Luego de tanto tiempo de esperar que los grandes motores de búsqueda generen interfaces donde los usuarios puedan expresar de una forma integral su perfil o preferencias (algunos tienen algo así, pero es muy reducido) una primer posible solución ha llegado. Esta viene por el camino del explorador. CustomizeGoogle es una extensión que mejora los resultados provistos por Google agregando cierta información extra y eliminando la no querida.
Entre sus opciones tenemos, por ejemplo:
a) Filrar resultados que aparezcan en una lista de expresiones regulares de URLs.
Esto es útil cuando por ejemplo no se desea en una búsqueda técnica información
comercial de sitios como deremate, ebay, mercado libre, entre otros.
Un conjunto de buenos filtros mejoraría la presición de la lista de resultados
b) Se pueden restringir las cookies enviadas y así trabajar con mayor privacidad.
c) Eliminar la publicidad agregada (enlaces patrocinados)
d) En resultados añadir enlaces a otros servicios de búsqueda
Ua persona a lo largo de su jornada puede tener distintas intenciones de búsqueda (entretenimiento, compras, estudio, investigación, etc) en cada ambiente, generalmente, las preferencias no son las mismas. Por eso una crítica a este buen producto es que le falta definir perfiles, así un usuario puede tener sus preferencias según el ámbito o tipo de búsqueda que haga.
martes, octubre 31, 2006
lunes, octubre 30, 2006
Hola, Hola, aquí probando Google Co-op
Luego que Yahoo Search Builder me defraudara como promesa de buscador vertical (no es más que una copia no mejorada de Rollyo,) el jueves de la semana pasada comencé a trabajar con la nueva propuesta de Google, llamada "Google Co-Op".
Hasta el momento vamos 6/10, si se fijan a la izquierda del blog hallarán una caja de búsqueda la cual es la interface con un buscador, el cual configuré para que opere eclusivamente sobre el dominio de instituciones educativas argentinas (inserté 2.838 direcciones de sitios de mi propia cosecha y que no son todos simplemente "edu.ar"). Hasta el momento hay problemas con el recall o exhaustividad, según la gente de Goggle (gracias Guha y Mister Co-Op Engineer) esto se debe a que todavía el producto no está puesto a punto para operar con otras lenguas más allá de la inglesa (también hay que ser tolerante con un producto estado beta).
Pruebenló y digan que les parece!!!
Hasta el momento vamos 6/10, si se fijan a la izquierda del blog hallarán una caja de búsqueda la cual es la interface con un buscador, el cual configuré para que opere eclusivamente sobre el dominio de instituciones educativas argentinas (inserté 2.838 direcciones de sitios de mi propia cosecha y que no son todos simplemente "edu.ar"). Hasta el momento hay problemas con el recall o exhaustividad, según la gente de Goggle (gracias Guha y Mister Co-Op Engineer) esto se debe a que todavía el producto no está puesto a punto para operar con otras lenguas más allá de la inglesa (también hay que ser tolerante con un producto estado beta).
Pruebenló y digan que les parece!!!
domingo, octubre 29, 2006
Off topic: Premio Ig Nobel 2006
Todos los años, junto con los premios Nobel la revista de humor Annals of Improbable Research entrega los premios “Ig Nobel”. Los cuales son una sátira de los tradicionales. son una parodia de los premio Nobel . En esencia, los IG Nobel se entregan a personas cuyos logros "no pueden o no deberían ser reproducidos".
Algunos de los premios de este año son:
· Ornitología: Ivan R. Schwab y Philip R.A. May por investigar y explicar por qué los pájaros carpinteros no sufren de dolor de cabeza.
· Paz: Howard Stapleton por inventar un repelente electromagnético de adolescentes, pero no adultos. Se trata de un artefacto que genera un sonido audible por los adolescentes pero no por adultos y que más tarde fue usado para convertirlo en un tono de teléfono que pueden oir los adolescentes pero no sus profesores.
· Acústica: D. Lynn Halpern y Randolph Blake por sus experimentos acerca de por qué a la gente le desagrada el ruido de las uñas arañando una pizarra.
· Medicina: Francis M. Fesmire, por su informe "Interrupción del hipo con un masaje rectal dactilar".
· Biología: Bart Knols y Ruurd de Jong, por mostrar que el mosquito Anofeles femenino, que transmite la malaria, se ve tan atraído por queso limburger como por el olor de los pies humanos.
· Matemática: Nic Svensons y Pier Barnes por calcular el número de fotografías que hay que tomar a un grupo para asegurar que todos los que posan aparecerán con los ojos abiertos en la imagen.
Fuente: Wikipedia
Algunos de los premios de este año son:
· Ornitología: Ivan R. Schwab y Philip R.A. May por investigar y explicar por qué los pájaros carpinteros no sufren de dolor de cabeza.
· Paz: Howard Stapleton por inventar un repelente electromagnético de adolescentes, pero no adultos. Se trata de un artefacto que genera un sonido audible por los adolescentes pero no por adultos y que más tarde fue usado para convertirlo en un tono de teléfono que pueden oir los adolescentes pero no sus profesores.
· Acústica: D. Lynn Halpern y Randolph Blake por sus experimentos acerca de por qué a la gente le desagrada el ruido de las uñas arañando una pizarra.
· Medicina: Francis M. Fesmire, por su informe "Interrupción del hipo con un masaje rectal dactilar".
· Biología: Bart Knols y Ruurd de Jong, por mostrar que el mosquito Anofeles femenino, que transmite la malaria, se ve tan atraído por queso limburger como por el olor de los pies humanos.
· Matemática: Nic Svensons y Pier Barnes por calcular el número de fotografías que hay que tomar a un grupo para asegurar que todos los que posan aparecerán con los ojos abiertos en la imagen.
Fuente: Wikipedia
sábado, octubre 28, 2006
Guía del Lenguaje Perl – 4ta parte
Arreglos Asociativos
Se caracterizan por que se puede definir cualquier tipo de dato escalar como índice. El caracter $ se utiliza para refererirse a un elemento escalar y el caracter % para todos. Para asignar valores a un arreglo asociativo, se utilizan las llaves ({ }) alrededor de la clave de índice. Para referirse a un arreglo asociativo en su totalidad, se usa su nombre precedido del símbolo "%"; si por el contrario se desea acceder solamente a un elemento se usa el nombre del arreglo anteponiendo el símbolo "$". Si lo que se quiere es manipular las llaves o los valores se usa el símbolo "@" antes del nombre.
Sobre los arreglos asociativos se se realizan tres operaciones principales:
- obtener el valor asociado a una clave
- cambiar el valor asociado a una clave.
- verificar si una clave existe.
En el siguiente ejemplo se define un arreglo asociativo llamado stock con sus pares de clave-valor,
%stock = (limones => 6, peras => 3, uvas => 2);
A la estructura anterior se le pueden agregar ó modificar pares clave-valor de la siguiente forma
$stock{peras} = 9;
$stock{bananas} = 4;
Una forma de crear un arreglo asociativo es a partir de pares de datos clave-valor leidos de un archivo
Ejemplo:
open FILE, "frutas.txt" or die(“Error $!”);
while ([FILE]){
$linea = chomp($_); se elimina el fin de linea
@tmp = split(/\t/); # se separa el registo en campos
# (el tabulador es el delimitador)
$stock{$tmp[0]} = $tmp[1]; # se asigna par clave-valor
}
close FILE or die(“Error $!”);
Un par clave-valor se borra con
delete $stock{uvas};
Un arreglo completo se borra
undef %stock;
Para eliminar todas los pares claves-valor, pero no la estructura, se utiliza
%stock = ();
Para navegar una estructura se pueden utilizar varias formas. La instruccion foreach
permite recorrer la estructura de forma completa. La variable $clave se instancia con el valor de la clave.
foreach $clave (keys %stock) {
print "$clave = $stock{$clave}\n";
}
También con el elemento map, es posible listar las claves.
print map "$_ = $stock{$_}\n", keys %stock;
Se puede utilizar while y each para leer una arreglo asociativo
while (($key,$valor) = each %stock){ print "$key = $valor\n"; }
La función keys crea un arreglo indexado con las claves de un arreglo asociativo
%a = ( x => 5, y => 3, z => 'abc' );
@b = keys %a # @b se instancia con ( 'x', 'y', 'z');
La función values devuelve un arreglo indexado con los valores de arreglo asociativo
%a = ( x => 5, y => 3, z => 'abc' );
@v = values %a # @v se instancia con con ( 5, 3, 'abc' );
La función exists prueba si existe una clave en un arreglo asociativo
%a = ( x => 5, y => 3, z => 'abc' );
$b = exists $a{z}; # $b se instancia con 1, es verdadero
$c = exists $a{w}; # $c queda con "", es falso
Es posible ordenar una estructura. Para Perl existen tres formas: por orden ASCII, numericamente o alfabeticamente.
%hash = (Apples=>1, apples=>4, artichokes=>3,Beets=> 9,);
foreach my $key (sort keys %hash) { print "$key = $hash{$key}\n"; }
La salida será
Apples = 1
Beets = 9
apples = 4
artichokes = 3
A los efectos ordenar alfabéticamente se puede utilizar la función lc (convertir a minúsculas) y el operador de comparación cmp.
foreach my $key (sort {lc($a) cmp lc($b)} keys %hash) {
print "$key = $hash{$key}\n";
}
Se caracterizan por que se puede definir cualquier tipo de dato escalar como índice. El caracter $ se utiliza para refererirse a un elemento escalar y el caracter % para todos. Para asignar valores a un arreglo asociativo, se utilizan las llaves ({ }) alrededor de la clave de índice. Para referirse a un arreglo asociativo en su totalidad, se usa su nombre precedido del símbolo "%"; si por el contrario se desea acceder solamente a un elemento se usa el nombre del arreglo anteponiendo el símbolo "$". Si lo que se quiere es manipular las llaves o los valores se usa el símbolo "@" antes del nombre.
Sobre los arreglos asociativos se se realizan tres operaciones principales:
- obtener el valor asociado a una clave
- cambiar el valor asociado a una clave.
- verificar si una clave existe.
En el siguiente ejemplo se define un arreglo asociativo llamado stock con sus pares de clave-valor,
%stock = (limones => 6, peras => 3, uvas => 2);
A la estructura anterior se le pueden agregar ó modificar pares clave-valor de la siguiente forma
$stock{peras} = 9;
$stock{bananas} = 4;
Una forma de crear un arreglo asociativo es a partir de pares de datos clave-valor leidos de un archivo
Ejemplo:
open FILE, "frutas.txt" or die(“Error $!”);
while ([FILE]){
$linea = chomp($_); se elimina el fin de linea
@tmp = split(/\t/); # se separa el registo en campos
# (el tabulador es el delimitador)
$stock{$tmp[0]} = $tmp[1]; # se asigna par clave-valor
}
close FILE or die(“Error $!”);
Un par clave-valor se borra con
delete $stock{uvas};
Un arreglo completo se borra
undef %stock;
Para eliminar todas los pares claves-valor, pero no la estructura, se utiliza
%stock = ();
Para navegar una estructura se pueden utilizar varias formas. La instruccion foreach
permite recorrer la estructura de forma completa. La variable $clave se instancia con el valor de la clave.
foreach $clave (keys %stock) {
print "$clave = $stock{$clave}\n";
}
También con el elemento map, es posible listar las claves.
print map "$_ = $stock{$_}\n", keys %stock;
Se puede utilizar while y each para leer una arreglo asociativo
while (($key,$valor) = each %stock){ print "$key = $valor\n"; }
La función keys crea un arreglo indexado con las claves de un arreglo asociativo
%a = ( x => 5, y => 3, z => 'abc' );
@b = keys %a # @b se instancia con ( 'x', 'y', 'z');
La función values devuelve un arreglo indexado con los valores de arreglo asociativo
%a = ( x => 5, y => 3, z => 'abc' );
@v = values %a # @v se instancia con con ( 5, 3, 'abc' );
La función exists prueba si existe una clave en un arreglo asociativo
%a = ( x => 5, y => 3, z => 'abc' );
$b = exists $a{z}; # $b se instancia con 1, es verdadero
$c = exists $a{w}; # $c queda con "", es falso
Es posible ordenar una estructura. Para Perl existen tres formas: por orden ASCII, numericamente o alfabeticamente.
%hash = (Apples=>1, apples=>4, artichokes=>3,Beets=> 9,);
foreach my $key (sort keys %hash) { print "$key = $hash{$key}\n"; }
La salida será
Apples = 1
Beets = 9
apples = 4
artichokes = 3
A los efectos ordenar alfabéticamente se puede utilizar la función lc (convertir a minúsculas) y el operador de comparación cmp.
foreach my $key (sort {lc($a) cmp lc($b)} keys %hash) {
print "$key = $hash{$key}\n";
}
viernes, octubre 27, 2006
Ediciones en línea de la revista USERS Linux con acceso público
En Maldita Internet se ha anunciado que la revista argentina Users Linux ha publicado en la web la colección perteneciente a su primer año para acceso gratuito (bajo licencia Creative Commons Atribución-No Comercial) por parte de los internautas. Grande la gente de MP Ediciones.
jueves, octubre 26, 2006
Turismo y motores de consulta. ¿Cómo buscan los usuarios?.
“Real Users, Real Trips, and Real Queries: An Analysis of Destination Search on a Search Engine” es un trabajo de investigación de Pang y Litvin. El mismo está en la línea de las investigaciones de la doctora Spink, donde el objetivo es comprender las necesidades y motivaciones de búsqueda de los usuarios a partir del estudio de sesiones frente a motores de consulta.
En este trabajo, Pang enfoca su estudio hacía el mercado del turismo, trata de comprender como los usuarios buscan información relevante sobre productos turísticos y planifican sus viajes. Se analizan los términos frecuentes utilizados en las consultas al servicio Excite en el año 2002. Del estudio se desprenden las siguientes observaciones: a) las consultas de turismo o viajes en promedio usan 3 palabras, b) 2. Cada sesión tiene un promedio de 3 consulta, c).Los usuarios, en este tipo de sesiones de búsqueda, visualizan un promedio de 2,1 páginas por búsqueda y d) El nombre de las ciudades es un término recurrente en tales consultas (representó el 46,4% de las búsquedas).

Gracias por el dato Ojo Buscador
En este trabajo, Pang enfoca su estudio hacía el mercado del turismo, trata de comprender como los usuarios buscan información relevante sobre productos turísticos y planifican sus viajes. Se analizan los términos frecuentes utilizados en las consultas al servicio Excite en el año 2002. Del estudio se desprenden las siguientes observaciones: a) las consultas de turismo o viajes en promedio usan 3 palabras, b) 2. Cada sesión tiene un promedio de 3 consulta, c).Los usuarios, en este tipo de sesiones de búsqueda, visualizan un promedio de 2,1 páginas por búsqueda y d) El nombre de las ciudades es un término recurrente en tales consultas (representó el 46,4% de las búsquedas).
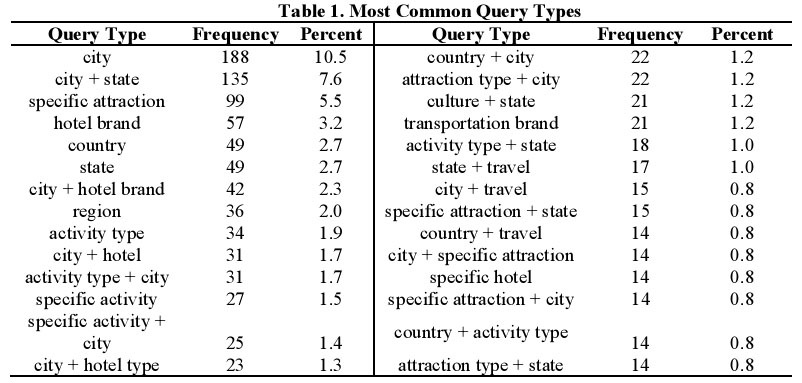
Gracias por el dato Ojo Buscador
Visual PageRank
Visual PageRank es una herramienta que a partir de una URL ingresada por el usuario devuelve una página donde se muestran todos los enlaces externos de la URL original con su valor de pagerank asociado.
martes, octubre 24, 2006
El 45% de las páginas web en español tienen su origen en España
Extracto de noticia de Reuters, publicada hoy por el Pais de Madrid
El 45% de las páginas web en español tienen su origen en España
En la actualidad más de 438 millones de personas hablan español en todo el mundo, pero en Internet sólo hay 82 millones de webs en este idioma, el 45% de ellas creadas en España. Expertos reunidos en un acto de la Fundación Telefónica celebrado en Montevideo (Uruguay) afirman que para mejorar esta situación hay que incidir sobre las condiciones económicas y técnicas de acceso a Internet, y animar la producción de contenidos...
Lo que no queda claro es si "webs" llaman a páginas o sitios.
El 45% de las páginas web en español tienen su origen en España
En la actualidad más de 438 millones de personas hablan español en todo el mundo, pero en Internet sólo hay 82 millones de webs en este idioma, el 45% de ellas creadas en España. Expertos reunidos en un acto de la Fundación Telefónica celebrado en Montevideo (Uruguay) afirman que para mejorar esta situación hay que incidir sobre las condiciones económicas y técnicas de acceso a Internet, y animar la producción de contenidos...
Lo que no queda claro es si "webs" llaman a páginas o sitios.
Nuevo servicio: Yahoo search audio
Si como ya sabemos Yahoo nos tiene acostumbrados a incorporar periodicamente nuevos servicios. En este caso presentó un buscador especializado en archivos de audio llamado "Yahoo Search Audio".
El servicio ofrece varios filtros para refinar la búsqueda, tales como tipo de formato, duración, fuente, tipo de audio (podcast, tema musical, otros). Además la parte de la base de datos que tiene que ver con clips musicales está organizada con buenos metadatos que permiten una navegación alternativa por ellos.
El servicio ofrece varios filtros para refinar la búsqueda, tales como tipo de formato, duración, fuente, tipo de audio (podcast, tema musical, otros). Además la parte de la base de datos que tiene que ver con clips musicales está organizada con buenos metadatos que permiten una navegación alternativa por ellos.
lunes, octubre 23, 2006
Social Information Retrieval
El concepto “recuperación social de información” se refiere a un conjunto de técnicas que ayudan a los usuarios obtener información relevante en base al análisis de experiencias de otros usuarios o sugerencias realizadas por estos. Ejemplos: social bookmarking (marcadores sociales), etiquetado (folksonomías), filtros colaborativos, sistemas de votos de noticias o de sugerencias, entre otros.
Les acerco una tesis de grado en Computer Science titulada “Social Information Retrieval” realizada por Sebastian Marius Kirsch. EL tema presentado es innovador desde el punto de vista seleccionado. Les copio su resumen:
“In this diploma thesis, we research whether the inclusion of information about an information user’s social environment and his position in the social network of his peers leads to an improval in search effectiveness.
Traditional information retrieval methods fail to address the fact that information production and consumption are social activities. We ameliorate this problem by extending the domain model of information retrieval to include social networks.
We describe two different techniques for information retrieval in such an enviroment. We evaluate these techniques in comparison to vector space retrieval.”
Les acerco una tesis de grado en Computer Science titulada “Social Information Retrieval” realizada por Sebastian Marius Kirsch. EL tema presentado es innovador desde el punto de vista seleccionado. Les copio su resumen:
“In this diploma thesis, we research whether the inclusion of information about an information user’s social environment and his position in the social network of his peers leads to an improval in search effectiveness.
Traditional information retrieval methods fail to address the fact that information production and consumption are social activities. We ameliorate this problem by extending the domain model of information retrieval to include social networks.
We describe two different techniques for information retrieval in such an enviroment. We evaluate these techniques in comparison to vector space retrieval.”
Matemática estás ahí? Libro de divulgación disponible para descargar
Gracias a la gente de Barrapunto me enteré que el profesor/matemático/periodista/conductor/buen tipo Adrián Paenza ha puesto a disposición de quien quiera su libro Matemática estás ahí?. El cual es una buena lectura, a modo de divulgación, para que los jóvenes entiendan “la belleza” de esta herramienta del hombre.
Grande Adrián, que el ejemplo toque a algunos otros!!!
Grande Adrián, que el ejemplo toque a algunos otros!!!
sábado, octubre 21, 2006
Datos acerca del alcance del correo basura
En estos días, en la UNLu, estamos poniendo a punto DSPAM el cual es un software de control corporativo de correo basura. Por tener una dirección de correo que ya tiene 10 años, en general, todo lo que anda dando vueltas viene a mi cuenta (la cual sirve como materia prima de primera mano para alimentar al soft con ejemplos positivos). Hace tiempo me di cuenta que este problema es gravísimo dado que creo que el recurso más costoso que consume es el tiempo de humanos para separar los útil de lo inútil.
Me dediqué a buscar datos sobre la magnitud de este problema y me encontré con un artículo de un tal Don Evett en el cual resume estadísticas, de distintas consultoras (Jupiter Research, eMarketer, Gartner,,entre otras) , del año 2006. Les copio los asombrosos números:


Me dediqué a buscar datos sobre la magnitud de este problema y me encontré con un artículo de un tal Don Evett en el cual resume estadísticas, de distintas consultoras (Jupiter Research, eMarketer, Gartner,,entre otras) , del año 2006. Les copio los asombrosos números:


Weblogs chinos: Cuando uno mira los números cae en la cuenta de lo grande que es.
En el país existen 34 millones (23 millones no se actualizaron el último mes) ) de autores de blogs y 75 millones de usuarios que los leen (sobre 123 millones de usuarios totales). La cantidad de usuarios con conexión tipo banda ancha es de 77 millones.. Con respecto a las costumbres foráneas, relacionadas con el consumo, el 40% de los autores de blogs ve con buenos ojos insertar publicidad en sus weblogs. Al 50% de los lectores no le molesta la publicidad en blogs. Fuente AsiaMedia
viernes, octubre 20, 2006
Off topic: Ayer conocí a Laura
Ayer conocí a laura y, en un ataque de individualismo, lloré.
Lloré por mi, por no poder hoy estar con ella.
Lloré por que los hombres, quienes sin justicia, se la llevaron.
Luego, en un instante de alegría, volví a llorar
al saber que su memoria sigue viva,
y que su madre Estela es nuestra guía.
Escrito dedicado a Laura y su madre Estela a quien tuve el placer de conocer ayer.
Lloré por mi, por no poder hoy estar con ella.
Lloré por que los hombres, quienes sin justicia, se la llevaron.
Luego, en un instante de alegría, volví a llorar
al saber que su memoria sigue viva,
y que su madre Estela es nuestra guía.
Escrito dedicado a Laura y su madre Estela a quien tuve el placer de conocer ayer.
jueves, octubre 19, 2006
Proyecto Citizendium una alternativa a la Wikipedia
Larry Sanger , uno de los creadores Wikipedia, en los próximos días presentará el sistema Citizendium, el cual se presenta como una evolución de la Wikipedia; la cual tratará de que tratará de resolver los aspectos más criticados de su desarrollo original (confiabilidad de los contenidos, disputas extremas, vandalismo, entre otros).
Citizendium utilizará una nueva forma de incorporación de autores, los cuales dejarán de ser anónimos y se incorporará un sistema de recomendación para su selección. El proyecto se iniciará con los contenidos actuales de Wikipedia, y luego tomará su rumbo.
Citizendium utilizará una nueva forma de incorporación de autores, los cuales dejarán de ser anónimos y se incorporará un sistema de recomendación para su selección. El proyecto se iniciará con los contenidos actuales de Wikipedia, y luego tomará su rumbo.
Audio es español con la conferencia de Tim O´Reilly en España
En Euskadi Digital (´área conferencias) hay un enlace para escuchar en línea la conferencia de Tim O´Reilly sobre la Web 2.0 en el País Vasco.
miércoles, octubre 18, 2006
Off topic: Fuerte crecimiento de la demanda de informáticos en Argentina
Me siento orgulloso de publicar dos extractos de noticias, las cuales me han llegado del Boletín del Consejo Profesional de Ciencias Informáticas de la Provincia de Buenos Aires, las cuales están relacionaas con el crecimiento de la in dustria del soft y la urgente demanda de técnicos e ingenieros.
Ojalá la educación e instrucción pueda llegar a tiempo en todo el país, para que haya un crecimiento balanceado y los desarrollos regionales acompañen al de los grandes centros urbanos.
Semilleros informáticos en nuestro país
En la Argentina hay diez polos tecnológicos que colaboran en la promoción del software; se los conoce como semilleros informáticos. Se encuentran en Salta, Mendoza,Córdoba, Tandil, Buenos Aires, Gualeguaychú, Neuquén, Río Negro y Capital Federal.
La mayoría de las empresas de software que operan en la Argentina son de capitales nacionales, aunque la facturación grande proviene de compañías extranjeras, dado que el grueso de las operaciones se orienta al mercado externo.
Dos empresas del sector comprometieron su participación en la misión comercial que visitará México a fines de este mes, programada para incrementar las exportaciones a ese mercado.
Otra de las situaciones que se presentan son los profesionales argentinos contratados por capitales internacionales que trabajan desde acá, porque la diferencia monetaria hace más barata la mano de obra. El sueldo promedio del sector oscila los 3.000 pesos.
Se estima que sólo un 5% de los estudiantes universitarios del país estudia carreras de informática. En la Facultad de Informática de La Plata hay alrededor de 3.500 alumnos. Cada año ingresan 1.000 y se recibe uno de cada cuatro. El porcentaje de egresados varía según la situación económica del país. Cuando la crisis apremia y la gente necesita salir a trabajar para sobrevivir, esta carrera queda en un segundo plano. En el mejor de los casos, el estudiante se demora para terminarla o, directamente, la abandona. Hoy, el nivel de graduados está en la media de la Universidad. Es decir, el 25% de los
ingresantes. La carrera dura cinco años, pero casi todos la terminan en seis o más.
En alza: el software argentino genera más trabajo que la carne y la leche. Superó en un 50% a dos sectores históricos de la economía nacional. Además, triplicó a la industria automotriz y a la del calzado. También se dispararon las exportaciones: 300 millones, contra los 25 millones en 2000. Aseguran que el crecimiento es tan vertiginoso como desordenado
La generación de empleo de la industria del software triplicó a la automotriz y a la del calzado, superó en un 50% a la carne y leche y está cerca de la química (52 mil trabajadores). La afirmación corresponde al subsecretario de Comercio Internacional de la Nación, Luis Kreckler, sobre un dinámico sector de la economía que tiene más oferta laboral que recursos humanos disponibles. Es la industria sin chimeneas.
Con la mirada del funcionario coinciden en la Cámara de Empresas de Software y Servicios Informáticos (CESSI) y en el Laboratorio de Investigación y Formación en Informática Avanzada (LIFIA) de la UNLP, ante consultas puntuales de Hoy.
Dentro de las nuevas tecnologías se encuentra el software, que en la Argentina se está desarrollando en un proceso similar al de la India (actual líder mundial), y que da empleo a cerca de 50 mil personas, según datos oficiales. "Entre 2004 y 2005 este sector generó 20 mil nuevos puestos de trabajo", puntualizó Kreckler. Además, aporta ingresos en concepto de exportaciones.
"Recién tras la devaluación nos convertimos en un país exportador de software. Hoy el mercado atraviesa una etapa de explosión, tan desordenada como demandante", opina el especialista Gustavo Rossi, titular del LIFIA, un laboratorio que depende de la Facultad de Informática local. Para este doctor en informática, "los recursos humanos de Argentina están a la altura del mejor país del mundo. Cuenta con el potencial humano para transformarse en un país de punta
Argentina: La industria del software fomenta las carreras tecnológicas
Representantes de la industria informática y del Ministerio de Educación lanzaron ayer la segunda versión de la campaña para incentivar la inscripción de alumnos en las carreras universitarias de sistemas. Pese a que la industria tuvo un fenomenal desarrollo en los últimos años, el número de egresados e inscriptos en las carreras informáticas y afines no es suficiente para cubrir los puestos que las empresas
requieren. Actualmente, sólo un 5% de los estudiantes universitarios cursa carreras vinculadas con la tecnología.
"Generación IT", tal el nombre de la convocatoria conjunta entre el sector público y privado, demandará una inversión de $ 600.000 este año y 2 millones en 2007 para intentar superar a mediano y largo plazo el cuello de botella en cuanto a mano de obra calificada que atraviesa en estos momentos la industria.
El acto contó con la presencia del ministro de Educación, Daniel Filmus; del secretario de Políticas Universitarias del Ministerio de Educación, Alberto Dibbern, y de Carlos Pallotti, presidente de la cámara que agrupa a las empresas de software y servicios informáticos del país, Cessi.
Según las estadísticas del sector, la industria de desarrollo de software viene creciendo a un ritmo del 20% anual, en promedio, en los últimos tres años. En 2006 proyecta facturar $ 4800 millones, un 20% más que en 2005 y exportará por 300 millones. Actualmente, la industria de software emplea cerca de 50.000 profesionales. Además, ya hay trabajando 14.000 profesionales directamente para exportación de software.
En la página: www.generacionti.net se puede encontrar toda la oferta de carreras relacionadas (hay más de 60 en las universidades públicas del país). La página indica la duración, el lugar donde se cursa, así como detalles y otra información necesaria.
Ojalá la educación e instrucción pueda llegar a tiempo en todo el país, para que haya un crecimiento balanceado y los desarrollos regionales acompañen al de los grandes centros urbanos.
Semilleros informáticos en nuestro país
En la Argentina hay diez polos tecnológicos que colaboran en la promoción del software; se los conoce como semilleros informáticos. Se encuentran en Salta, Mendoza,Córdoba, Tandil, Buenos Aires, Gualeguaychú, Neuquén, Río Negro y Capital Federal.
La mayoría de las empresas de software que operan en la Argentina son de capitales nacionales, aunque la facturación grande proviene de compañías extranjeras, dado que el grueso de las operaciones se orienta al mercado externo.
Dos empresas del sector comprometieron su participación en la misión comercial que visitará México a fines de este mes, programada para incrementar las exportaciones a ese mercado.
Otra de las situaciones que se presentan son los profesionales argentinos contratados por capitales internacionales que trabajan desde acá, porque la diferencia monetaria hace más barata la mano de obra. El sueldo promedio del sector oscila los 3.000 pesos.
Se estima que sólo un 5% de los estudiantes universitarios del país estudia carreras de informática. En la Facultad de Informática de La Plata hay alrededor de 3.500 alumnos. Cada año ingresan 1.000 y se recibe uno de cada cuatro. El porcentaje de egresados varía según la situación económica del país. Cuando la crisis apremia y la gente necesita salir a trabajar para sobrevivir, esta carrera queda en un segundo plano. En el mejor de los casos, el estudiante se demora para terminarla o, directamente, la abandona. Hoy, el nivel de graduados está en la media de la Universidad. Es decir, el 25% de los
ingresantes. La carrera dura cinco años, pero casi todos la terminan en seis o más.
En alza: el software argentino genera más trabajo que la carne y la leche. Superó en un 50% a dos sectores históricos de la economía nacional. Además, triplicó a la industria automotriz y a la del calzado. También se dispararon las exportaciones: 300 millones, contra los 25 millones en 2000. Aseguran que el crecimiento es tan vertiginoso como desordenado
La generación de empleo de la industria del software triplicó a la automotriz y a la del calzado, superó en un 50% a la carne y leche y está cerca de la química (52 mil trabajadores). La afirmación corresponde al subsecretario de Comercio Internacional de la Nación, Luis Kreckler, sobre un dinámico sector de la economía que tiene más oferta laboral que recursos humanos disponibles. Es la industria sin chimeneas.
Con la mirada del funcionario coinciden en la Cámara de Empresas de Software y Servicios Informáticos (CESSI) y en el Laboratorio de Investigación y Formación en Informática Avanzada (LIFIA) de la UNLP, ante consultas puntuales de Hoy.
Dentro de las nuevas tecnologías se encuentra el software, que en la Argentina se está desarrollando en un proceso similar al de la India (actual líder mundial), y que da empleo a cerca de 50 mil personas, según datos oficiales. "Entre 2004 y 2005 este sector generó 20 mil nuevos puestos de trabajo", puntualizó Kreckler. Además, aporta ingresos en concepto de exportaciones.
"Recién tras la devaluación nos convertimos en un país exportador de software. Hoy el mercado atraviesa una etapa de explosión, tan desordenada como demandante", opina el especialista Gustavo Rossi, titular del LIFIA, un laboratorio que depende de la Facultad de Informática local. Para este doctor en informática, "los recursos humanos de Argentina están a la altura del mejor país del mundo. Cuenta con el potencial humano para transformarse en un país de punta
Argentina: La industria del software fomenta las carreras tecnológicas
Representantes de la industria informática y del Ministerio de Educación lanzaron ayer la segunda versión de la campaña para incentivar la inscripción de alumnos en las carreras universitarias de sistemas. Pese a que la industria tuvo un fenomenal desarrollo en los últimos años, el número de egresados e inscriptos en las carreras informáticas y afines no es suficiente para cubrir los puestos que las empresas
requieren. Actualmente, sólo un 5% de los estudiantes universitarios cursa carreras vinculadas con la tecnología.
"Generación IT", tal el nombre de la convocatoria conjunta entre el sector público y privado, demandará una inversión de $ 600.000 este año y 2 millones en 2007 para intentar superar a mediano y largo plazo el cuello de botella en cuanto a mano de obra calificada que atraviesa en estos momentos la industria.
El acto contó con la presencia del ministro de Educación, Daniel Filmus; del secretario de Políticas Universitarias del Ministerio de Educación, Alberto Dibbern, y de Carlos Pallotti, presidente de la cámara que agrupa a las empresas de software y servicios informáticos del país, Cessi.
Según las estadísticas del sector, la industria de desarrollo de software viene creciendo a un ritmo del 20% anual, en promedio, en los últimos tres años. En 2006 proyecta facturar $ 4800 millones, un 20% más que en 2005 y exportará por 300 millones. Actualmente, la industria de software emplea cerca de 50.000 profesionales. Además, ya hay trabajando 14.000 profesionales directamente para exportación de software.
En la página: www.generacionti.net se puede encontrar toda la oferta de carreras relacionadas (hay más de 60 en las universidades públicas del país). La página indica la duración, el lugar donde se cursa, así como detalles y otra información necesaria.
Hoy son las Jornadas Internet de Nueva Generación
La Catedrá Telefónica (no estoy de acuerdo con mezclar tan "marketineramente" lo académico con lo empresarial) de la Universidad Politécnica de Madrid hoy, miercoles 18, está llevando a cabo las Jornadas Internet de Nueva Generación. Pueden ver el programa de ponencias y algunas presentaciones.
martes, octubre 17, 2006
Conferencia Internacional sobre el futuro de los sistemas OPAC
En el mes de septiembre pasado, en Australia, se llevó a cabo la una reunión técnica de bibliotecarios donde se discutió el futuro de los sistemas de visualización de material digital OPAC. En una página de la Biblioteca Nacional de Australia se presentan las ponencias realizadas.
Entrevista a Ricardo Baeza Yates
En el blog de Yahoo está la transcripción de un chat con Ricardo baeza Yates, el Director de los Laboratoriode Investigación de Yahoo España y Chile.
Gracias Ojo Buscador
Gracias Ojo Buscador
lunes, octubre 16, 2006
Críticas al sistema tradicional de referato de artículos científicos
Quería sugerirles la lectura de un artículo del blog Tecnocidanos titulado "La crisis del peer review". En el documento se expone la crisis que está sufriendo el sistema tradicional que asegura la calidad en el avance de la ciencia. De forma normal el sistema de revisión de trabajos de investigación por pares académicos indica que todo resultado o estudio debe ser revisado por al menos dos colegas entendidos en el tema, para ser publicado. Del juicio de estos puede ser que se rechace el artículo o se acepte (con modificaciones o no). Esta, por años, ha sido la herramienta que ha asegurado que la ciencia avance sobre terrenos firmes. A partir de la empinada pendiente con que la tecnología a avanzado estos últimos años (biotecnología, comunicaciones, exploración del espacio, genética, entre otras áreas), para algunos, se visualiza una desactualización o falta de revisión del método de control de calidad de la ciencia, dado que básicamente los tiempos asociados a él son bastante grandes, comparados con el avance de la tecnología.
En Tiscar hay unos interesantes comentarios sobre el artículo original de opinión. Casi siempre la crítica pasa por a) el negocio de ciertas editoriales privadas de documentos científicos en cuanto a la supuesta manipulación, control o influencia sobre los académicos en sus decisiones y b) el tiempo del proceso de revisión, donde la crítica principal es que en una sociedad con los auxilios tecnológicos disponibles se siga tardando lo mismo que sin ellos.
En Wired Magazine, Adam Rogers escribió un artículo crítico al sistema clásico de publicación académica, en el cual explica que una buena forma de revisión por pares es haciendo visibles los artículos de investigación (y que los pares, con responsabilidad, puedan insertar junto a él sus comentarios, esta es mi opinión).
Del mismo artículo de Rogers, me llamó la atención la frase del editor de PLoS ONE (C. Surridge) "Peer review was brilliant when distribution was a problem and you had to be selective about what you could publish,...". Hoy con el estado de avance de la informática y las comunicaciones digitales, más los métodos de tratamiento automático de la información, hace que estamos en otro contexto distinto al de varios años atrás.
En Tiscar hay unos interesantes comentarios sobre el artículo original de opinión. Casi siempre la crítica pasa por a) el negocio de ciertas editoriales privadas de documentos científicos en cuanto a la supuesta manipulación, control o influencia sobre los académicos en sus decisiones y b) el tiempo del proceso de revisión, donde la crítica principal es que en una sociedad con los auxilios tecnológicos disponibles se siga tardando lo mismo que sin ellos.
En Wired Magazine, Adam Rogers escribió un artículo crítico al sistema clásico de publicación académica, en el cual explica que una buena forma de revisión por pares es haciendo visibles los artículos de investigación (y que los pares, con responsabilidad, puedan insertar junto a él sus comentarios, esta es mi opinión).
Del mismo artículo de Rogers, me llamó la atención la frase del editor de PLoS ONE (C. Surridge) "Peer review was brilliant when distribution was a problem and you had to be selective about what you could publish,...". Hoy con el estado de avance de la informática y las comunicaciones digitales, más los métodos de tratamiento automático de la información, hace que estamos en otro contexto distinto al de varios años atrás.
domingo, octubre 15, 2006
Off topic: Charles Bukowski, un poeta “maldito” y olvidado
Desde joven me cautivó, hasta diría que tuve adicción, a la lectura de Bukowski. Nunca supe la razón, ni tampoco me desvelé por hallarla. Capaz que es por la dureza de sus relatos, por ser un provocador persistente, por la temática marginal, por sus personajes, por ser la voz de los marginados o tal vez por esa bella morbosidad que lo caracterizó.

Para quienes no conozcan a este poeta maldito, adjetivo calificativo dado por los pares de su generación ( los cuales obviamente no lo entendieron -también hubo envidia- y lo agredieron), les presento algunas frases de él. Gracias Diarreas Diarias
- A veces me miro mis manos y me doy cuenta que podría haber sido un gran pianista o algo así. Pero, ¿Qué han hecho mis manos?. Rascarme las pelotas, firmar cheques, atar zapatos, tirar de la cadena de los inodoros, etc., etc. He desaprovechado mis manos. Y mi mente.
- El hombre ha nacido para morir.¿Qué quiere decir eso? Perder el tiempo y esperar. Esperar el colectivo. Esperar un par de tetas alguna noche de agosto en un cuarto de hotel en Las Vegas. Esperar que canten los ratones. Esperar que a las serpientes le crezcan alas. Perder el tiempo
- Me parece que la vida está totalmente desprovista de interés, y esto sucedía especialmente cuando trabajaba ocho horas por día. La mayor parte de los hombres trabajaban ocho horas al día, y tampoco ellos amaban la vida. No hay ninguna razón para amar la vida para alguien que trabaja ocho horas al día, porque es un derrotado.
- No era mi día. Ni mi semana, ni mi mes, ni mi año. Ni mi vida. ¡Maldita sea!
Dos escritos breves en los que se autoretrata, de yapa
Diálogo entre Henry Chinaski y el profesor Hamilton de “La senda del perdedor”
"- ¿Es usted el señor Chinaski?
Asentí con la cabeza.
- Llega usted con treinta minutos de retraso.
- Sí
- ¿Llegaría usted con treinta minutos de retraso a una boda o a un funeral?
- No
- ¿Por qué no? Si no le importa explicarnos …
- Bueno, si el funeral fuera el mío, tendría que ser puntual. Si la boda fuera la mía, sería mi funeral."
(Diálogo entre Henry Chinaski y el profesor Hamilton. La senda del perdedor, Charles Bukowski)
Lo haces mientras matas moscas
Bach, dije, tuvo 20 hijos.
apostaba a los caballos durante el día.
jodía durante la noche
y bebía en las mañanas.
en el medio escribía música.
al menos es lo que le dije
cuando ella me preguntó,
cuándo es que escribís?
Algunos links a su obra
La senda del perdedor
La máquina de follar
Cartero
Escritos de un viejo indecente
Se busca mujer
Abraza la oscuridad

Para quienes no conozcan a este poeta maldito, adjetivo calificativo dado por los pares de su generación ( los cuales obviamente no lo entendieron -también hubo envidia- y lo agredieron), les presento algunas frases de él. Gracias Diarreas Diarias
- A veces me miro mis manos y me doy cuenta que podría haber sido un gran pianista o algo así. Pero, ¿Qué han hecho mis manos?. Rascarme las pelotas, firmar cheques, atar zapatos, tirar de la cadena de los inodoros, etc., etc. He desaprovechado mis manos. Y mi mente.
- El hombre ha nacido para morir.¿Qué quiere decir eso? Perder el tiempo y esperar. Esperar el colectivo. Esperar un par de tetas alguna noche de agosto en un cuarto de hotel en Las Vegas. Esperar que canten los ratones. Esperar que a las serpientes le crezcan alas. Perder el tiempo
- Me parece que la vida está totalmente desprovista de interés, y esto sucedía especialmente cuando trabajaba ocho horas por día. La mayor parte de los hombres trabajaban ocho horas al día, y tampoco ellos amaban la vida. No hay ninguna razón para amar la vida para alguien que trabaja ocho horas al día, porque es un derrotado.
- No era mi día. Ni mi semana, ni mi mes, ni mi año. Ni mi vida. ¡Maldita sea!
Dos escritos breves en los que se autoretrata, de yapa
Diálogo entre Henry Chinaski y el profesor Hamilton de “La senda del perdedor”
"- ¿Es usted el señor Chinaski?
Asentí con la cabeza.
- Llega usted con treinta minutos de retraso.
- Sí
- ¿Llegaría usted con treinta minutos de retraso a una boda o a un funeral?
- No
- ¿Por qué no? Si no le importa explicarnos …
- Bueno, si el funeral fuera el mío, tendría que ser puntual. Si la boda fuera la mía, sería mi funeral."
(Diálogo entre Henry Chinaski y el profesor Hamilton. La senda del perdedor, Charles Bukowski)
Lo haces mientras matas moscas
Bach, dije, tuvo 20 hijos.
apostaba a los caballos durante el día.
jodía durante la noche
y bebía en las mañanas.
en el medio escribía música.
al menos es lo que le dije
cuando ella me preguntó,
cuándo es que escribís?
Algunos links a su obra
La senda del perdedor
La máquina de follar
Cartero
Escritos de un viejo indecente
Se busca mujer
Abraza la oscuridad
viernes, octubre 13, 2006
Como Realizar Búsquedas en Texto Completo (Full-Text Search) en MySQL
Les presento un documento didáctico, realizado por investigadores (Pablo Lavallén y Gabriel H. Tolosa) de nuestro Laboratorio de Redes en la UNLu, el cual explica como utilizar las funciones relacionadas con la recuperación de información (information retrieval) que ofrece el motor de base de datos MySQl. Lo bueno del documento es que hay un poco de código Perl que ejemplifica el acceso a la BD y el uso de las capacidades mencionadas.
Datos sobre uso de Internet en la India
En el blog Read/Write Webse ha publicado una entrada en la cual se brindan datos acerca del estado de Internet en la República de la India.
El número actual de usuarios se estima que etsá entre los 45 y 50 millones. Lo cual convierte al país en el cuarto a nivel mundial en cantidad de internautas. Pero comparando tales números con la población total se ve que solamente el 4.5% está directamente relacionada con la sociedad de la información.
El número actual de usuarios se estima que etsá entre los 45 y 50 millones. Lo cual convierte al país en el cuarto a nivel mundial en cantidad de internautas. Pero comparando tales números con la población total se ve que solamente el 4.5% está directamente relacionada con la sociedad de la información.
jueves, octubre 12, 2006
Off topic: Regalale a tu hijo un pinguinito de papel
Por que no le regalás a tu hijo un pinguinito en papel. Dale, tomate cinco minutos y hacelo, aca te explican como.
Como todo sabemos este animalito es ícono de ideas, estilos de vida y principios, pero miren hasta donde ha llegado el temor de lo que representa.

No, con el pinguno no se metan!!!
Como todo sabemos este animalito es ícono de ideas, estilos de vida y principios, pero miren hasta donde ha llegado el temor de lo que representa.

No, con el pinguno no se metan!!!
miércoles, octubre 11, 2006
Si Dios quiere estaremos presentes en CACIC 2006
En pocos días, en San Luis Argentina, se realizará el Congreso Argentino de Ciencias de la Computación CACIC 2006. Este es el evento académico más importante en informática, dado que la mayoría de las Universidades Argentinas se dan cita para exponer y debatir sus trabajos.
Este año contribuiremos, desde el Laboratorio de Redes de Datos de la UNLu, con un trabajo en el cual caracterizamos y comparamos las webs educativas de varios paises de la región. El trabajo se titula "Characterization of South American Educational Web Domains" y me tiene por autor junto al Prof. Gabriel Tolosa. Les copio el resumen a continuación:
"El presente trabajo tiene por objetivo caracterizar los espacios webs educativos de Argentina, Bolivia, Chile, Paraguay, Peru y Uruguay. Se realizó la recolección de una muestra de los distintos espacios de información utilizando un herramienta de recolección automática. Luego, se analizaron aspectos de cada dominio en lo referido a contenidos, enlaces y tecnologías utilizadas, de manera de poder establecer similitudes y diferencias en cuanto a los parámetros más representativos.
Del estudio surgen las siguientes observaciones: a) la cantidad de contenidos de todos los países participantes del estudio se ha incrementado considerablemente el último año, b) es necesario que las páginas de los dominios educativos tengan una mayor visibilidad, especialmente entre sus pares. Se ha encontrado para todos los países un importante porcentaje de páginas con grado entrante igual a cero y c) Aún falta incorporar tecnología que permita administrar páginas dinámicas en las instituciones educativas."
Esperemos que lleguen los fondos para viajar y exponerlo. Por si están interesados aqui tienen el programa de ponencias del martes, miércoles, jueves y viernes.
Este año contribuiremos, desde el Laboratorio de Redes de Datos de la UNLu, con un trabajo en el cual caracterizamos y comparamos las webs educativas de varios paises de la región. El trabajo se titula "Characterization of South American Educational Web Domains" y me tiene por autor junto al Prof. Gabriel Tolosa. Les copio el resumen a continuación:
"El presente trabajo tiene por objetivo caracterizar los espacios webs educativos de Argentina, Bolivia, Chile, Paraguay, Peru y Uruguay. Se realizó la recolección de una muestra de los distintos espacios de información utilizando un herramienta de recolección automática. Luego, se analizaron aspectos de cada dominio en lo referido a contenidos, enlaces y tecnologías utilizadas, de manera de poder establecer similitudes y diferencias en cuanto a los parámetros más representativos.
Del estudio surgen las siguientes observaciones: a) la cantidad de contenidos de todos los países participantes del estudio se ha incrementado considerablemente el último año, b) es necesario que las páginas de los dominios educativos tengan una mayor visibilidad, especialmente entre sus pares. Se ha encontrado para todos los países un importante porcentaje de páginas con grado entrante igual a cero y c) Aún falta incorporar tecnología que permita administrar páginas dinámicas en las instituciones educativas."
Esperemos que lleguen los fondos para viajar y exponerlo. Por si están interesados aqui tienen el programa de ponencias del martes, miércoles, jueves y viernes.
Libro (Creative Commons) "El Ecosistema Digital"
De casualidad me he encontrado con un libro digital (licencia Creative Commons, financiado por la Universidad de Valencia y editado por Guillermo Lopez García, que se titula "El Ecosistema Digital" . El trabajo, publicado en el 2005, aborda la temática de Internet y la comunicación interpersonal, desde la óptica de investigadores universitarios a través de quince artículos de reflexión. EL documento se divide en tres bloques conceptuales: "Modelos", "Nuevos medios" y "El Público".
Algunos capítulos que me han interesado son:
Los weblogs como herramienta didáctica en el seno de una asignatura curricular. Sonia Blanco.
La interactividad como aliada del público: estímulo democrático y nuevos retos para la participación en los medios digitales. Ainara Larrondo Ureta.
La censura de los productos culturales. Retos del control ideológico de la industria ante la digitalización. Manuel de la Fuente Soler.
Algunos capítulos que me han interesado son:
Los weblogs como herramienta didáctica en el seno de una asignatura curricular. Sonia Blanco.
La interactividad como aliada del público: estímulo democrático y nuevos retos para la participación en los medios digitales. Ainara Larrondo Ureta.
La censura de los productos culturales. Retos del control ideológico de la industria ante la digitalización. Manuel de la Fuente Soler.
martes, octubre 10, 2006
Google permitiría que los usuarios definan sus espacios de búsqueda
Google permitiría que los usuarios definan sus espacios de búsqueda
Corre el rumor que Google estaría desarrollando un nuevo servicio similar a Yahoo Search Builder y a Rollyo en el aspecto que permitiría a los usuarios definir "buscadores virtuales". Esa decir que un usuario podría definir un nuevo buscador que indexe solamente un dominio de interés especificado por él. Esto tiene que ver con el concepto de buscadores especializados o verticales los cuales apuntan a una mayor precisión en su juego de respuestas.
Corre el rumor que Google estaría desarrollando un nuevo servicio similar a Yahoo Search Builder y a Rollyo en el aspecto que permitiría a los usuarios definir "buscadores virtuales". Esa decir que un usuario podría definir un nuevo buscador que indexe solamente un dominio de interés especificado por él. Esto tiene que ver con el concepto de buscadores especializados o verticales los cuales apuntan a una mayor precisión en su juego de respuestas.
Guía del Lenguaje Perl - 3ra parte
Pilas y colas con arreglos
La función shift extrae el 1er elemento de un arreglo y ademas lo elimina. La función pop extrae el último elemento de un arreglo y lo elimina. Por otro lado existen las funciones unshift y push que realizan lo inverso respectivamente. Unshift agrega un elemento o una lista de elementos al comienzo de una lista y push hace lo mismo, pero al final de la lista.
Ejemplo:
#!/usr/local/bin/perl
@a = ('a'..'e');
$b = shift(@a); # $b se instancia con 'a'
for ($n=0; $n<@a; $n++) {print $a[$n].” “}; print “\n”;
# Se imprimen los valores b, c, d y e
@a = ('a'..'e');
$b = pop(@a); # $b se instancia con 'e'
for ($n=0; $n<@a; $n++) {print $b[$a].” “}; print “\n”;
# Se imprimen los valores a, b, c y d
unshift(@a, 1); # agrega 1 al principio del arreglo
push(@a, 999); # agrega 999 al final del arreglo
for ($n=0; $n<@a; $n++) {print $b[$a].” “}; print “\n”;
Con las funciones descriptas es posible construir una estructura de datos denominada pila (stack); se caracteriza por que su acceso es LIFO, (last input first output) es decir que el último elemento añadido es el primero en ser leido, para lo cual se utiliza la función shift para extraer y la función unshift para insertar.
Toda estructura de datos llamada cola opera en modo FIFO (First Input First Output), donde el primer elemento en ingresar es el primer elemento en salir. Por ejemplo, se podría implementar una cola leyendo con shift y agregando con push. Alternativamente se podría leer con la función pop, y agregar con unshift.
A continuación se muestran invertidos una lista de números ingresados por teclado
Ejemplo:
#!/usr/local/bin/perl
@pila = (); # se crea la pila
print "Ingrese una lista de números [terminar con –1] ";
$numero = [STDIN]; # reemplazar llaves por símbolos menor y mayor
while ($numero != -1) {
unshift(@pila,$numero); # se agrega un elemento a la pila
$numero = [STDIN]; # reemplazar llaves por símbolos menor y mayor
}
$l = @pila;
for($i=1; $i<= $l; $i++) { print shift(@pila) }; # se extrae elemento de la pila
La función shift extrae el 1er elemento de un arreglo y ademas lo elimina. La función pop extrae el último elemento de un arreglo y lo elimina. Por otro lado existen las funciones unshift y push que realizan lo inverso respectivamente. Unshift agrega un elemento o una lista de elementos al comienzo de una lista y push hace lo mismo, pero al final de la lista.
Ejemplo:
#!/usr/local/bin/perl
@a = ('a'..'e');
$b = shift(@a); # $b se instancia con 'a'
for ($n=0; $n<@a; $n++) {print $a[$n].” “}; print “\n”;
# Se imprimen los valores b, c, d y e
@a = ('a'..'e');
$b = pop(@a); # $b se instancia con 'e'
for ($n=0; $n<@a; $n++) {print $b[$a].” “}; print “\n”;
# Se imprimen los valores a, b, c y d
unshift(@a, 1); # agrega 1 al principio del arreglo
push(@a, 999); # agrega 999 al final del arreglo
for ($n=0; $n<@a; $n++) {print $b[$a].” “}; print “\n”;
Con las funciones descriptas es posible construir una estructura de datos denominada pila (stack); se caracteriza por que su acceso es LIFO, (last input first output) es decir que el último elemento añadido es el primero en ser leido, para lo cual se utiliza la función shift para extraer y la función unshift para insertar.
Toda estructura de datos llamada cola opera en modo FIFO (First Input First Output), donde el primer elemento en ingresar es el primer elemento en salir. Por ejemplo, se podría implementar una cola leyendo con shift y agregando con push. Alternativamente se podría leer con la función pop, y agregar con unshift.
A continuación se muestran invertidos una lista de números ingresados por teclado
Ejemplo:
#!/usr/local/bin/perl
@pila = (); # se crea la pila
print "Ingrese una lista de números [terminar con –1] ";
$numero = [STDIN]; # reemplazar llaves por símbolos menor y mayor
while ($numero != -1) {
unshift(@pila,$numero); # se agrega un elemento a la pila
$numero = [STDIN]; # reemplazar llaves por símbolos menor y mayor
}
$l = @pila;
for($i=1; $i<= $l; $i++) { print shift(@pila) }; # se extrae elemento de la pila
lunes, octubre 09, 2006
Revista: Visualización de información
Según los autores de la revista “InfoVis.net es un proyecto dedicado a la Visualización de la Información, entendida como el proceso de interiorización del conocimiento mediante la percepción de información, preferentemente (pero no sólo) de forma visual”.
En su índice se pueden hallar artículos de una amplia gama de temas, como ser: espacio web y su visualización, presentaciones multimedia, gráficos comerciales, tecnología de interfase de usuario, entre otros.
Artículos relacionados con IR
Minería web http://www.infovis.net/printMag.php?num=172&lang=1
Visualización del Contenido de la Web http://www.infovis.net/printMag.php?num=175&lang=1
Visualización de la Estructura de la Web http://www.infovis.net/printMag.php?num=173&lang=1
Filtraje Cooperativo http://www.infovis.net/printMag.php?num=155&lang=1
Mira la blogosfera http://www.infovis.net/printMag.php?num=140&lang=1
Visualización de redes sociales http://www.infovis.net/printMag.php?num=136&lang=1
En su índice se pueden hallar artículos de una amplia gama de temas, como ser: espacio web y su visualización, presentaciones multimedia, gráficos comerciales, tecnología de interfase de usuario, entre otros.
Artículos relacionados con IR
Minería web http://www.infovis.net/printMag.php?num=172&lang=1
Visualización del Contenido de la Web http://www.infovis.net/printMag.php?num=175&lang=1
Visualización de la Estructura de la Web http://www.infovis.net/printMag.php?num=173&lang=1
Filtraje Cooperativo http://www.infovis.net/printMag.php?num=155&lang=1
Mira la blogosfera http://www.infovis.net/printMag.php?num=140&lang=1
Visualización de redes sociales http://www.infovis.net/printMag.php?num=136&lang=1
Off Topic: Generador de discursos presidenciales
No será tecnología NLP pero se está cerca, BUSHSPEECH es un soft que permite crear discursos, el usuario puede armar un guión y dárselo al Sr. Bush (“Bush push” diría el negrito Fontova) para que lo interprete. ¿Alguien habrá hecho algo así con De La Rúa y nosotros no nos dimos cuenta que no era original?. Gracias por el dato Julián Gallo.
domingo, octubre 08, 2006
Honestidad académica II
En una entrada anterior ] aconsejé la lectura de un artículo relacionado con la honestidad académica. Siguiendo tal línea no se pierdan la presentación realizada por Mario Nuñez, autor del mencionado artículo, es muy buena y esclarecedora.
PD: No solamente los alumnos realizan estas prácticas, miren lo que le pasó al Ministro de Educación de Korea cuando reutilizó texto, indebidamente, en 1987.
PD: No solamente los alumnos realizan estas prácticas, miren lo que le pasó al Ministro de Educación de Korea cuando reutilizó texto, indebidamente, en 1987.
Cursando information retrieval con los grandes
Les gustaría tomar un curso con material prepararado exclusivamente por grandes investigadores de IR? Bueno, en caso que quieran les recomiendo ir a la página del cronograma de clases de la asignatura "SIMS 141: Search Engines: Technology, Society, and Business", la cual es dirigida por el profesor Marti Hearst. Agunos colaboradores son Jan Pedersen, John Battelle. Sue Dumais, Sergei Brin, Bradley Horowitz, entre otros. Lo bueno es que uno puede acceder a las exposiciones de esta gente vía podcasts.
Resumen sobre exposición de Tim O´Reilly
En el blog de Alianzo, José del Moral presenta un resumen de la conferencia que Tim O´Reilly titulada "Web 2.0. La empresa y el emprendedor ante la nueva internet", brindada en España (Vitoria) el 5 de octubre.
Gracias por el dato Pablo.
Gracias por el dato Pablo.
viernes, octubre 06, 2006
Off topic: Telemarketers, la venganza será terrible
He copiado, del blog de mi conocida Biopúritas, un texto cómico llamado "Protocolo de actuación anti-marketing telefónico". A ver si alguien lo pone en práctica y cuenta como salió.
Riiiing...riiiin...!
-.Hola?
-.Buenos días, ¿Usted es el titular de la línea?
- Sí, soy yo mismo
-.¿Me puede decir su nombre por favor?
- José Luis
-.Señor José Luis, le llamo de Telefónica para ofrecerle una promoción consistente en la instalación de una línea adicional en su casa, en donde usted tendrá derecho a...
- Disculpe la interrupción Señorita, pero, exactamente ¿quién es usted?
-Mi nombre es Silvina Maciel, de Telefónica y estamos llamando...
- Silvina, discúlpeme, pero para nuestra seguridad me gustaría comprobar algunos datos antes de continuar la conversación, ¿le importa?
- No tengo problemas señor
- ¿Desde que teléfono me llama? En la pantallita del mío solo pone "NUMERO PRIVADO"
- El interno mío es el 1004
- ¿Para qué departamento de Telefónica trabaja?
- Telemarketing Activo
- ¿Me podría dar el número de trabajadora de Telefónica?
- Señor, disculpe, pero creo que toda esa información no es necesaria...
- Entonces lamentablemente tendré que colgar, porque no tengo la seguridad de hablar con una trabajadora de Telefónica
- Pero yo le puedo garantizar...
- Vea Silvina, cada vez que yo llamo a Telefónica, antes de poder comenzar cualquier trámite, estoy obligado a dar mis datos a toda una legión de empleados...!
- Está bien Señor, mi numero es el 34591212
- Un momento mientras lo verifico, no se retire Silvina...
(Dos minutos)
- Un momento por favor, toda la gente en casa se encuentra ocupada....
(Cinco minutos)
- ¿Señor?
- Un momento por favor, toda la gente en casa se encuentra ocupada....
- Pero...Hola Señor...!
- Sí Silvina, gracias por la espera, nuestros sistemas están un poco lentos hoy... ¿Cual era el asunto de su llamada?
- Lo llamo de Telefónica, estamos llamando para ofrecerle nuestra promoción "Línea Adicional", en la que usted tiene derecho al uso de otra línea a muy bajo costo. ¿Usted estaría interesado José Luis?
- Silvina, le voy a comunicar con mi mujer, que es la encargada de la sección de adquisición de productos técnicos de la casa; por favor, no se retire.
(Coloco el auricular del teléfono delante de un grabador y pongo el CD de Caribe Mix 2004 con el Repeat activado. Sabía que algún día, esa droga de música me sería útil. Después de sonar el CD entero, mi mujer atiende el teléfono):
- Disculpe por la espera, me puede decir su teléfono pues en la pantallita del mío solo aparece "NUMERO PRIVADO".
- 1004
- Gracias, ¿Con quien estoy hablando?
- Con Silvina
- ¿Silvina que?
- Silvina Maciel (ya demostrando cierta irritación en la voz)
- ¿Cual es su número de trabajadora de Telefónica?
- 34591212 (mas irritada todavía)
- Gracias por la información Silvina, ¿en que puedo ayudarla?
- La llamo de Telefónica, estamos llamando para ofrecerle nuestra promoción "Línea Adicional", en la que usted tiene derecho a otra línea.¿Estaría interesada?
- Voy a ingresar su solicitud en nuestro programa de Nuevas Adquisiciones y dentro de algunos días nos contactamos con usted. ¿Puede anotar el número de ingreso al programa por favor?... ¿hola?, ¿hola?
- TU...TU...TU...TU...
Espectacular, espectacular, :-}
Riiiing...riiiin...!
-.Hola?
-.Buenos días, ¿Usted es el titular de la línea?
- Sí, soy yo mismo
-.¿Me puede decir su nombre por favor?
- José Luis
-.Señor José Luis, le llamo de Telefónica para ofrecerle una promoción consistente en la instalación de una línea adicional en su casa, en donde usted tendrá derecho a...
- Disculpe la interrupción Señorita, pero, exactamente ¿quién es usted?
-Mi nombre es Silvina Maciel, de Telefónica y estamos llamando...
- Silvina, discúlpeme, pero para nuestra seguridad me gustaría comprobar algunos datos antes de continuar la conversación, ¿le importa?
- No tengo problemas señor
- ¿Desde que teléfono me llama? En la pantallita del mío solo pone "NUMERO PRIVADO"
- El interno mío es el 1004
- ¿Para qué departamento de Telefónica trabaja?
- Telemarketing Activo
- ¿Me podría dar el número de trabajadora de Telefónica?
- Señor, disculpe, pero creo que toda esa información no es necesaria...
- Entonces lamentablemente tendré que colgar, porque no tengo la seguridad de hablar con una trabajadora de Telefónica
- Pero yo le puedo garantizar...
- Vea Silvina, cada vez que yo llamo a Telefónica, antes de poder comenzar cualquier trámite, estoy obligado a dar mis datos a toda una legión de empleados...!
- Está bien Señor, mi numero es el 34591212
- Un momento mientras lo verifico, no se retire Silvina...
(Dos minutos)
- Un momento por favor, toda la gente en casa se encuentra ocupada....
(Cinco minutos)
- ¿Señor?
- Un momento por favor, toda la gente en casa se encuentra ocupada....
- Pero...Hola Señor...!
- Sí Silvina, gracias por la espera, nuestros sistemas están un poco lentos hoy... ¿Cual era el asunto de su llamada?
- Lo llamo de Telefónica, estamos llamando para ofrecerle nuestra promoción "Línea Adicional", en la que usted tiene derecho al uso de otra línea a muy bajo costo. ¿Usted estaría interesado José Luis?
- Silvina, le voy a comunicar con mi mujer, que es la encargada de la sección de adquisición de productos técnicos de la casa; por favor, no se retire.
(Coloco el auricular del teléfono delante de un grabador y pongo el CD de Caribe Mix 2004 con el Repeat activado. Sabía que algún día, esa droga de música me sería útil. Después de sonar el CD entero, mi mujer atiende el teléfono):
- Disculpe por la espera, me puede decir su teléfono pues en la pantallita del mío solo aparece "NUMERO PRIVADO".
- 1004
- Gracias, ¿Con quien estoy hablando?
- Con Silvina
- ¿Silvina que?
- Silvina Maciel (ya demostrando cierta irritación en la voz)
- ¿Cual es su número de trabajadora de Telefónica?
- 34591212 (mas irritada todavía)
- Gracias por la información Silvina, ¿en que puedo ayudarla?
- La llamo de Telefónica, estamos llamando para ofrecerle nuestra promoción "Línea Adicional", en la que usted tiene derecho a otra línea.¿Estaría interesada?
- Voy a ingresar su solicitud en nuestro programa de Nuevas Adquisiciones y dentro de algunos días nos contactamos con usted. ¿Puede anotar el número de ingreso al programa por favor?... ¿hola?, ¿hola?
- TU...TU...TU...TU...
Espectacular, espectacular, :-}
jueves, octubre 05, 2006
Definición colectiva de blog
Nuestro Laboratorio de Redes de Datos está finalizando de procesar y analizar una encuesta a autores de blogs argentinos. Aprovecho esta entrada para agradecer a los más de 150 bloggers que respondieron a nuestro formulario en línea :-}.
Como un primer producto de información, derivado de este trabajo, quería presentar una nube de etiquetas (lease histograma de frecuencias en modo texto) con términos utilizado por los encuestados para caracterizar a los blogs (se pidió en cada caso que seleccionen tres términos).

Luego, analizando la semántica de las etiquetas y el espíritu de la herramienta, tratamos de articular una nueva definición social de este medio de comunicación, la cual dice que “un blog es un medio útil, práctico y fácil de expresión personal que a partir de la interacción permite que las personas se comuniquen, se diviertan, compartan ideas y opiniones en un ambiente informativo de total libertad”.
Saludos.
Como un primer producto de información, derivado de este trabajo, quería presentar una nube de etiquetas (lease histograma de frecuencias en modo texto) con términos utilizado por los encuestados para caracterizar a los blogs (se pidió en cada caso que seleccionen tres términos).

Luego, analizando la semántica de las etiquetas y el espíritu de la herramienta, tratamos de articular una nueva definición social de este medio de comunicación, la cual dice que “un blog es un medio útil, práctico y fácil de expresión personal que a partir de la interacción permite que las personas se comuniquen, se diviertan, compartan ideas y opiniones en un ambiente informativo de total libertad”.
Saludos.
Cuartas Jornadas de Bibliotecas Digitales Universitarias
La Universidad Nacional de Cuyo (Argentina), en este mes (19 y 20), realizará las Cuartas Jornadas de Bibliotecas Digitales Universitarias. Es un espacio de debate y actualización de
conocimientos sobre temas relacionados con el manejo de documentación
digital en instituciones de educación superior. Los temas a tratar son
los siguienets:
* Arquitectura en la web: Estructura de contenidos, visibilidad, enlaces y valuación.
* Mediciones en la web: Métodos y software. Usabilidad de sitios, servicios y recursos de información.
* Acceso temático en la web: Indización, Tesauros, Ontologías y Web semántica.
* Servicios y Capacitación de usuarios.
* Legislación y reglamentaciones.
Para mayor información aquí hallaran el programa.
conocimientos sobre temas relacionados con el manejo de documentación
digital en instituciones de educación superior. Los temas a tratar son
los siguienets:
* Arquitectura en la web: Estructura de contenidos, visibilidad, enlaces y valuación.
* Mediciones en la web: Métodos y software. Usabilidad de sitios, servicios y recursos de información.
* Acceso temático en la web: Indización, Tesauros, Ontologías y Web semántica.
* Servicios y Capacitación de usuarios.
* Legislación y reglamentaciones.
Para mayor información aquí hallaran el programa.
Tips "oficiales" sobre el algoritmo pagerank
Matt Cutts, ingeniero de Google, posee un blog. En el mismo, hay un artículo en el cual, a pedido de sus lectores, explica algunas características del algoritmo de posicionamiento pagerank.
Workshop en homenaje a un grande que sigue con nosotros
Que emoción, doble si doble, por un lado por el recuerdo del profesor que no está, y por otro, por que sus pares lo recuerden haciendo lo que el disfrutaba. Estoy hablando que en Chile, exactamente la semana del 6 de noviembre, se realizará el Workshop sobre Bases de Datos y la Web. La reunión será en honor a la memoria de Alberto Mendelzon.
Para aquellos estudiantes jovenes que no conocen a Mendelzon aquí presento una breve reseña de este gran argentino del mundo (el cual, como siempre, no lo supimos aprovechar -a pesar que lo formamos aquí-). Alberto fue investigador básico en el tema de las bases de datos relacionales; especialmente, contribuyó al conocimiento, con investigaciones teóricas. Se graduó en la UBA en 1973 y luego fue a perfeccionarse a con una beca a Princenton. Obtuvo sus postgrados un MSE y un PHD. Durante varios años trabajó en la Universidad de Toronto. Un documento emotivo, en el cual sus colegas lo recuerdan, se titula " In Memorian Alberto Oscar Mendelzon" (SIGMOD Record, V.34, N.4,2005) recomiendo su lectura ya sea para recordarlo o conocerlo.
Para aquellos estudiantes jovenes que no conocen a Mendelzon aquí presento una breve reseña de este gran argentino del mundo (el cual, como siempre, no lo supimos aprovechar -a pesar que lo formamos aquí-). Alberto fue investigador básico en el tema de las bases de datos relacionales; especialmente, contribuyó al conocimiento, con investigaciones teóricas. Se graduó en la UBA en 1973 y luego fue a perfeccionarse a con una beca a Princenton. Obtuvo sus postgrados un MSE y un PHD. Durante varios años trabajó en la Universidad de Toronto. Un documento emotivo, en el cual sus colegas lo recuerdan, se titula " In Memorian Alberto Oscar Mendelzon" (SIGMOD Record, V.34, N.4,2005) recomiendo su lectura ya sea para recordarlo o conocerlo.
miércoles, octubre 04, 2006
Gobby: editor de textos colaborativo.
A partir de una recomendación de Bulma descubrí el editor multiusuario colaborativo Gobby.
Como lo define su autor, Gobby es un editor gratuito colaborativo que soporta múltiples documentos y múltiples usuarios por sesión. Está basado en GTK+ y corre sobre plataformas OS X, Linux, *nix y Microsoft Windows.
Me pareció una herramienta robusta, la cual parece servir como soporte a trabajos colaborativos (la pude probar con un grupo muy reducido de usuarios). En un documento, cada usuario identifica su área de trabajo con un color distinto, las actualizaciones son transparentes (en mi caso parecía que estaba operando sobre una LAN). En definitiva, pienso que Gobby es un buen producto.
Como lo define su autor, Gobby es un editor gratuito colaborativo que soporta múltiples documentos y múltiples usuarios por sesión. Está basado en GTK+ y corre sobre plataformas OS X, Linux, *nix y Microsoft Windows.
Me pareció una herramienta robusta, la cual parece servir como soporte a trabajos colaborativos (la pude probar con un grupo muy reducido de usuarios). En un documento, cada usuario identifica su área de trabajo con un color distinto, las actualizaciones son transparentes (en mi caso parecía que estaba operando sobre una LAN). En definitiva, pienso que Gobby es un buen producto.
Podcasts de Conferencias Euskadi Digital
Este año, en el mes de julio, se realizaron las conferencias de Euskadi Digital. Como es su constumbre, grabaron las sesiones y están disponibles en archivos de sonido y presenntaciones multimedia. A mi, en particular, me interesaron las siguientes:
* Internet como red de redes. ¿Por dónde transita nuestro tráfico y por qué? Octavio Alfageme (Euskaltel)
* ¿Como sobrevivir sin MS Windows? GNU/Linux para no iniciados. Jon Valdés y Unai Aguilera
* Alta disponibilidad en GNU/Linux Israel Gayoso
* Tendencias en Desarrollo WEB (Mesa Redonda) Asier Gonzalez
* ¡Utiliza Software Libre en la empresa! Iker Castaños
* Haciendo un Podcast desde cero. Rafa Martínez - (Euskadi Digital)
* Estado actual del Modding (Mesa Redonda) Unai Martinez Corral (Opositivo), Lander Lopez Icedo (Neskin) y Luis Martinez Yenes (Mataclavos)
* VoIP: Telefonía tradicional, por internet. Rafa Martínez
* Internet como red de redes. ¿Por dónde transita nuestro tráfico y por qué? Octavio Alfageme (Euskaltel)
* ¿Como sobrevivir sin MS Windows? GNU/Linux para no iniciados. Jon Valdés y Unai Aguilera
* Alta disponibilidad en GNU/Linux Israel Gayoso
* Tendencias en Desarrollo WEB (Mesa Redonda) Asier Gonzalez
* ¡Utiliza Software Libre en la empresa! Iker Castaños
* Haciendo un Podcast desde cero. Rafa Martínez - (Euskadi Digital)
* Estado actual del Modding (Mesa Redonda) Unai Martinez Corral (Opositivo), Lander Lopez Icedo (Neskin) y Luis Martinez Yenes (Mataclavos)
* VoIP: Telefonía tradicional, por internet. Rafa Martínez
martes, octubre 03, 2006
off topìc: Que nos pasa, la tecnología nos está explotando en la cara?
No se si tendrá que ver con la pendiente de crecimiento de la tecnología, o con razones derivadas de la brecha digital, o tal vez, con un problema de paises ricos y paises pobres. Pero la realidad es la percepción del mundo que cada uno tiene, y en particular para mi la tecnología nos está explotando en la cara, no me creen miren aquí.
Saludos
Saludos
Juegos de datos (datasets) para experimentos de recuperación de información
Les paso algunas direcciones de datasets que son utilizados frecuentemente por la comunidad de investigadores de recuperación de información para realizar experimentos.
Chamaleon Orientado a pruebas de análisis de conglomerados
SMART Colección de distintos juegos de datos destinados a probar el sistema de recuperación de información SMART.
Medline Corpus de prueba de sistemas de recuperación de información ad-hocs. Es orientado a la medicina.
Reuters 21578, corpus destinado a evaluar sistemas de clasificación.
4-U Conjunto de 8.282 páginas web obtenidas de cuatro universidades y clasificadas por tipo de páqina.
Oshumed Colección de documentos médicos cuyo objetivo es evaluar SRIs.
20 NW 20 newsgroups datasets. Colección de 20.000 noticias destinada a evaluar técnicas de clasificación de documentos.
Glasgow Juegos de prueba para evaluar SRIs alojados en la Universidad de Gasglow
Web Spam Test Collections Colección de páginas web spam creada por Carlos Castillo.
Chamaleon Orientado a pruebas de análisis de conglomerados
SMART Colección de distintos juegos de datos destinados a probar el sistema de recuperación de información SMART.
Medline Corpus de prueba de sistemas de recuperación de información ad-hocs. Es orientado a la medicina.
Reuters 21578, corpus destinado a evaluar sistemas de clasificación.
4-U Conjunto de 8.282 páginas web obtenidas de cuatro universidades y clasificadas por tipo de páqina.
Oshumed Colección de documentos médicos cuyo objetivo es evaluar SRIs.
20 NW 20 newsgroups datasets. Colección de 20.000 noticias destinada a evaluar técnicas de clasificación de documentos.
Glasgow Juegos de prueba para evaluar SRIs alojados en la Universidad de Gasglow
Web Spam Test Collections Colección de páginas web spam creada por Carlos Castillo.
lunes, octubre 02, 2006
Universidades Latinoamericanas y las TICs
En el blog E-rgonomic bajo el título “Universidad, TICs, América Latina y Sociedad del Conocimiento, un círculo virtuoso” se presentan reflexiones del profesor Alejandro Rodríguez sobre el papel estratégico de las universidades en la sociedad del conocimiento.
3er Encuentro de weblogs en Portugal
En octubre 13 y 14 se realizará en la Universidade do Porto el 3er Encuentro de Weblogs. Ya se ha publicado el programa oficial con las presentaciones correspondientes. Esperemos que pronto publiquen las presentaciones y papers derivados del evento.
Suscribirse a:
Comentarios (Atom)

