en formato XML de licencia libre. Oisee plugins para sopòrtar extensiones del lenguaje.
CLUTO
Paquete orientado a tareas de análisis de conglomerados (clustering). Corre en plataformas Linux, Sun y Windows 2000.
NLTK
Clasificador que incorpora diversos métodos (Naive Bayes, MaxEnt, etc). t
Orange
Software de minería de datos desarrollado en C++. Incluye técnicas de SVM, análisis de conglomerados, regresión logística, etc.
WebSPHINX
Web crawler de uso moderado.
Balie
Herramienta destinada a la extracción de información.
SWISH-E
Motor de consulta.
XML Query Engine
Motor de consulta que indexa documentos en formato XML. h
ht://Dig
Motor de consulta de uso popular.
Snowball
Herramienta para desarrollo de stemmers.
Weka
Software de soporte a la minería de datos. Desarrollado en java.
MG
Managing Gigabytes, software de recuperación de información.
Lucene
Motor de consulta freeware, codificado en Java.
martes, septiembre 26, 2006
Sexual and pornographic web searching: trend analysis
La Doctora Amanda Spink, reconocida investigadora sobre conductas de usuarios frente a un motor de búsqueda, ha presentado un nuevo trabajo de investigación titulado “Sexual and pornographic web searching: trend analysis”. Desde el título el trabajo es seductor, pero más allá de las bromas el estudio trata de medir la intensidad de las búsquedas pornográficas o sexuales en motores de consulta desde el año 1997 al año 2005. Como dato relevante derivado de la investigación se concluye que tal intensidad ha disminuido y que actualmente representan un porcentaje menor al 4%.
lunes, septiembre 25, 2006
Revista de Ciencias de la Información
La Facultad de Letras y Ciencias Humanas de la Pontificia Universidad Católica del Perú, edita Alexandrí@ la cual es la Revista Electrónica de Ciencias de la Información. En ella se presentan artículos relacionados con la bibliotecología y la sociedad del conocimiento.
Telos: Cuadernos de comunicación, tecnología y sociedad
Les quería recomendar una revista electrónica llamada TELOS que en el número actual se trata exclusivamente el tema de los weblogs. Les copio el índice:
Un tutorial sobre blogs. El abecé del universo blog, Antonio Fumero
El poder tecnológico de los infociudadanos. Diarios y conversaciones en la Red Universal Digital, Fernando Sáez Vacas
Blogs vs. MSM.Periodismo 3.0, la socialización de la información, Juan Varela
Blogs y empresa. Una aproximación a la vanguardia de la blogosfera corporativa, Enrique Dans
Blogs para educar.Usos de los blogs en una pedagogía constructivista, Tíscar Lara
El blog en la literatura.Un acercamiento estructural a la blogonovela, Hernán Casciari
El papel de los blogs en la acción social.Blogs en ONG, una oportunidad poco conocida, Olga Berrios
Métrica de la blogosfera.Algunas medidas y relaciones en la blogosfera hispana, Juan Julián Merelo y Fernando Tricas
Anatomía de los blogs.La jerarquía de lo visible, Adolfo Estalella
Un tutorial sobre blogs. El abecé del universo blog, Antonio Fumero
El poder tecnológico de los infociudadanos. Diarios y conversaciones en la Red Universal Digital, Fernando Sáez Vacas
Blogs vs. MSM.Periodismo 3.0, la socialización de la información, Juan Varela
Blogs y empresa. Una aproximación a la vanguardia de la blogosfera corporativa, Enrique Dans
Blogs para educar.Usos de los blogs en una pedagogía constructivista, Tíscar Lara
El blog en la literatura.Un acercamiento estructural a la blogonovela, Hernán Casciari
El papel de los blogs en la acción social.Blogs en ONG, una oportunidad poco conocida, Olga Berrios
Métrica de la blogosfera.Algunas medidas y relaciones en la blogosfera hispana, Juan Julián Merelo y Fernando Tricas
Anatomía de los blogs.La jerarquía de lo visible, Adolfo Estalella
domingo, septiembre 24, 2006
Recuperación de información en la década de 1940 “La máquina Memex”
Memex (Memory Extender System) fue una máquina teórica desarrollada por Vannevar Bush en el año 1945, su objetivo era almacenar y recuperar información de forma análoga a la memoria humana. El invento en cuestión fue publicado en la revista Atlantic Monthly bajo el título Monthly “As We May Think” en el año 1945. En tal artículo, Bush conciente de la proliferación del fenómeno conocido como “saturación de información” propone una máquina personal que asista a los individuos en una forma similar a la de nuestra memoria, es decir trabajando por asociación de conceptos.
En las palabras de su autor Memex era "...una máquina conceptual capaz de almacenar amplias cantidades de información, en la que los usuarios tienen la posibilidad de crear información, pistas o senderos de información, enlaces a textos relacionados e ilustraciones, datos que pueden ser almacenados y utilizados en futuras referencias.." y por otro lado “... en Memex una persona guarda sus libros, archivos y comunicaciones, dotado de mecanismos que permiten la consulta con gran rapidez y flexibilidad. Es un accesorio íntimo y ampliado de la memoria..."
La máquina de Bush almacenaría información de todo tipo (libros, documentos, transcripciones, anotaciones personales, etc) en una suerte de microfilms, los cuale se agregan en orden cronológico. Se asocian entre si a partir de vínculos o enlaces (trails) que se comportarían de forma semejante a la memoria de los humanos dado que se crean cuando se incorpora nueva información al sistema. La recuperación también estaba basada en asociación, dado que a partir de un concepto se recuperaban aquellas porciones de información (documentos en la forma tradicional) relacionadas con el mismo.
Dado el poco desarrollo de la informática en el momento de su invención, como así también la pobre oferta en dispositivos de almacenamiento y periféricos, hicieron que la máquina sea imposible de implementarse y quede como un prometedor diseño. A la fecha, Bush es reconocido como uno de los precursores del concepto de lectura no lineal, es decir la basada en hipertexto.
Vannevar Bush. “As We May Think”. The Atlantic Monthly, Vol. 176, No. 1, 101-108, july 1945
En las palabras de su autor Memex era "...una máquina conceptual capaz de almacenar amplias cantidades de información, en la que los usuarios tienen la posibilidad de crear información, pistas o senderos de información, enlaces a textos relacionados e ilustraciones, datos que pueden ser almacenados y utilizados en futuras referencias.." y por otro lado “... en Memex una persona guarda sus libros, archivos y comunicaciones, dotado de mecanismos que permiten la consulta con gran rapidez y flexibilidad. Es un accesorio íntimo y ampliado de la memoria..."
La máquina de Bush almacenaría información de todo tipo (libros, documentos, transcripciones, anotaciones personales, etc) en una suerte de microfilms, los cuale se agregan en orden cronológico. Se asocian entre si a partir de vínculos o enlaces (trails) que se comportarían de forma semejante a la memoria de los humanos dado que se crean cuando se incorpora nueva información al sistema. La recuperación también estaba basada en asociación, dado que a partir de un concepto se recuperaban aquellas porciones de información (documentos en la forma tradicional) relacionadas con el mismo.
Dado el poco desarrollo de la informática en el momento de su invención, como así también la pobre oferta en dispositivos de almacenamiento y periféricos, hicieron que la máquina sea imposible de implementarse y quede como un prometedor diseño. A la fecha, Bush es reconocido como uno de los precursores del concepto de lectura no lineal, es decir la basada en hipertexto.
Vannevar Bush. “As We May Think”. The Atlantic Monthly, Vol. 176, No. 1, 101-108, july 1945
sábado, septiembre 23, 2006
Off Topic: Cuento Tecnológico
Gracias a mi compañero Javier por hacerme reir y reflexionar un rato. Comparto con ustedes un pequeño cuento popular que trata sobre tecnología:
Algunas veces es un error juzgar el valor de una actividad simplemente por el tiempo que toma realizarla...
Un buen ejemplo es el caso del ingeniero que fue llamado a arreglar una computadora muy grande y extremadamente compleja... una computadora que valía 12 millones de dólares. Sentado frente a la pantalla, oprimió unas cuantas teclas, asintió con la cabeza, murmuró algo para sí mismo y apagó el aparato.
Procedió a sacar un pequeño destornillador de su bolsillo y dio vuelta y media a un minúsculo tornillo. Entonces encendió de nuevo la computadora y comprobó que estaba trabajando perfectamente.
El presidente de la compañía se mostró encantado y se ofreció a pagar la cuenta en el acto. ¿Cuánto le debo? -preguntó. Son mil dólares, si me hace el favor.
¿Mil dólares? ¿Mil dólares por unos momentos de trabajo? ¿Mil dólares por apretar un simple tornillito?
¡Ya sé que mi computadora cuesta 12 millones de dólares , pero mil dólares es una cantidad disparatada! La pagaré sólo si me manda una factura perfectamente detallada que la justifique. El ingeniero asintió con la cabeza y se fue.
A la mañana siguiente, el presidente recibió la factura, la leyó con cuidado, sacudió la cabeza procedió a pagarla en el acto, sin chistar. La factura decía:
Servicios prestados:
Apretar un tornillo................. 1 dólar
Saber qué tornillo apretar.......... 999 dólares
Este cuento se dedica a aquellos profesionales que día a día se enfrentan con la desconsideración de quienes por su propia ignorancia no alcanzan a entenderlos y regálales al menos un momento de humor.
Moraleja "En ciertas profesiones u oficios se gana por lo que se sabe, no por lo que se hace".
Algunas veces es un error juzgar el valor de una actividad simplemente por el tiempo que toma realizarla...
Un buen ejemplo es el caso del ingeniero que fue llamado a arreglar una computadora muy grande y extremadamente compleja... una computadora que valía 12 millones de dólares. Sentado frente a la pantalla, oprimió unas cuantas teclas, asintió con la cabeza, murmuró algo para sí mismo y apagó el aparato.
Procedió a sacar un pequeño destornillador de su bolsillo y dio vuelta y media a un minúsculo tornillo. Entonces encendió de nuevo la computadora y comprobó que estaba trabajando perfectamente.
El presidente de la compañía se mostró encantado y se ofreció a pagar la cuenta en el acto. ¿Cuánto le debo? -preguntó. Son mil dólares, si me hace el favor.
¿Mil dólares? ¿Mil dólares por unos momentos de trabajo? ¿Mil dólares por apretar un simple tornillito?
¡Ya sé que mi computadora cuesta 12 millones de dólares , pero mil dólares es una cantidad disparatada! La pagaré sólo si me manda una factura perfectamente detallada que la justifique. El ingeniero asintió con la cabeza y se fue.
A la mañana siguiente, el presidente recibió la factura, la leyó con cuidado, sacudió la cabeza procedió a pagarla en el acto, sin chistar. La factura decía:
Servicios prestados:
Apretar un tornillo................. 1 dólar
Saber qué tornillo apretar.......... 999 dólares
Este cuento se dedica a aquellos profesionales que día a día se enfrentan con la desconsideración de quienes por su propia ignorancia no alcanzan a entenderlos y regálales al menos un momento de humor.
Moraleja "En ciertas profesiones u oficios se gana por lo que se sabe, no por lo que se hace".
Discos rígidos de 2,5 TB de capacidad en el 2009
Seagate ha anunciado la finalización del desarrollo de una nueva tecnología con la que se ha logrado almacenar hasta 421 Gb por pulgada cuadrada. EL efecto de este desarrollo se dará en que será posible tener discos rígidos de 2,5 TB (esto se espera que suceda en el 2009). Gracias Abadía Digital.
viernes, septiembre 22, 2006
Second International Workshop on Open Source Information Retrieval
El evento Open Source Information Retrieval Workshop, realizado en el marco del SIGIR, tiene por finalidad ser un facilitador de la difusion de tecnologías open source en recuperación de información. Todavía no están publicadas las presentaciones, hay que estar alerta a ello.
Pero por otro lado, si están publicadas las ponencias del OSWIR 2005 (2005 workshop on Open Source Web Information Retrieval).
Pero por otro lado, si están publicadas las ponencias del OSWIR 2005 (2005 workshop on Open Source Web Information Retrieval).
Google Blogsearch
Es un servicio ofrecido por Google que tiene la particularidad de buscar solamente en sitios weblogs. Dado el dinamismo de este tipo de sitios, Blogsearch permite sindicar las consultas, ya sea por los primeros 10 o 100 resultados. Es interesante el filtro por antigüedad de los artículos.
jueves, septiembre 21, 2006
Algunas críticas al sistema de noticias votadas “Menéame”
Menéame es una especia de diario digital o top ranking de noticias, las cuales son propuestas y votadas por los usuarios del sitio. Una noticia cuanto más votos tenga estará más cerca de los primeros lugares y por ende tendrán mayor visibilidad.
En definitiva se puede decir que es la gente común la que arma su diario, proponiendo en forma democrática los temas más representativos de la comunidad. Como alternativa a los medios tradicionales, donde no siempre representan el verdadero interés de la gente a partir de su abanico de información que presentan diariamente, estos sistemas sociales deberían ajustarse de mejor forma al imaginario colectivo. Pero parece que no siempre es así, en el blog Cuarzo Mundo se presenta un post con una serie de críticas a Menéame.
Si son fallas verdaderas hay que ajustar el servicio y la convivencia. Los sistemas sociales de votos de noticias son una oportunidad que posee la gente común de autodefinir su agenda diaria informativa.
En definitiva se puede decir que es la gente común la que arma su diario, proponiendo en forma democrática los temas más representativos de la comunidad. Como alternativa a los medios tradicionales, donde no siempre representan el verdadero interés de la gente a partir de su abanico de información que presentan diariamente, estos sistemas sociales deberían ajustarse de mejor forma al imaginario colectivo. Pero parece que no siempre es así, en el blog Cuarzo Mundo se presenta un post con una serie de críticas a Menéame.
Si son fallas verdaderas hay que ajustar el servicio y la convivencia. Los sistemas sociales de votos de noticias son una oportunidad que posee la gente común de autodefinir su agenda diaria informativa.
miércoles, septiembre 20, 2006
Modelo de ranking de blogs en español
Top Blog es un sitio dedicado a mantener un ranking de weblogs en español. Según consta en las FAQ del sitio “la puntuación de cada blog, que es la que determina la clasificación en el ranking, es la suma ponderada de los resultados de consultas sobre el blog a diversos motores de búsqueda, normalizada sobre un valor máximo”. Los buscadores y sus correspondientes pesos son:
Technorati = 1.5
Google.es = 1
Google Blog = 0.5
Google PR = 1.5
Alexa = 0.25
Yahoo.es = 0.25
Technorati = 1.5
Google.es = 1
Google Blog = 0.5
Google PR = 1.5
Alexa = 0.25
Yahoo.es = 0.25
En pocos día Google presentará en sociedad su procesador de textos colaborativo Writely
A partir de tener una cuenta en Writely, hoy me ha llegado un mail avisándome que en pocos días deberé utilizar mis datos de usuario Google para acceder al mencionado recurso. Esto significa dos cosas: a) que Writely ha pasado las pruebas con éxito y que b) ya estamos muy cercanos a que Google nos presente su WebOS. Adelante muchachos.
martes, septiembre 19, 2006
Plataforma tecnológica de publicación del diario El Mundo.es
Mauro, un colaborador de nuestro laboratorio, me ha hecho llegar la referencia a un interesante artículo escrito por el responsable técnico del diario español El Mundo, En el documento se relatan los seis años de experiencia de publicar la versión en línea del mencionado diario. Lo particular del relato se centra en que contra la corriente, este grupo de trabajo dirigido por Raúl Rivero, ha logrado éxito a partir de decir no al outsourcing y al decir si al software libre.
En particular, para la gente de informática recomiendo la lectura del artículo, no tiene desperdicio el ver como con un poco de ingenio y voluntad se pueden realizar buenos proyectos independientes.
En particular, para la gente de informática recomiendo la lectura del artículo, no tiene desperdicio el ver como con un poco de ingenio y voluntad se pueden realizar buenos proyectos independientes.
Estado del mercado de buscadores
Hitwise ha publicado el estado del mercado de los buscadores ,con datos de agosto 2006, en Estados Unidos. También se ha publicado la lista de los 25 sitios top en USA. Es interesante ver como Yahoo se va posicionando en estos últimos tiempos.
lunes, septiembre 18, 2006
Guía del Lenguaje Perl - 2da parte
Arreglos en Perl
Arreglos Indexados
En Perl los arreglos son listas de datos sin importar su tipo, es decir que puede estar compuestos por enteros flotantes, cadenas, o incluso otros arreglos, cada elemento es considerado como una variable independiente. El carácter $ se utiliza para referirse a un elemento en particular y el carácter @ para todos. El primer elemento de un arreglo es el indicado con 0 (cero).
$arreglo[$i+2] = 3; # Instancia el elemento $i+2 con el valor 3.
@arreglo = ( 1, 3, 5 ); # Inicializa el arreglo llamado arreglo
@arreglo = ( ); # Inicializa un arreglo vacío.
@foo = @bar; # copia el arreglo.
@foo = @bar[$i..$i+5]; # copia una parte del arreglo.
$numero = $#arreglo; # el numero se almacena el valor de índice más alto
# definido. Es decir la cantidad de elementos del arreglo-1


Arreglos n-dimensionales
En la siguiente instrucción se define un arreglo de 4 filas por 3 columnas -recordar que en Perl un arreglo comienza con el índice numérico 0-
@arreglo = ( [1, 2, 3], [4, -5, 6], [7, 8, 9], [10, 11, 12]);
print $arreglo[3][1]."\n"; # Imprime 11
Un arreglo no es más que una lista donde un elemento n puede ser a su vez otro arreglo, por lo tanto no es necesario que todas las filas tengan la misma longitud.
@m1 = ( 1 , "maria" );
@m2 = ( "pablo", "guillermo", "silvina" );
@m3 = ( "rosa", "agustin" , 3 );
@m = ( [@m1], [@m2], [@m3] );
print $m[2][1]."\n"; # Imprime agustin
Para determinar la cantidad de filas y columnas se utiliza:
print $#arreglo."\n"; # Brinda la cantidad de filas-1 del arreglo
print $#{$arreglo[1]}."\n"; # Brinda la cantidad de elementos-1 de la fila 1
Ejemplo: Programa que imprime un arreglo bidimensional.
@arreglo = ( [1, 2, 3], [4, -5, 6], [7, 8, 9, 99, 999], [10, 11, 12]);
for($i=0; $i<=$#arreglo; $i++) {
for($j=0; $j<=$#{$arreglo[$i]}; $j++) {print $arreglo[$i][$j]."\t"};
print "\n";
}
Un arreglo de tres dimensiones puede definirse de la siguiente manera
@arreglo = ( [[1,2,3], [4,5,6], [7,8,9] ],
[["a","b","c"],["d","e","f"], ["g","h","i"] ],
[[-1,-2,-3], [-4,-5,-6], [-7,-8,-9] ]
);
print $arreglo[0][1][2]."\n"; # Imrpime 6
print $arreglo[2][2][1]."\n"; # Imprime -8
Arreglos Indexados
En Perl los arreglos son listas de datos sin importar su tipo, es decir que puede estar compuestos por enteros flotantes, cadenas, o incluso otros arreglos, cada elemento es considerado como una variable independiente. El carácter $ se utiliza para referirse a un elemento en particular y el carácter @ para todos. El primer elemento de un arreglo es el indicado con 0 (cero).
$arreglo[$i+2] = 3; # Instancia el elemento $i+2 con el valor 3.
@arreglo = ( 1, 3, 5 ); # Inicializa el arreglo llamado arreglo
@arreglo = ( ); # Inicializa un arreglo vacío.
@foo = @bar; # copia el arreglo.
@foo = @bar[$i..$i+5]; # copia una parte del arreglo.
$numero = $#arreglo; # el numero se almacena el valor de índice más alto
# definido. Es decir la cantidad de elementos del arreglo-1


Arreglos n-dimensionales
En la siguiente instrucción se define un arreglo de 4 filas por 3 columnas -recordar que en Perl un arreglo comienza con el índice numérico 0-
@arreglo = ( [1, 2, 3], [4, -5, 6], [7, 8, 9], [10, 11, 12]);
print $arreglo[3][1]."\n"; # Imprime 11
Un arreglo no es más que una lista donde un elemento n puede ser a su vez otro arreglo, por lo tanto no es necesario que todas las filas tengan la misma longitud.
@m1 = ( 1 , "maria" );
@m2 = ( "pablo", "guillermo", "silvina" );
@m3 = ( "rosa", "agustin" , 3 );
@m = ( [@m1], [@m2], [@m3] );
print $m[2][1]."\n"; # Imprime agustin
Para determinar la cantidad de filas y columnas se utiliza:
print $#arreglo."\n"; # Brinda la cantidad de filas-1 del arreglo
print $#{$arreglo[1]}."\n"; # Brinda la cantidad de elementos-1 de la fila 1
Ejemplo: Programa que imprime un arreglo bidimensional.
@arreglo = ( [1, 2, 3], [4, -5, 6], [7, 8, 9, 99, 999], [10, 11, 12]);
for($i=0; $i<=$#arreglo; $i++) {
for($j=0; $j<=$#{$arreglo[$i]}; $j++) {print $arreglo[$i][$j]."\t"};
print "\n";
}
Un arreglo de tres dimensiones puede definirse de la siguiente manera
@arreglo = ( [[1,2,3], [4,5,6], [7,8,9] ],
[["a","b","c"],["d","e","f"], ["g","h","i"] ],
[[-1,-2,-3], [-4,-5,-6], [-7,-8,-9] ]
);
print $arreglo[0][1][2]."\n"; # Imrpime 6
print $arreglo[2][2][1]."\n"; # Imprime -8
Democracia y la web 2.0
Les presento un trabajo de investigación de José María Moreno Jiménez y otros titulado “e-cognocracia: democracia web 2.0”. Según sus autores, en él mismo se presentan los elementos básicos que definen un nuevo modelo democrático conocido como e-cognocracía. El cual es sería el resultado de la evolución de la humanidad y tiene por característica la utilización de Internet como soporte de comunicaciones y la democracia como elemento catalizador de la búsqueda del conocimiento. Moreno Jiménez indica que “...en e-cognicracía se persigue la creación y difusión social a través de la red del conocimiento relativo a la resolución científica de los problemas complejos planteados en el ámbito de las decisiones públicas relativas al gobierno de la sociedad”.
domingo, septiembre 17, 2006
Artículo de reflexión sobre Wikipedia
En el medio “The New Yorker” Stacy Schiff ha publicado un artículo titulado “Can Wikipedia
conquer expertise?”. Schiff expone una serie de argumentos a favor de la enciclopedia Wikipedia, donde los párrafos más significativos son los siguientes:
Al no tener límites físicos la Wikipedia puede aspirar a incluir mucha información (ya sea puntos de vista o diferentes opiniones, imágenes, audios, videos, escritos, etc.) sobre cualquier tema. También por esta razón puede tratar cualquier tema, inclusivo los considerados triviales o muy específicos por parte de otras publicaciones del mismo tipo.
Wikipedia es una organización sin fines de lucro, con solo 5 empleados pagos y una presupuesto anual de 750.000 dólares (recaudados de donaciones). La mayoría de su personal no cobre sueldo, su retribución es prestigio social y sentirse bien
ayudando a terceros.
La calidad de cada artículo está en función de una guardia celosa de internautas, que de alguna forma ejerce presión sobre los editores y contribuidores. Esto se logra al haber múltiples vías de contacto y retroalimentación.
Existen instancias de mediación a los efectos de resolver de forma civilizada los posibles conflictos que se planteen.
Wikipedia otorga a cualquier ciudadano del planeta la oportunidad de auto expresarse
Aparte, desde mi perspectiva, quiero agregar los siguientes puntos:
Se ha expandido a más de 200 idiomas. En general sitios como Alexa y Google sitúan a las páginas Wikipedia en los primeros lugares de sus listas de salida y de popularidad.
Actualmente privilegia los contenidos correctos, la amplia participación de opiniones, la lucha contra el vandalismo y la ortografía sobre la incorporación de nuevos artículos.
conquer expertise?”. Schiff expone una serie de argumentos a favor de la enciclopedia Wikipedia, donde los párrafos más significativos son los siguientes:
Al no tener límites físicos la Wikipedia puede aspirar a incluir mucha información (ya sea puntos de vista o diferentes opiniones, imágenes, audios, videos, escritos, etc.) sobre cualquier tema. También por esta razón puede tratar cualquier tema, inclusivo los considerados triviales o muy específicos por parte de otras publicaciones del mismo tipo.
Wikipedia es una organización sin fines de lucro, con solo 5 empleados pagos y una presupuesto anual de 750.000 dólares (recaudados de donaciones). La mayoría de su personal no cobre sueldo, su retribución es prestigio social y sentirse bien
ayudando a terceros.
La calidad de cada artículo está en función de una guardia celosa de internautas, que de alguna forma ejerce presión sobre los editores y contribuidores. Esto se logra al haber múltiples vías de contacto y retroalimentación.
Existen instancias de mediación a los efectos de resolver de forma civilizada los posibles conflictos que se planteen.
Wikipedia otorga a cualquier ciudadano del planeta la oportunidad de auto expresarse
Aparte, desde mi perspectiva, quiero agregar los siguientes puntos:
Se ha expandido a más de 200 idiomas. En general sitios como Alexa y Google sitúan a las páginas Wikipedia en los primeros lugares de sus listas de salida y de popularidad.
Actualmente privilegia los contenidos correctos, la amplia participación de opiniones, la lucha contra el vandalismo y la ortografía sobre la incorporación de nuevos artículos.
sábado, septiembre 16, 2006
GeoRSS
He visto que OjoBuscador ha informado la aparición de una nueva extensión (GeoRSS, versión 1) para RSS y ATOM (normas de sindicación de contenidos) , la cual permite agregar a cada etiqueta - una latitud y longitud que determina un punto geográfico (también e es posible indicar líneas y polígonos).
En el sitio GeoRSS se halla el protocolo completo de definición de regiones geográficas. En la página http://www.georss.org/implementations.html se presentan algunas aplicaciones que hacen uso de estos metadatos.
En el sitio GeoRSS se halla el protocolo completo de definición de regiones geográficas. En la página http://www.georss.org/implementations.html se presentan algunas aplicaciones que hacen uso de estos metadatos.
viernes, septiembre 15, 2006
Nuestros funcionarios y el analfabetismo tecnológico
Con gran preocupación he leído en el diario Clarín (Argentina) del 15/9/6 una nota titulada "Solá se mostró ´preocupado´ por la definición que apareció en Wikipedia sobre ´La Noche de los Lápices´". En ella la Defensora del Pueblo la Dra Alicia Pierini declara que iniciará "acciones legales contra los responsables de la Wikipedia" por "no controlar contenidos" en lo referente a la entrada de la mencionada enciclopedia bajo el título "la noche de los lápices".
Demás esta decir que el contenido en discusión (no el que ahora está publicado) no refleja en nada la realidad de la historia argentina, sino más bien el imaginario de algunos provocadores sociales pertenecientes a viejas tribus.
Reflexionando creo que el titular debería haber sido "Argentina emprenderá una acción legal planetaria contra millones de ciudadanos del planeta por tener aspiraciones sociales y participar a favor de la generación y preservación de espacios públicos de conocimiento". Quizás es un poco largo pero vendería, -bahhh tengo un 2 en la asignatura titulares I-.
En particular la Dra Pierini debería tener asesores que entiendan en que mundo estamos y hacía donde vamos. No es necesario que tales asesores sean pagos, hay organizaciones de usuarios, de profesionales, universidades que con muy buen criterio pueden ayudar a nuestros representantes a entender el significado de ciertas cosas.
Demás esta decir que el contenido en discusión (no el que ahora está publicado) no refleja en nada la realidad de la historia argentina, sino más bien el imaginario de algunos provocadores sociales pertenecientes a viejas tribus.
Reflexionando creo que el titular debería haber sido "Argentina emprenderá una acción legal planetaria contra millones de ciudadanos del planeta por tener aspiraciones sociales y participar a favor de la generación y preservación de espacios públicos de conocimiento". Quizás es un poco largo pero vendería, -bahhh tengo un 2 en la asignatura titulares I-.
En particular la Dra Pierini debería tener asesores que entiendan en que mundo estamos y hacía donde vamos. No es necesario que tales asesores sean pagos, hay organizaciones de usuarios, de profesionales, universidades que con muy buen criterio pueden ayudar a nuestros representantes a entender el significado de ciertas cosas.
La web argentina
En nuestro Laboratorio de Redes de la UNLu estamos finalizando un trabajo de investigación, de carácter exploratorio, que tiende a caracterizar el espacio web argentino. Siguiendo la metodología propuesta por Ricardo Baeza Yates y Carlos Castillo analizamos alrededor de 10 millones de páginas web de casi 150.000 sitios del dominio “.ar”.
Como un adelanto, mostramos a continuación en un mapa la distribución mundial de servidores (de los cuales descargamos más de 100 páginas) que hospedan sitios con dominios “.ar”. Para geocodificar utilizamos GeoIP City de la empresa MaxMind.

Como un adelanto, mostramos a continuación en un mapa la distribución mundial de servidores (de los cuales descargamos más de 100 páginas) que hospedan sitios con dominios “.ar”. Para geocodificar utilizamos GeoIP City de la empresa MaxMind.

WikiCharts — Top 100 — 9/2006
En la Wikipedia existe una página que muestra los artículos más vistos durante el mes en curso. Al 14 de setiembre el ranking estaba así:
1. Main Page
2. Steve Irwin
3. September 11, 2001 attacks
4. Stingray
5. Wikipedia
6. Wiki
7. List of sex positions
8. Naruto
9. List of big-bust models and performers
10. Lonelygirl15
1. Main Page
2. Steve Irwin
3. September 11, 2001 attacks
4. Stingray
5. Wikipedia
6. Wiki
7. List of sex positions
8. Naruto
9. List of big-bust models and performers
10. Lonelygirl15
Amanecer y anochecer de un día agitado en Google
Hay un gráfico (gif animado) generado por Google, que muestra con puntos blancos de distinta intensidad como varía a lo largo del día el tráfico generado por los usuarios que consultan al buscador. Al iluminarse una zona geográfica se indica un importante flujo de datos.
jueves, septiembre 14, 2006
Primer Congreso Puertorriqueño de Blogs Educativos
Mario Nuñez, en su blog, nos comunica que se celebrará el Primer Congreso Puertorriqueño de Blogs Educativos en febrero del año 2007. Se reciben ontribuciones hasta el 15 de diciembre. Los temas a abordar en el evento mencionado son los siguientes:
-Los blogs y las bibliotecas
-Efectividad de los adiestramientos para crear y manejar blogs
-Los blogs y el periodismo ciudadano
-Los blogs como estrategia docente
-Alfabetismo digital y blogs
-Blogs y literatura
-Los blogs como recursos para las artes y las ciencias
-Los blogs de estudiantes
-Los blogs como herramientas de activismo político
-Los blogs y las artes
-Blogs y portafolios electrónico
Más datos en:
http://www.vidadigital.net/blog/2006/09/12/convocatoria-primer-congreso-puertorrriqueo-de-blogs-educativos/
-Los blogs y las bibliotecas
-Efectividad de los adiestramientos para crear y manejar blogs
-Los blogs y el periodismo ciudadano
-Los blogs como estrategia docente
-Alfabetismo digital y blogs
-Blogs y literatura
-Los blogs como recursos para las artes y las ciencias
-Los blogs de estudiantes
-Los blogs como herramientas de activismo político
-Los blogs y las artes
-Blogs y portafolios electrónico
Más datos en:
http://www.vidadigital.net/blog/2006/09/12/convocatoria-primer-congreso-puertorrriqueo-de-blogs-educativos/
miércoles, septiembre 13, 2006
Libros en modalidad Open Source al servicio del desarrollo de las naciones
Fernando, un compañero del laboratorio, me acaba de alcanzar un artículo titulado "Open source textbooks to educate developing nations".Es un proyecto del profesor Rick Watson de la Universidad de Georgia Business que tiene por finalidad generar recursos educativos de acceso libre para el desarrollo educativo de naciones en desarrollo. El modelo de trabajo seleccionado es similar al de la exitosa Wikipedia, donde Watson explica que todas las entradas serán supervisadas por académicos a los efectos de dar seriedad y credibilidad al proyecto.
martes, septiembre 12, 2006
Splogs, basura en la blogósfera
Splog significa spam en weblogs y hace referencia a aquellos webblogs creados unicamente con la intención de promocionar servicios o productos de forma indebida. A fin del año 2005 Baquia publicó una entrada en la cual hacía referencia a que 1 de cada 5 blogs es un splog, un dato bastante sorprendente.
Ahora, en una nueva entrada en Baquia se indica que 56% de los blogs ingleses son spam.
Como argumento de eolución del fenómeno se cita que "...el problema es que realizar splog sale tan barato como rentable: se trata de mezclar sistemas automatizados de recopilación de información con otros de publicación. Lógicamente, en las posiciones más destacadas del blog se muestran anuncios contextuales y de redes de afiliación, por lo que para el internauta es tarea ardua identificar si ve un anuncio o la información que quiere..." "... Esto permite a los spammers llenarlas de comentarios que enlazan hacia sus propios sitios... Y ahí ya no hay moderadores que filtren los mensajes. Estos tipos saben que estar bien colocados en Google, Yahoo y MSN implica ganar miles de dólares al mes; usan cientos de páginas que se entrelazan aumentando su popularidad en los buscadores y miles de comentarios en otros sitios que apuntan hacia sus webs...."
Ahora, en una nueva entrada en Baquia se indica que 56% de los blogs ingleses son spam.
Como argumento de eolución del fenómeno se cita que "...el problema es que realizar splog sale tan barato como rentable: se trata de mezclar sistemas automatizados de recopilación de información con otros de publicación. Lógicamente, en las posiciones más destacadas del blog se muestran anuncios contextuales y de redes de afiliación, por lo que para el internauta es tarea ardua identificar si ve un anuncio o la información que quiere..." "... Esto permite a los spammers llenarlas de comentarios que enlazan hacia sus propios sitios... Y ahí ya no hay moderadores que filtren los mensajes. Estos tipos saben que estar bien colocados en Google, Yahoo y MSN implica ganar miles de dólares al mes; usan cientos de páginas que se entrelazan aumentando su popularidad en los buscadores y miles de comentarios en otros sitios que apuntan hacia sus webs...."
Sphere motor de consulta que indexa weblogs
Más allá del buen servicio prestado por Technorati existen otros motores de consulta que indexan el contenido de weblogs y además pueden manejar de forma adecuada su particular estructura. Tal es el caso de Sphere un servicio que especificamente indexa el contenido de blogs.
Como característica particular se puede consultar entre periodos de tiempo y dejar tales queries almnacenadas en el servidor, de forma tal que nuevos resultados nos lleguen vía canales RSS (está opción me parece que se ha implementado con bastante ingenio). Las listas de salida se geenran en base a los los enlaces entrantes y salientes, metadatos y el contenido de los documentos. En el sitio del servicio sxisten una serie de herramientas para integrar Sphere a los prinicpales exploradores.
Mi impresión es que su base de datos aún es bastante reducida pero la interface y los resultados provistos en las pruebas de uso me dejaron -inicialmente- conforme.
Como característica particular se puede consultar entre periodos de tiempo y dejar tales queries almnacenadas en el servidor, de forma tal que nuevos resultados nos lleguen vía canales RSS (está opción me parece que se ha implementado con bastante ingenio). Las listas de salida se geenran en base a los los enlaces entrantes y salientes, metadatos y el contenido de los documentos. En el sitio del servicio sxisten una serie de herramientas para integrar Sphere a los prinicpales exploradores.
Mi impresión es que su base de datos aún es bastante reducida pero la interface y los resultados provistos en las pruebas de uso me dejaron -inicialmente- conforme.
lunes, septiembre 11, 2006
Tutorial del proyecto Lemur
Lemur es un software de IR que permite indexar colecciones y estudiar modelos de lenguaje por una importante variedad de técnicas. Se ejecuta en plataformas con Microsoft Windows o en Linux.
En el toolkit Lemur es posible trabajar con herramientas para: resúmenes automáticos, recuperación distribuida, filtrado y clasificación. El software incluye una API para personalizar interfaces de usuario.
A partir de un tutorial, por parte de los autores de Lemur, en el evento SIGIR 2006 tenemos unas interesantes slides que introducen al toolkit.
En algún lado tengo algunos tips que indican como utilizar Lemur rápidamente, espero encontrarlos para poder compartirlos con ustedes.
En el toolkit Lemur es posible trabajar con herramientas para: resúmenes automáticos, recuperación distribuida, filtrado y clasificación. El software incluye una API para personalizar interfaces de usuario.
A partir de un tutorial, por parte de los autores de Lemur, en el evento SIGIR 2006 tenemos unas interesantes slides que introducen al toolkit.
En algún lado tengo algunos tips que indican como utilizar Lemur rápidamente, espero encontrarlos para poder compartirlos con ustedes.
domingo, septiembre 10, 2006
Aplicaciones online o no?
Los resultados de encuesta en línea, sobre preferencias de 12.843 usuarios con respecto a si le gustan más las aplicaciones que corren en un browser o no, indican que el 62% de los encuestados prefieren las aplicaciones que corren en un explorador a las formas tradicionales de ejecución. Tal encuesta fue llevada a cabo en el blog Read/Write Web.
Acaso esto no hablará del éxito de la filosofía que se deriva de la web 2.0 y de los posibles escenarios futuros que ya vieron tanto Yahho como Google. En los cuales la tendencia se presenta en favor del escritorio virtual de usuario hosteado en tales portales. También recuerden las pretensiones de Google de tener su propio sistema operativo (WebOS).
Acaso esto no hablará del éxito de la filosofía que se deriva de la web 2.0 y de los posibles escenarios futuros que ya vieron tanto Yahho como Google. En los cuales la tendencia se presenta en favor del escritorio virtual de usuario hosteado en tales portales. También recuerden las pretensiones de Google de tener su propio sistema operativo (WebOS).
Educación & tecnología
En esta entrada quería comentarles acerca de dos sitios que me parecieron interesantes, dado que considero que son positivos en la difusión y uso de la tecnología con fines educativos.
TILT (Teachers ImTproving Learning with Technology) es un blog cuyo autor es Danny Maas. Este sitio intenta difundir tecnologías relacionadas con la educación. En sus artículos , el lector puede hallar sugerencias sobre recursos, pequeños tips de cómo utilizar herramientas, experiencias de uso de tecnología relatadas por profesores.
Por otro lado les presento la página "Apuntes y video de bioestadística" (gracias por el dato Daniel) de la Universidad de Málaga, mantenida por el profesor Francisco Javier Barón Lopez. Más allá de ser la página de recursos electrónicos que soportan un curso universitario de estadística, lo interesante es el uso de la tecnología de grabación digital de clases y ejemplos en máquina con paquetes de software. Aparte de los clásicos enunciados de prácticas de los archivos de slides, Francisco se anima a dar un paso más dado que ha grabado y puesto a disposición de todos algunas de sus clases. Grande Francisco!!!.
TILT (Teachers ImTproving Learning with Technology) es un blog cuyo autor es Danny Maas. Este sitio intenta difundir tecnologías relacionadas con la educación. En sus artículos , el lector puede hallar sugerencias sobre recursos, pequeños tips de cómo utilizar herramientas, experiencias de uso de tecnología relatadas por profesores.
Por otro lado les presento la página "Apuntes y video de bioestadística" (gracias por el dato Daniel) de la Universidad de Málaga, mantenida por el profesor Francisco Javier Barón Lopez. Más allá de ser la página de recursos electrónicos que soportan un curso universitario de estadística, lo interesante es el uso de la tecnología de grabación digital de clases y ejemplos en máquina con paquetes de software. Aparte de los clásicos enunciados de prácticas de los archivos de slides, Francisco se anima a dar un paso más dado que ha grabado y puesto a disposición de todos algunas de sus clases. Grande Francisco!!!.
viernes, septiembre 08, 2006
Ohmynews: un diario digital que incorpora la filosofía de la web 2.0
OH My News es un diario digital koreano (publicado también en inglés) que se confecciona gracias a las contribuciones de internautas, loc cuales toman el rol de periodistas.
Cualquier persona puede envíar una historía o una crónica. Luego el equipo de redacción las verificará y si son acordes al estilo del medio las publicará. Aquellos internautas a los cuales se le publiquen sus aportes reciben un pago simbólico que de alguna forma les mejora su prestigio de periodísta aficionado. Según el medio en custión son más de 40.000 los colaboradores.
Cualquier persona puede envíar una historía o una crónica. Luego el equipo de redacción las verificará y si son acordes al estilo del medio las publicará. Aquellos internautas a los cuales se le publiquen sus aportes reciben un pago simbólico que de alguna forma les mejora su prestigio de periodísta aficionado. Según el medio en custión son más de 40.000 los colaboradores.
jueves, septiembre 07, 2006
GahooYoogle, búsquedas en paralelo
GahooYoogle es un servicio de búsquedas que toma una consulta de usuario y la reenvía a Yahoo y Google a la vez. Luego arma una página común de resultados que contiene dos secciones (frames) y en cada una muestra las salidas de cada buscador.
Todavía no le encontré una utilidad real, pero puede ser para alguien sea una herramienta válida.
Todavía no le encontré una utilidad real, pero puede ser para alguien sea una herramienta válida.
Tesis de Doctorado que trata la comunicación entre personas a partir de weblogs
Que alegría me ha dado saber que alguien ha investigado el tema de los weblogs a nivel de doctorado, y específicamente en el área de lingüística.
Fabiana Cristina Komesu en el año 2005 ha defendido con éxito su tesis titulada "Entre o público e o privado: um jogo enunciativo na constituição do escrevente de blogs da internet" en la Universidade Estadual de Campinas Brazil.
En su trabajo a parir de utilziar técnicas del análisis del discurso ha llegado a la conclusión que los autores de weblogs, en general, los construyen con la intención que terceros lean sus escritos y los debatan. Esto es lo que en esencia los diferencia de los diarios personales, los cuales en general no son leídos por terceros.
A continuación les copio el resumen de la tesis:
"Encarando a relação entre o público e o privado como um jogo enunciativo que se evidencia nos blogs, comumente chamados de ?diários íntimos da internet?, este trabalho tem como objetivo investigar a dimensão lingüístico-discursiva constitutiva da atividade do escrevente nesse gênero do discurso. Para tanto, fundamenta-se na hipótese e que a escrita dos blogs emerge em meio a condições de produção do discurso que possibilitam práticas sociais de exposição pública da intimidade ? como narrativas sobre cotidiano e histórias pessoais ? no espaço de interação da internet. De nosso ponto de vista, o modo de enunciação dos escreventes de blogs é caracterizado pela relação dinâmica entre a publicização de si e a intimidade construída com o leitor, relação que é estabelecida mediante a instauração de um lugar de visibilidade do enunciador em uma cenografia da intimidade compartilhada com o co-enunciador. A prática dos blogs que são associados aos diários íntimos engendra elementos verbais e não-verbais que retomam, na qualidade de ruínas do enunciado genérico, a intimidade pressuposta na prática diarista, mas segundo efeitos de poder distintos. Diferentemente da ?busca de si? e do distanciamento do olhar alheio, o funcionamento discursivo dos blogs visa à busca do outro, com a finalidade de fazer ver e ser visto na rede. A profusão de textos sobre as vidas individuais dos sujeitos na internet não implica variedade de aspectos ou perspectivas, mas a raridade de modos de dizer a vida e de refletir sobre as relações com o outro na sociedade.
Esta análise aponta, portanto, para a necessidade (incessante) de falar de si, radicalmente fundada na impossibilidade (histórica) de dizer o novo, o revolucionário, o libertário na e pela linguagem, como esperado em textos veiculados na internet "
Fabiana Cristina Komesu en el año 2005 ha defendido con éxito su tesis titulada "Entre o público e o privado: um jogo enunciativo na constituição do escrevente de blogs da internet" en la Universidade Estadual de Campinas Brazil.
En su trabajo a parir de utilziar técnicas del análisis del discurso ha llegado a la conclusión que los autores de weblogs, en general, los construyen con la intención que terceros lean sus escritos y los debatan. Esto es lo que en esencia los diferencia de los diarios personales, los cuales en general no son leídos por terceros.
A continuación les copio el resumen de la tesis:
"Encarando a relação entre o público e o privado como um jogo enunciativo que se evidencia nos blogs, comumente chamados de ?diários íntimos da internet?, este trabalho tem como objetivo investigar a dimensão lingüístico-discursiva constitutiva da atividade do escrevente nesse gênero do discurso. Para tanto, fundamenta-se na hipótese e que a escrita dos blogs emerge em meio a condições de produção do discurso que possibilitam práticas sociais de exposição pública da intimidade ? como narrativas sobre cotidiano e histórias pessoais ? no espaço de interação da internet. De nosso ponto de vista, o modo de enunciação dos escreventes de blogs é caracterizado pela relação dinâmica entre a publicização de si e a intimidade construída com o leitor, relação que é estabelecida mediante a instauração de um lugar de visibilidade do enunciador em uma cenografia da intimidade compartilhada com o co-enunciador. A prática dos blogs que são associados aos diários íntimos engendra elementos verbais e não-verbais que retomam, na qualidade de ruínas do enunciado genérico, a intimidade pressuposta na prática diarista, mas segundo efeitos de poder distintos. Diferentemente da ?busca de si? e do distanciamento do olhar alheio, o funcionamento discursivo dos blogs visa à busca do outro, com a finalidade de fazer ver e ser visto na rede. A profusão de textos sobre as vidas individuais dos sujeitos na internet não implica variedade de aspectos ou perspectivas, mas a raridade de modos de dizer a vida e de refletir sobre as relações com o outro na sociedade.
Esta análise aponta, portanto, para a necessidade (incessante) de falar de si, radicalmente fundada na impossibilidade (histórica) de dizer o novo, o revolucionário, o libertário na e pela linguagem, como esperado em textos veiculados na internet "
miércoles, septiembre 06, 2006
Google, todos los días un nuevo servicio
Google ha inagurado un nuevo servicio de consulta. Ahora los historiadores, sociólogos, periodistas, entre otros profesionales podrán utilizar "News Archive Search" [http://news.google.com/archivesearch?ned=us]. En News Archive se indexan los archivos históricos de distintos medios periodísticos, permitiendo que los usuarios puedan hacer consultas sobre hechos específicos de la historia y hasta mostrar información en base a líneas de tiempos (timelines).
Prueben en búsqueda avanzada por "Fidel Castro" y restringido solamente al año 1959.
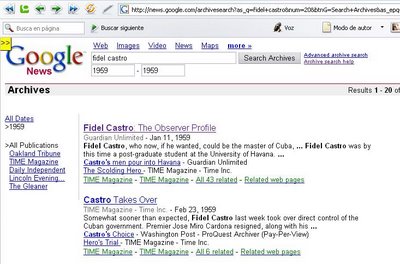
Prueben en búsqueda avanzada por "Fidel Castro" y restringido solamente al año 1959.

Reflexiones sobre el posible fin del diario papel
The economist ha publicado un par de artículos sobre el posible fin o desaparición del diario papel. En un artículo titulado "¿Quién ha matado a los diarios? " se reflexiona acerca de los cambios en hábitos informativos que la sociedad está transitando. Luego en un segundo artículo se aportan datos que ilustran de mejor forma este fenómeno.
Una reflexión interesante dice que “The biggest enemy of paid-for newspapers is time”. Como conclusión se cita que la información en papel paga no será un producto masivo, tendrá su público reducido y pagarán mayores costos por unl diario más especializado.
Una reflexión interesante dice que “The biggest enemy of paid-for newspapers is time”. Como conclusión se cita que la información en papel paga no será un producto masivo, tendrá su público reducido y pagarán mayores costos por unl diario más especializado.
martes, septiembre 05, 2006
Estudio sobre webspam por Carlos Gonzalo
Carlos Gonzalo ha publicado en BID en el número de junio 2006 un artículo cuyo título es Tipología y análisis de enlaces web: aplicación al estudio de los enlaces fraudulentos y de las granjas de enlaces".
Quiero comentar que este tema es de especial interés por partes de las grandes firmas como Yahoo, Google, Technorati, Microsoft. Ya hay algunas investigaciones con buenos resultados de perfomance en la detección de páginas spam, ya sea por análisis de enlaces o análisis de contenidos. Es más, Carlos Castillo o Chato en su Laboratorio italiano dispone de una colección de prueba de páginas spam que gratuitamente la comparte con grupos que deseen investigar en el tema.
El resumen del mencionado artículo es el siguiente:
Dentro de la estructura de enlaces de un sitio web se pueden distinguir dos tipos principales de enlaces, los de navegación y los semánticos. Los buscadores sólo tienen en cuenta el segundo tipo, ya que aporta valor semántico a través del texto de anclaje (anchor text). En sitios no académicos, los principales motivos de creación de estos enlaces semánticos son puramente comerciales y de marketing. Una subclase de enlace de marketing es la que podríamos llamar de enlaces fraudulentos, conocidos popularmente como (enlaces) spam. La creación masiva de este tipo de enlaces (granja de enlaces, o link farm) tiene como objetivo modificar el comportamiento del algoritmo PageRank. Google ha creado el algoritmo TrustRank con la finalidad de detectar granjas de enlaces.
Quiero comentar que este tema es de especial interés por partes de las grandes firmas como Yahoo, Google, Technorati, Microsoft. Ya hay algunas investigaciones con buenos resultados de perfomance en la detección de páginas spam, ya sea por análisis de enlaces o análisis de contenidos. Es más, Carlos Castillo o Chato en su Laboratorio italiano dispone de una colección de prueba de páginas spam que gratuitamente la comparte con grupos que deseen investigar en el tema.
El resumen del mencionado artículo es el siguiente:
Dentro de la estructura de enlaces de un sitio web se pueden distinguir dos tipos principales de enlaces, los de navegación y los semánticos. Los buscadores sólo tienen en cuenta el segundo tipo, ya que aporta valor semántico a través del texto de anclaje (anchor text). En sitios no académicos, los principales motivos de creación de estos enlaces semánticos son puramente comerciales y de marketing. Una subclase de enlace de marketing es la que podríamos llamar de enlaces fraudulentos, conocidos popularmente como (enlaces) spam. La creación masiva de este tipo de enlaces (granja de enlaces, o link farm) tiene como objetivo modificar el comportamiento del algoritmo PageRank. Google ha creado el algoritmo TrustRank con la finalidad de detectar granjas de enlaces.
lunes, septiembre 04, 2006
Trabajo de investigación comentado "Language Model Mixtures for Contextual Ad Placement in Personal Blogs"
José Perez Aguera, en su blog, ha publicado una entrada relacionada con el paper de Mishne y Rijke titulado "Language Model Mixtures for Contextual Ad Placement in Personal Blogs". En ella comenta las características de la investigación en cuestión.
En el mismo blog, recomiendo ver los artículos sobre la herramienta Terrier (TERabyte RetrIEveR), la cual es útil a la hora de indexar un corpus o colección de textos.
En el mismo blog, recomiendo ver los artículos sobre la herramienta Terrier (TERabyte RetrIEveR), la cual es útil a la hora de indexar un corpus o colección de textos.
domingo, septiembre 03, 2006
Geolocalización de visitantes de blogs
IP2Map es un servicio que a partir de la dirección de red IP, que exponen los visitantes de un blog o página web convencional cuando la visitan, arma un mapamundi donde con puntos de color se resaltan los distintos lugares de donde provienen los internautas.
Cuando visiten la página del servicio hallarán una porción de código a insertar en su blog, no hay que suscribirse, solo copiar el código.
http://www.ip2map.com/
Cuando visiten la página del servicio hallarán una porción de código a insertar en su blog, no hay que suscribirse, solo copiar el código.
http://www.ip2map.com/
Reflexiones acerca de la comunicación entre personas
Les presento un artículo aparecido en el diario La Nación de Argentina el domingo 27 de agosto del 2006. En el mismo el periodista expresa su preocupac ión por la pérdida de conversación entre personas, acto que tal vez ha sido suplantado por nuevas formas digitales de comunicación.
Algo más que “chatear”
Andrew Graham-Yooll
Sinceramente, ¿recuerda usted cuándo disfrutó por última vez de una buena conversación? No se trata de un diálogo de negocios, de una reunión social donde se saluda a mucha gente, de un conventilleo entre vecinos, de un chusmerío en el conventillo, ni de esos encuentros fugaces que no exceden el intercambio superficial. Desde diversos sectores de la academia y de la ciencia se está denunciando la desaparición de la conversación. Estamos acostumbrados a ver a cuatro personas entrar en un restaurante y cada uno, en silencio, saca un telefonito del bolsillo del caballero o la cartera de la dama para jugar con teclas y botones en el celular. Hace unos diez años le echábamos la culpa del silencio de esos comensales a la televisión, dado que los contertulios se quedaban mirando embobados cualquier programa. Hace veinte años, esas cuatro personas se habrían reunido para hablar de los abruptos cambios de la inflación o de la estabilización de precios. Hace treinta años no se reunían por miedo a la represión del gobierno militar. Hace cuarenta lo hacían para idealizar una inminente revolución y hace cincuenta habrían hablado de proyectos políticos. A lo largo de medio siglo venimos corriendo el riesgo de quedarnos sin habla.
En mi adolescencia, y por razones de trabajo, aprendí a usar el código Morse para telegrafiar y recibir entre 20 y 25 palabras por minuto. Hoy, una comunicación por "mensajeame" lleva tan sólo abreviaciones extremas. La telegrafía de ayer parece ahora un exceso de locuacidad frente a lo que se llama "chatear", de la palabra inglesa chat, que en su traducción precelular significa "charlar". La charla no constituía una conversación, si bien llevaba implícito un momento de distensión con un diálogo liviano. Es decir, el "chat" de antes requería hablar. No se trata de criticar los cambios en las costumbres; sí, de lamentar la pérdida de uso del idioma.
Estas reflexiones surgen de la preocupación docente por el futuro de la redacción y su gramática, y también de la publicación en Estados Unidos de dos libros sobre la decadencia de la conversación. Uno es Conversación, historia de un arte que se pierde, de Stephen Miller, que editó la Universidad de Yale; el otro, La era de la conversación, de Benedetta Craveri, que publicó The New York Review of Books. Ambos libros concluyen que la buena conversación, algo situado entre el silencio y el monólogo aburrido, es hoy tema de nostalgias. La conversación debía fluir naturalmente, reflejando razonamiento, conocimiento (que no es lo mismo que información, obtenida por Google), humor y sensación de igualdad. El conversador hábil debía saber escuchar. Ahora, en la era de confesar lo personal sin inhibiciones, convertimos esto en relato desesperado, sin buscar retorno de quien escucha.
Estamos muy acostumbrados a la gente (léase, por ejemplo, políticos) que habla pero que no dialoga, y en la confusión nos encontramos ante la inminente extinción de lo que fue un ejercicio tan agradable como lejano: la buena conversación.
Fuente: "La Nación"
Link http://www.lanacion.com.ar/834628
Algo más que “chatear”
Andrew Graham-Yooll
Sinceramente, ¿recuerda usted cuándo disfrutó por última vez de una buena conversación? No se trata de un diálogo de negocios, de una reunión social donde se saluda a mucha gente, de un conventilleo entre vecinos, de un chusmerío en el conventillo, ni de esos encuentros fugaces que no exceden el intercambio superficial. Desde diversos sectores de la academia y de la ciencia se está denunciando la desaparición de la conversación. Estamos acostumbrados a ver a cuatro personas entrar en un restaurante y cada uno, en silencio, saca un telefonito del bolsillo del caballero o la cartera de la dama para jugar con teclas y botones en el celular. Hace unos diez años le echábamos la culpa del silencio de esos comensales a la televisión, dado que los contertulios se quedaban mirando embobados cualquier programa. Hace veinte años, esas cuatro personas se habrían reunido para hablar de los abruptos cambios de la inflación o de la estabilización de precios. Hace treinta años no se reunían por miedo a la represión del gobierno militar. Hace cuarenta lo hacían para idealizar una inminente revolución y hace cincuenta habrían hablado de proyectos políticos. A lo largo de medio siglo venimos corriendo el riesgo de quedarnos sin habla.
En mi adolescencia, y por razones de trabajo, aprendí a usar el código Morse para telegrafiar y recibir entre 20 y 25 palabras por minuto. Hoy, una comunicación por "mensajeame" lleva tan sólo abreviaciones extremas. La telegrafía de ayer parece ahora un exceso de locuacidad frente a lo que se llama "chatear", de la palabra inglesa chat, que en su traducción precelular significa "charlar". La charla no constituía una conversación, si bien llevaba implícito un momento de distensión con un diálogo liviano. Es decir, el "chat" de antes requería hablar. No se trata de criticar los cambios en las costumbres; sí, de lamentar la pérdida de uso del idioma.
Estas reflexiones surgen de la preocupación docente por el futuro de la redacción y su gramática, y también de la publicación en Estados Unidos de dos libros sobre la decadencia de la conversación. Uno es Conversación, historia de un arte que se pierde, de Stephen Miller, que editó la Universidad de Yale; el otro, La era de la conversación, de Benedetta Craveri, que publicó The New York Review of Books. Ambos libros concluyen que la buena conversación, algo situado entre el silencio y el monólogo aburrido, es hoy tema de nostalgias. La conversación debía fluir naturalmente, reflejando razonamiento, conocimiento (que no es lo mismo que información, obtenida por Google), humor y sensación de igualdad. El conversador hábil debía saber escuchar. Ahora, en la era de confesar lo personal sin inhibiciones, convertimos esto en relato desesperado, sin buscar retorno de quien escucha.
Estamos muy acostumbrados a la gente (léase, por ejemplo, políticos) que habla pero que no dialoga, y en la confusión nos encontramos ante la inminente extinción de lo que fue un ejercicio tan agradable como lejano: la buena conversación.
Fuente: "La Nación"
Link http://www.lanacion.com.ar/834628
Guía del Lenguaje Perl - 1ra parte
Hace algunos años atrás, a fin de preparar la práctica de una serie de asignaturas decidí utilizar el lenguaje Perl. La idea de programar en tales asignaturas tenía que ver con comprobar empiricamente algunos supuestos de la teoría. Seleccioné Perl por varias razones, pero la principal se centraba en que no quería que el lenguaje sea el obstáculo que no permitiera llegar al conocimiento. De esta forma, opte por Perl dado que necesitaba un lenguaje potente, con una buena curva de aprendizaje, que tuviera APIs para red, bases de datos, IR, IA, entre otros.
Hoy, acomodando "papeles digitales" he encontrado esta guía que confeccioné junto a Fernando Lorge y Gabriel Tolosa. Para no aburrirlos la pasaré en capítulos, creo que a los que les interesa IR está guía les será útil.
Hoy, acomodando "papeles digitales" he encontrado esta guía que confeccioné junto a Fernando Lorge y Gabriel Tolosa. Para no aburrirlos la pasaré en capítulos, creo que a los que les interesa IR está guía les será útil.
Guía Introductoria al Lenguaje Perl
versión 2.1
Fernando Bordignon, Gabriel Tolosa y Fernando Lorge
{bordi, tolosoft, florge}@mail.unlu.edu.ar
La presente guía es una versión “quick and dirty” -tal como dicen los anglosajones- con el objetivo de lograr un primer acercamiento al lenguaje. Se sugiere complementar el estudio con bibliografía adicional, como la recomendada.
Charles Babbage dijo "se cometen muchos menos errores usando datos incorrectos, que no empleando dato alguno". Es por esto que se pide perdón por los posibles errores que se hayan deslizado, y se solicita al lector que contribuya a mejorar este material de estudio, a partir de las correcciones y críticas que pueda aportar.
Fuentes de bibliografía adicional sobre el lenguaje Perl:
· Página oficial del lenguaje Perl. http://www.perl.com
· Curso de Perl (en inglés) http://fpg.uwaterloo.ca/perl/start.html
· Perl Mongers. http://www.perl.org/
· Editorial O´Reilly, página del lenguaje Perl. http://perl.oreilly.com/
· PerlDoc. http://www.perldoc.com/
· The Perl Journal. http://www.tpj.com/
· Perl Chile. http://www.perl.cl/
· En su
Lugares de descarga del lenguaje:
· Página oficial del lenguaje Perl. http://www.perl.com
· CPAN - Módulos Perl. http://www.cpan.org/
· Activestate. Perl para Windows. http://www.activestate.com/
Filosofía de Perl: "Hay más de una forma de hacerlo" Larry Wall, su autor.
CAPITULO I: Introducción al Lenguaje
"Si no noto la resistencia del papel frente a la pluma, me siento incapacitado" Jean Daniel
Perl significa Lenguaje práctico de extracción y reporte (Practical Extraction and Report Language) . Su creador fue Larry Wall, y su objetivo era simplificar las tareas habituales a realizar en el sistema operativo Unix. Hoy es un lenguaje de propósito general, de alta portabilidad y es la herramienta principal que utilizan los webmasters para implementar programación a través de la interfase CGI.
Perl es un lenguaje interpretado, aunque transparentemente compile los programas antes de ejecutarlos. Es por ello que los ortodoxos de la comunidad hablan de guiones (scripts) y no de programas. Existe una numerosa cantidad de programadores Perl distribuidos a lo largo del mundo, ellos día a día producen nuevos módulos de librería que extienden asombrosamente las capacidades del lenguaje. En Perl, practicamente, es posible programar casi cualquier problema; maneja: comunicaciones entre computadoras, bajo protocolos TCP/IP; implementa hilos de ejecución (threads); implementa -opcionalmente- el estilo de programación orientado a objetos, posee APIs con todos los protocolos populares de aplicación en Internet. Aunque su punto debil es la perfomance en la ejecución de guiones -no alcanza las velocidades ofrecidas por lenguajes como el C-, Perl es un excelente lenguaje destinado al aprendizaje y el desarrollo de prototipos de modelos de software.
Perl es gratuito, hay completa libertad de copiar el código fuente, compilarlo, imprimirlo, compartirlo, etc, pero todo esto es bajo la licencia GNU, que en términos generales ordena que cualquier programa que se desarrolle se debe liberar, o sea si Ud. puede utilizar el código hecho por otros; otros pueden usar el código hecho por Ud.
Como se mencionó anteriormente, la portabilidad es una características de Perl. Los guiones se pueden ejecutar sobre distintos sistemas operativos como ser: Linux, System de Macintosh, Microsoft Windows, Solaris de Sun, BSD, etc. En definitiva, un programa puede correr en cualquier sistema operativo sin tener que modificar el código fuente; solamente es necesario poseer el interprete de Perl para cada sistema y librerías adicionales que use.
Con Perl se pueden: construir pequeños programas destinados a ser usados como filtros para obtener información en base a la lectura de archivos, realizar búsquedas, etc. Es uno de los lenguajes más utilizados en la programación de la interfase CGI, que sirve para el intercambio de información entre aplicaciones externas y el espacio web. Por ejemplo programas de búsqueda, y procesamiento de formularios, entre otros.
El siguiente es el clásico ejemplo de primer programa Perl
#!/usr/local/bin/perl
print "Hola Mundo!!!\n";
En la primer linea se le indica al sistema operativo el camino del interprete Perl, para que lo pueda cargar y ejecutar, y le pase como parámetro el guión que se halla más abajo. Por norma, todo guión lleva la extensión pl y se lo escribe utilizando un editor ASCII normal. Inicialmente, para ejecutar un programa siga la siguiente sintaxis:
perl
Para un mejor análisis de un programa, puede redireccionarse su salida a un archivo utilizando en la orden de ejecución el símbolo de redirección ">" y a continuación un nombre de archivo.
CAPITULO 2: Tipos de Datos, Variables y Arreglos
"La comunicación se compone de quien habla, quien escucha y lo que se dice". Aristóteles
Perl permite representar los siguientes tipos de datos básicos: reales, enteros, cadenas de caracteres y booleanos.
Los tipos numéricos (reales y enteros).
Los valores numéricos se presentan en forma de valores reales codificados en doble precisión. Este formato interno se utiliza para todas las operaciones aritméticas.
$z = 0.127; # real
$x = 3.22e-14; # real
$c = 1567; # entero
$d = -122; # entero
Los valores enteros no pueden empezar por cero porque esto permite especificar un entero mediante su codificación octal o hexadecimal. El código octal comienza con cero 0; el código hexadecimal comienza con 0x.
$x = 0377; # Representación octal, equivale a 255 decimal
$y = 0xff; # Representación hexadecimal, equivale a 255
Las cadenas de caracteres.
Las cadenas de caracteres se representan por medio de un sucesión de caracteres delimitada por comillas ó apóstrofes. Cuando una cadena se delimitada por comillas, toda variable referenciada en el interior de la cadena se evalúa y se reemplaza por su valor. Por ejemplo:
$cadena = "Brothers";
$almace = "Blues $cadena";
Por el contrario, las cadenas de caracteres delimitadas por apóstrofes se dejan intactas.
Existe una sintaxis especial que permite delimitar una cadena de caracteres cuando contiene varias líneas y/o comillas o apóstrofes. El fin de la cadena se determina por la nueva línea que contiene únicamente el identificador. Éste no debe ir precedido por un espacio ni marca de tabulación. Por ejemplo:
$cadena = <
hola,
buenos días,
adios,
SALUDO
El tipo booleano.
El tipo booleano existe de modo implícito, es decir, un número es falso si es igual a cero y verdadero en cualquier otro caso. Como el cero está asociado a la cadena vacía (""), ésta también equivale al valor falso.
Representaciones de datos.
Perl maneja datos escalares, siendo todos aquellos que contienen un valor; no importa si es real, entero, caracter o cadena; el lenguaje los reconoce automáticamente.El lenguaje posee tres tipos de representaciones de datos
Las representaciones de datos son determinadas por la anteposición de un caracter especial.
Todas las representaciones tienen su propio nombre, así como las etiquetas, funciones, archivos y manejadores de directorios.
Variables escalares.
Se utiliza el caracter $ para indicar un valor escalar. La asociación ó bind de una variable con valor se hace con el caracter =.
$foo = 55.23;
$foo = 'esta es una cadena';
$foo = "era $foo antes"; # variable interpolada.
$salida= `cd`; # Se invoca al sistema operativo y el resultado
# de la salida
($a, $b) = ($b, $a) # intercambio (swap)
Ejemplo:
Sumar dos números y luego aplicar el operador de post-incremento
#!/usr/local/bin/perl
$a = 10; $b = 5;
$suma = $a + $b;
print "Resultado:”.$suma.”\n";
$suma++;
print "Despues de incrementar: $suma \n";
Ejemplo:
Verificar el método de intercambio de variables
#!/usr/local/bin/perl
$a = “Mundo”; $b = “Hola”;
($a, $b) = ($b, $a);
print "La famosa frase es $a $b!!! \n";
Ejemplo:
Ingresar dos cadenas y comparar si son iguales, idependientemente que sus caracteres estén en mayúsculas o minúsculas.
#!/usr/local/bin/perl
print "Ingrese 1er cadena:";
$cadenaa=[STDIN]
chop($cadenaa); #chomp elimina de cadenaa el enter
print "Ingrese 2da cadena:";
$cadenab=
chop($cadenab);
$tmpa = "\U$cadenaa\E"; $tmpb = "\U$cadenab\E";
if ($tmpa eq $tmpb) {print "$tmpa y $tmpb son iguales \n";}
else {print "$tmpa y $tmpb NO son iguales \n";}
sábado, septiembre 02, 2006
Off topic: Sitio creativo sobre el mundo de los carteles
Para el ocio les presento un sitio creativo dedicado a recolectar fotografías de carteles (de la vía pública) curiosos. "Proyecto Cartele" es un sitio interesante y con buen diseño gráfico (hay un par de arquitectos detrás).
Les dejo algunos ejemplos de fotografías que ellos publican:



Les dejo algunos ejemplos de fotografías que ellos publican:



viernes, septiembre 01, 2006
Un poco de teoría: Redes de Mundo Pequeño
Un artículo interesante sobre sociología y establecimiento de redes sociales basadas en contactos personales. Estas observaciones de Milgran fueron tomadas actualmente para entender y aprovechar la dinámica de las comunidades virtuales.
Una serie de investigaciones realizadas en la década del 60 por Milgran [Stanley Milgram, "The Small World Problem", Psychology Today, May 1967. pp 60 - 67] permitieron analizar la relación de conocimiento existente entre los seres humanos del planeta.
Milgran diseño un experimento que tenía por objetivo hallar la distancia existente entre dos personas cualesquiera de Estados Unidos, para luego estimar cuantos conocidos hacen falta para conectar a dos personas cualesquiera en el planeta.
En un primer paso se eligieron dos personas a las cuales había que hacerle llegar cartas, una mujer de un estudiante de Massachusetts y un operador de bolsa de Boston. El experimento partió de las ciudades de Wichita en Kansas y Omaha en Nebraska, por su importante distancia a Boston. En un segundo paso, Milgran, envió una serie de cartas a habitantes de Wichita y Omaha seleccionados al azar, donde se les indicaba que:
1) Debían agregar su nombre a la lista de itinerario recibida.
2) Debían envíar una postal a Harvard a modo de elemento de control.
3) Luego, si se conocía a la persona destino se le debía entregar directamente la carta. En caso contrario se debería intentar contactarla por un conocido entregando la carta recibida con el itinerario actualizado. El conocido debería seleccionarse en base a su grupo de contactos personales fijándose quien tendría más posibilidades de que contribuya que la carta llegue lo más rápido posible a destino.
El experimento concluyó cuando 42 de las 160 cartas llegaron a destino, los intermediarios estuvieron en un rango de dos a doce contactos. El número representativo de contactos se calculo en seis, es decir que todo par de personas de este planeta, seleccionadas al azar están separadas por solo seis personas.
A raíz de este experimento Milgram concluyó que habitamos en un mundo pequeño, debido a que nuestra sociedad ha sido edificada como una red densa.
Un estudio más reciente [Science vol 301, p 827] llevado a cabo utilizando la red correo electrónico de Internet, ayuda a reforzar la teoría de Milgram. En la Universidad de Columbia el sociologo Watts determinó experimentalmente que cualquier internauta está conectado con el resto a una distancia promedio de tan sólo seis mails enviados.
En la investigación se analizó el tráfico del correo electrónico de más de 60.000 usuarios voluntarios de 166 países. Donde los usuarios voluntarios debían reenviar un mensaje de correo electrónico hasta que éste llegara a alguno de los 18 receptores finales (sitos en 13 países), de quienes solo se conocía su nombre, profesión y su lugar de residencia. Los usuarios enviaron sus respectivos mensajes a quienes suponían se encontraban a menor distancia de los receptores finales. Como resultado se conformaron más de 24.000 cadenas de mensajes, donde solo, en promedio, se necesitó de 6 reenvíos para llegar a los usuarios objetivo. Un resultado adicional del estudio de Watts es que no aparecen grandes centros ò hubs (personas que poseen gran red de contactos).
Por otro lado el estudio revela que personas poderosas son actores de una mayor cantidad de contactos y que sus contactos conectan con otros actores poderosos. Es decir que aquellas personas con gran poder se contactan a su vez con pares poderosos, ello lleva a deducir que lo que para el normal de la gente lleva seis pasos a este tipo de personas le puede llevar menos. Por eso mientras más contactos bien conectados se tenga se poseen mejores y mayores oportunidades.
De estas investigaciones surgió el concepto de redes que verifican las reglas de un “mundo pequeño”, las cuales poseen en su topología dos características: a) todo nodo está fuertemente conectado con muchos de sus vecinos pero débilmente con algunos pocos elementos alejados (fenómeno denominado agrupamiento o clustering) y b) todo nodo se puede conectar con cualquier otro con sólo unos pocos saltos. De lo anterior se deduce: a) que la información se transfiere rápidamente entre dos elementos cualquiera y b) que existe un reducido número de nodos claves por donde circula un gran porcentaje del tráfico total.
Las redes de mundo pequeño no sólo sugieren que existen caminos cortos entre pares de nodos elegidos al azar, sino que los individuos pueden encontrar en la práctica dichos caminos utilizando simplemente información local sobre la red y estrategias heurísticas simples. En general los nodos tratan de seleccionar pares bien conectados (hubs) de su grupo a los efectos de transmitir información, esto le permite que el flujo pueda llegar a destino de forma eficiente.

Una serie de investigaciones realizadas en la década del 60 por Milgran [Stanley Milgram, "The Small World Problem", Psychology Today, May 1967. pp 60 - 67] permitieron analizar la relación de conocimiento existente entre los seres humanos del planeta.
Milgran diseño un experimento que tenía por objetivo hallar la distancia existente entre dos personas cualesquiera de Estados Unidos, para luego estimar cuantos conocidos hacen falta para conectar a dos personas cualesquiera en el planeta.
En un primer paso se eligieron dos personas a las cuales había que hacerle llegar cartas, una mujer de un estudiante de Massachusetts y un operador de bolsa de Boston. El experimento partió de las ciudades de Wichita en Kansas y Omaha en Nebraska, por su importante distancia a Boston. En un segundo paso, Milgran, envió una serie de cartas a habitantes de Wichita y Omaha seleccionados al azar, donde se les indicaba que:
1) Debían agregar su nombre a la lista de itinerario recibida.
2) Debían envíar una postal a Harvard a modo de elemento de control.
3) Luego, si se conocía a la persona destino se le debía entregar directamente la carta. En caso contrario se debería intentar contactarla por un conocido entregando la carta recibida con el itinerario actualizado. El conocido debería seleccionarse en base a su grupo de contactos personales fijándose quien tendría más posibilidades de que contribuya que la carta llegue lo más rápido posible a destino.
El experimento concluyó cuando 42 de las 160 cartas llegaron a destino, los intermediarios estuvieron en un rango de dos a doce contactos. El número representativo de contactos se calculo en seis, es decir que todo par de personas de este planeta, seleccionadas al azar están separadas por solo seis personas.
A raíz de este experimento Milgram concluyó que habitamos en un mundo pequeño, debido a que nuestra sociedad ha sido edificada como una red densa.
Un estudio más reciente [Science vol 301, p 827] llevado a cabo utilizando la red correo electrónico de Internet, ayuda a reforzar la teoría de Milgram. En la Universidad de Columbia el sociologo Watts determinó experimentalmente que cualquier internauta está conectado con el resto a una distancia promedio de tan sólo seis mails enviados.
En la investigación se analizó el tráfico del correo electrónico de más de 60.000 usuarios voluntarios de 166 países. Donde los usuarios voluntarios debían reenviar un mensaje de correo electrónico hasta que éste llegara a alguno de los 18 receptores finales (sitos en 13 países), de quienes solo se conocía su nombre, profesión y su lugar de residencia. Los usuarios enviaron sus respectivos mensajes a quienes suponían se encontraban a menor distancia de los receptores finales. Como resultado se conformaron más de 24.000 cadenas de mensajes, donde solo, en promedio, se necesitó de 6 reenvíos para llegar a los usuarios objetivo. Un resultado adicional del estudio de Watts es que no aparecen grandes centros ò hubs (personas que poseen gran red de contactos).
Por otro lado el estudio revela que personas poderosas son actores de una mayor cantidad de contactos y que sus contactos conectan con otros actores poderosos. Es decir que aquellas personas con gran poder se contactan a su vez con pares poderosos, ello lleva a deducir que lo que para el normal de la gente lleva seis pasos a este tipo de personas le puede llevar menos. Por eso mientras más contactos bien conectados se tenga se poseen mejores y mayores oportunidades.
De estas investigaciones surgió el concepto de redes que verifican las reglas de un “mundo pequeño”, las cuales poseen en su topología dos características: a) todo nodo está fuertemente conectado con muchos de sus vecinos pero débilmente con algunos pocos elementos alejados (fenómeno denominado agrupamiento o clustering) y b) todo nodo se puede conectar con cualquier otro con sólo unos pocos saltos. De lo anterior se deduce: a) que la información se transfiere rápidamente entre dos elementos cualquiera y b) que existe un reducido número de nodos claves por donde circula un gran porcentaje del tráfico total.
Las redes de mundo pequeño no sólo sugieren que existen caminos cortos entre pares de nodos elegidos al azar, sino que los individuos pueden encontrar en la práctica dichos caminos utilizando simplemente información local sobre la red y estrategias heurísticas simples. En general los nodos tratan de seleccionar pares bien conectados (hubs) de su grupo a los efectos de transmitir información, esto le permite que el flujo pueda llegar a destino de forma eficiente.
Suscribirse a:
Comentarios (Atom)

{kind=link}